Multi-Spectral Remote Sensing Image Retrieval Using Geospatial Foundation Models
2403.02059
0
0
Abstract
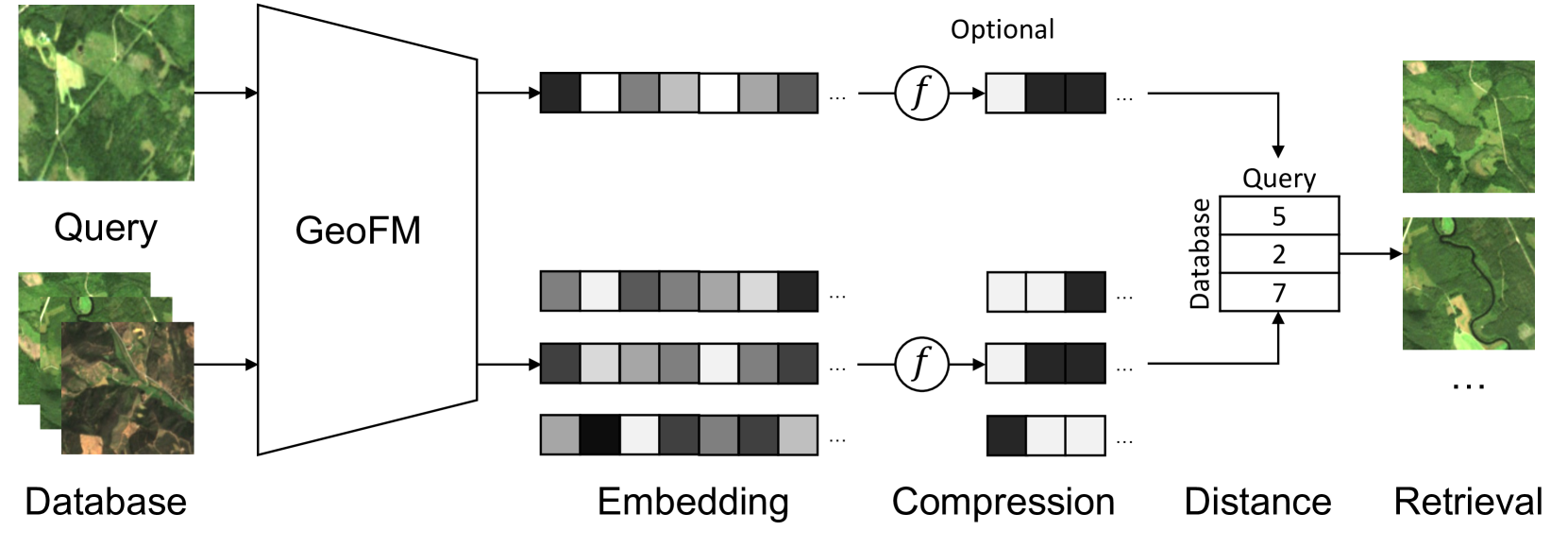
Image retrieval enables an efficient search through vast amounts of satellite imagery and returns similar images to a query. Deep learning models can identify images across various semantic concepts without the need for annotations. This work proposes to use Geospatial Foundation Models, like Prithvi, for remote sensing image retrieval with multiple benefits: i) the models encode multi-spectral satellite data and ii) generalize without further fine-tuning. We introduce two datasets to the retrieval task and observe a strong performance: Prithvi processes six bands and achieves a mean Average Precision of 97.62% on BigEarthNet-43 and 44.51% on ForestNet-12, outperforming other RGB-based models. Further, we evaluate three compression methods with binarized embeddings balancing retrieval speed and accuracy. They match the retrieval speed of much shorter hash codes while maintaining the same accuracy as floating-point embeddings but with a 32-fold compression. The code is available at https://github.com/IBM/remote-sensing-image-retrieval.
Create account to get full access
Overview
- This paper presents a method for retrieving multi-spectral remote sensing images using geospatial foundation models.
- The approach involves leveraging pre-trained language models to encode textual information and multi-spectral image data, enabling efficient retrieval of relevant images based on user queries.
- The authors evaluate their method on several remote sensing image datasets and demonstrate improved retrieval performance compared to traditional techniques.
Plain English Explanation
The paper describes a new way to search for and find specific remote sensing images, such as those captured by satellites or drones. Remote sensing images capture information about the Earth's surface using different wavelengths of light, like visible light and infrared. These images can be valuable for a variety of applications, like monitoring land use, detecting changes over time, or identifying natural resources.
The key idea in this paper is to use powerful language models that have been pre-trained on vast amounts of text data. These models can understand the meaning and context of words and phrases, allowing them to encode textual information in a compact and meaningful way. The researchers extend this idea to also encode the multi-spectral image data, creating a unified representation that captures both the visual and textual aspects of the remote sensing imagery.
By combining these encoded representations, the system can efficiently search through large databases of remote sensing images and quickly retrieve the ones that are most relevant to a user's textual query. This is an improvement over traditional approaches that may rely more on manual tags or simple visual similarity, which can be less effective for the complex and diverse remote sensing data.
The authors demonstrate the effectiveness of their approach by testing it on several real-world remote sensing image datasets, showing that it outperforms other state-of-the-art retrieval methods. This could be valuable for a range of applications, like classifying different types of geospatial objects from aerial imagery, generating remote sensing images from sketches, or identifying buildings in satellite images.
Technical Explanation
The authors propose a multi-modal retrieval system that combines geospatial foundation models with multi-spectral remote sensing imagery. They first encode the textual information and image data using separate neural network encoders, which are trained on large datasets to capture the underlying semantics and visual features, respectively.
For the textual encoding, the authors leverage pre-trained language models like BERT, which have been shown to be effective at understanding natural language. For the image encoding, they use a convolutional neural network architecture that can handle the multi-spectral nature of the remote sensing data.
The encoded textual and visual representations are then combined using a multimodal fusion module, allowing the system to jointly reason about the semantic and visual information. This enables efficient retrieval of relevant remote sensing images based on textual queries, outperforming traditional techniques that rely more on manual tags or visual similarity alone.
The authors evaluate their approach on several remote sensing image datasets, including Prithvi and RSBuilding, demonstrating improved retrieval performance compared to baseline methods. They also show that their system can generalize to new datasets and tasks, highlighting the potential of geospatial foundation models for a variety of remote sensing applications.
Critical Analysis
The paper presents a novel and promising approach for multi-spectral remote sensing image retrieval, leveraging the power of geospatial foundation models. However, there are a few potential limitations and areas for further research that could be considered:
-
Dataset Diversity: The evaluation is primarily conducted on a few curated datasets, which may not fully represent the diversity and complexities of real-world remote sensing data. Further testing on a broader range of datasets, including those with different sensor modalities, geographic regions, and application domains, could help validate the approach's generalizability.
-
Interpretability and Explainability: As with many deep learning-based methods, the inner workings of the model can be difficult to interpret. Incorporating more transparency and explainability into the system could be valuable, especially for applications where human understanding and trust are important.
-
Handling Noisy or Incomplete Data: Real-world remote sensing data can often be affected by various sources of noise, such as cloud cover, atmospheric interference, or sensor malfunctions. Exploring the robustness of the proposed approach to these challenges could be an interesting area of future research.
-
Computational Efficiency: While the use of foundation models can provide powerful representations, the associated computational overhead may be a concern, particularly for large-scale or time-sensitive applications. Investigating ways to optimize the model architecture or inference process could help address these efficiency considerations.
Overall, the paper presents a compelling approach that leverages the strengths of geospatial foundation models to advance the field of multi-spectral remote sensing image retrieval. The authors have demonstrated promising results, and further research addressing the identified limitations could lead to even more impactful and practical applications of this technology.
Conclusion
This paper introduces a novel method for retrieving multi-spectral remote sensing images using geospatial foundation models. By combining powerful pre-trained language models with multi-spectral image encoding, the system can efficiently search and retrieve relevant remote sensing imagery based on textual queries.
The proposed approach outperforms traditional retrieval techniques, showcasing the potential of foundation models to enhance various remote sensing applications, such as land use monitoring, building detection, and zero-shot image generation from sketches. While the paper demonstrates promising results, further research addressing potential limitations around dataset diversity, interpretability, and computational efficiency could help unlock even greater value for the remote sensing community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Composed Image Retrieval for Remote Sensing
Bill Psomas, Ioannis Kakogeorgiou, Nikos Efthymiadis, Giorgos Tolias, Ondrej Chum, Yannis Avrithis, Konstantinos Karantzalos
0
0
This work introduces composed image retrieval to remote sensing. It allows to query a large image archive by image examples alternated by a textual description, enriching the descriptive power over unimodal queries, either visual or textual. Various attributes can be modified by the textual part, such as shape, color, or context. A novel method fusing image-to-image and text-to-image similarity is introduced. We demonstrate that a vision-language model possesses sufficient descriptive power and no further learning step or training data are necessary. We present a new evaluation benchmark focused on color, context, density, existence, quantity, and shape modifications. Our work not only sets the state-of-the-art for this task, but also serves as a foundational step in addressing a gap in the field of remote sensing image retrieval. Code at: https://github.com/billpsomas/rscir
5/30/2024
When are Foundation Models Effective? Understanding the Suitability for Pixel-Level Classification Using Multispectral Imagery
Yiqun Xie, Zhihao Wang, Weiye Chen, Zhili Li, Xiaowei Jia, Yanhua Li, Ruichen Wang, Kangyang Chai, Ruohan Li, Sergii Skakun
0
0
Foundation models, i.e., very large deep learning models, have demonstrated impressive performances in various language and vision tasks that are otherwise difficult to reach using smaller-size models. The major success of GPT-type of language models is particularly exciting and raises expectations on the potential of foundation models in other domains including satellite remote sensing. In this context, great efforts have been made to build foundation models to test their capabilities in broader applications, and examples include Prithvi by NASA-IBM, Segment-Anything-Model, ViT, etc. This leads to an important question: Are foundation models always a suitable choice for different remote sensing tasks, and when or when not? This work aims to enhance the understanding of the status and suitability of foundation models for pixel-level classification using multispectral imagery at moderate resolution, through comparisons with traditional machine learning (ML) and regular-size deep learning models. Interestingly, the results reveal that in many scenarios traditional ML models still have similar or better performance compared to foundation models, especially for tasks where texture is less useful for classification. On the other hand, deep learning models did show more promising results for tasks where labels partially depend on texture (e.g., burn scar), while the difference in performance between foundation models and deep learning models is not obvious. The results conform with our analysis: The suitability of foundation models depend on the alignment between the self-supervised learning tasks and the real downstream tasks, and the typical masked autoencoder paradigm is not necessarily suitable for many remote sensing problems.
4/19/2024

Classifying geospatial objects from multiview aerial imagery using semantic meshes
David Russell, Ben Weinstein, David Wettergreen, Derek Young
0
0
Aerial imagery is increasingly used in Earth science and natural resource management as a complement to labor-intensive ground-based surveys. Aerial systems can collect overlapping images that provide multiple views of each location from different perspectives. However, most prediction approaches (e.g. for tree species classification) use a single, synthesized top-down orthomosaic image as input that contains little to no information about the vertical aspects of objects and may include processing artifacts. We propose an alternate approach that generates predictions directly on the raw images and accurately maps these predictions into geospatial coordinates using semantic meshes. This method$unicode{x2013}$released as a user-friendly open-source toolkit$unicode{x2013}$enables analysts to use the highest quality data for predictions, capture information about the sides of objects, and leverage multiple viewpoints of each location for added robustness. We demonstrate the value of this approach on a new benchmark dataset of four forest sites in the western U.S. that consists of drone images, photogrammetry results, predicted tree locations, and species classification data derived from manual surveys. We show that our proposed multiview method improves classification accuracy from 53% to 75% relative to an orthomosaic baseline on a challenging cross-site tree species classification task.
5/16/2024

Towards a multimodal framework for remote sensing image change retrieval and captioning
Roger Ferrod, Luigi Di Caro, Dino Ienco
0
0
Recently, there has been increasing interest in multimodal applications that integrate text with other modalities, such as images, audio and video, to facilitate natural language interactions with multimodal AI systems. While applications involving standard modalities have been extensively explored, there is still a lack of investigation into specific data modalities such as remote sensing (RS) data. Despite the numerous potential applications of RS data, including environmental protection, disaster monitoring and land planning, available solutions are predominantly focused on specific tasks like classification, captioning and retrieval. These solutions often overlook the unique characteristics of RS data, such as its capability to systematically provide information on the same geographical areas over time. This ability enables continuous monitoring of changes in the underlying landscape. To address this gap, we propose a novel foundation model for bi-temporal RS image pairs, in the context of change detection analysis, leveraging Contrastive Learning and the LEVIR-CC dataset for both captioning and text-image retrieval. By jointly training a contrastive encoder and captioning decoder, our model add text-image retrieval capabilities, in the context of bi-temporal change detection, while maintaining captioning performances that are comparable to the state of the art. We release the source code and pretrained weights at: https://github.com/rogerferrod/RSICRC.
6/21/2024