Zero-shot sketch-based remote sensing image retrieval based on multi-level and attention-guided tokenization
2402.02141
0
0
🖼️
Abstract
Effectively and efficiently retrieving images from remote sensing databases is a critical challenge in the realm of remote sensing big data. Utilizing hand-drawn sketches as retrieval inputs offers intuitive and user-friendly advantages, yet the potential of multi-level feature integration from sketches remains underexplored, leading to suboptimal retrieval performance. To address this gap, our study introduces a novel zero-shot, sketch-based retrieval method for remote sensing images, leveraging multi-level feature extraction, self-attention-guided tokenization and filtering, and cross-modality attention update. This approach employs only vision information and does not require semantic knowledge concerning the sketch and image. It starts by employing multi-level self-attention guided feature extraction to tokenize the query sketches, as well as self-attention feature extraction to tokenize the candidate images. It then employs cross-attention mechanisms to establish token correspondence between these two modalities, facilitating the computation of sketch-to-image similarity. Our method significantly outperforms existing sketch-based remote sensing image retrieval techniques, as evidenced by tests on multiple datasets. Notably, it also exhibits robust zero-shot learning capabilities and strong generalizability in handling unseen categories and novel remote sensing data. The method's scalability can be further enhanced by the pre-calculation of retrieval tokens for all candidate images in a database. This research underscores the significant potential of multi-level, attention-guided tokenization in cross-modal remote sensing image retrieval. For broader accessibility and research facilitation, we have made the code and dataset used in this study publicly available online. Code and dataset are available at https://github.com/Snowstormfly/Cross-modal-retrieval-MLAGT.
Create account to get full access
Overview
- Introduces a novel zero-shot, sketch-based retrieval method for remote sensing images
- Leverages multi-level feature extraction, self-attention-guided tokenization and filtering, and cross-modality attention update
- Significantly outperforms existing sketch-based remote sensing image retrieval techniques
- Exhibits robust zero-shot learning capabilities and strong generalizability
Plain English Explanation
Retrieving images from large remote sensing databases is a significant challenge. Using hand-drawn sketches as the input for image retrieval offers a more intuitive and user-friendly approach compared to traditional methods. However, the full potential of integrating multiple levels of feature information from sketches has not been explored, leading to suboptimal retrieval performance.
This study introduces a new method to address this gap. It uses only visual information, without requiring any semantic knowledge about the sketch or image. The method starts by extracting multi-level features from the query sketches and candidate images using self-attention mechanisms. It then employs cross-attention to establish connections between the tokens (or visual elements) of the sketches and images, allowing the computation of their similarity.
The key innovation is the use of multi-level, attention-guided tokenization to bridge the gap between sketches and remote sensing images. This approach significantly outperforms existing sketch-based retrieval techniques, and also exhibits strong zero-shot learning capabilities, meaning it can handle unseen categories and new remote sensing data.
The method's scalability can be further enhanced by pre-calculating the retrieval tokens for all candidate images in a database. This research highlights the significant potential of multi-level, attention-guided tokenization for effective and efficient cross-modal remote sensing image retrieval.
Technical Explanation
The proposed method leverages multi-level feature extraction, self-attention-guided tokenization, and cross-modality attention update to enable zero-shot, sketch-based retrieval of remote sensing images.
The approach begins by employing multi-level self-attention mechanisms to extract features from the query sketches and tokenize them. Similarly, it uses self-attention to extract features and tokenize the candidate remote sensing images. This ensures that the visual elements of both modalities are effectively represented.
Next, the method establishes cross-attention between the sketch tokens and image tokens, enabling the computation of their similarity. This cross-modal attention update facilitates the identification of the most relevant remote sensing images for a given sketch query, without requiring any semantic knowledge about the sketch or image content.
Experiments on multiple datasets show that this method significantly outperforms existing sketch-based remote sensing image retrieval techniques. Notably, it also exhibits robust zero-shot learning capabilities, allowing it to handle unseen categories and novel remote sensing data with strong generalizability.
The scalability of the method can be further enhanced by pre-calculating the retrieval tokens for all candidate images in a database, enabling efficient large-scale cross-modal retrieval.
Critical Analysis
The paper presents a novel and promising approach to sketch-based remote sensing image retrieval, addressing the limitations of previous methods. The use of multi-level feature extraction and attention-guided tokenization is a key strength, as it allows the model to effectively bridge the gap between sketches and remote sensing images.
However, the paper does not provide a detailed analysis of the model's performance on specific types of remote sensing data or in different real-world scenarios. It would be helpful to understand how the method fares in handling complex or noisy remote sensing images, as well as its robustness to variations in sketch quality or styles.
Additionally, the paper could benefit from a more thorough discussion of the potential limitations and caveats of the proposed approach. For example, the reliance on self-attention and cross-attention mechanisms may introduce computational overhead, which could impact the method's scalability and efficiency in large-scale applications.
Further research could explore ways to enhance the zero-shot learning capabilities of the model, such as incorporating additional inductive biases or leveraging external knowledge sources to improve its generalizability to unseen categories and novel remote sensing data.
Conclusion
This study introduces a novel zero-shot, sketch-based retrieval method for remote sensing images that significantly outperforms existing techniques. The key innovation is the use of multi-level, attention-guided tokenization to effectively bridge the gap between sketches and remote sensing images, enabling robust cross-modal retrieval without requiring any semantic knowledge.
The method's strong zero-shot learning capabilities and generalizability to unseen categories and novel remote sensing data highlight its significant potential for practical applications in remote sensing. Further research to address potential limitations and enhance the method's scalability could further strengthen its impact in the field of remote sensing big data management and retrieval.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

New!Cross-Modal Attention Alignment Network with Auxiliary Text Description for zero-shot sketch-based image retrieval
Hanwen Su, Ge Song, Kai Huang, Jiyan Wang, Ming Yang
0
0
In this paper, we study the problem of zero-shot sketch-based image retrieval (ZS-SBIR). The prior methods tackle the problem in a two-modality setting with only category labels or even no textual information involved. However, the growing prevalence of Large-scale pre-trained Language Models (LLMs), which have demonstrated great knowledge learned from web-scale data, can provide us with an opportunity to conclude collective textual information. Our key innovation lies in the usage of text data as auxiliary information for images, thus leveraging the inherent zero-shot generalization ability that language offers. To this end, we propose an approach called Cross-Modal Attention Alignment Network with Auxiliary Text Description for zero-shot sketch-based image retrieval. The network consists of three components: (i) a Description Generation Module that generates textual descriptions for each training category by prompting an LLM with several interrogative sentences, (ii) a Feature Extraction Module that includes two ViTs for sketch and image data, a transformer for extracting tokens of sentences of each training category, finally (iii) a Cross-modal Alignment Module that exchanges the token features of both text-sketch and text-image using cross-attention mechanism, and align the tokens locally and globally. Extensive experiments on three benchmark datasets show our superior performances over the state-of-the-art ZS-SBIR methods.
7/2/2024
✨
Knowledge-aware Text-Image Retrieval for Remote Sensing Images
Li Mi, Xianjie Dai, Javiera Castillo-Navarro, Devis Tuia
0
0
Image-based retrieval in large Earth observation archives is challenging because one needs to navigate across thousands of candidate matches only with the query image as a guide. By using text as information supporting the visual query, the retrieval system gains in usability, but at the same time faces difficulties due to the diversity of visual signals that cannot be summarized by a short caption only. For this reason, as a matching-based task, cross-modal text-image retrieval often suffers from information asymmetry between texts and images. To address this challenge, we propose a Knowledge-aware Text-Image Retrieval (KTIR) method for remote sensing images. By mining relevant information from an external knowledge graph, KTIR enriches the text scope available in the search query and alleviates the information gaps between texts and images for better matching. Moreover, by integrating domain-specific knowledge, KTIR also enhances the adaptation of pre-trained vision-language models to remote sensing applications. Experimental results on three commonly used remote sensing text-image retrieval benchmarks show that the proposed knowledge-aware method leads to varied and consistent retrievals, outperforming state-of-the-art retrieval methods.
5/7/2024
🖼️
Dual-Modal Prompting for Sketch-Based Image Retrieval
Liying Gao, Bingliang Jiao, Peng Wang, Shizhou Zhang, Hanwang Zhang, Yanning Zhang
0
0
Sketch-based image retrieval (SBIR) associates hand-drawn sketches with their corresponding realistic images. In this study, we aim to tackle two major challenges of this task simultaneously: i) zero-shot, dealing with unseen categories, and ii) fine-grained, referring to intra-category instance-level retrieval. Our key innovation lies in the realization that solely addressing this cross-category and fine-grained recognition task from the generalization perspective may be inadequate since the knowledge accumulated from limited seen categories might not be fully valuable or transferable to unseen target categories. Inspired by this, in this work, we propose a dual-modal prompting CLIP (DP-CLIP) network, in which an adaptive prompting strategy is designed. Specifically, to facilitate the adaptation of our DP-CLIP toward unpredictable target categories, we employ a set of images within the target category and the textual category label to respectively construct a set of category-adaptive prompt tokens and channel scales. By integrating the generated guidance, DP-CLIP could gain valuable category-centric insights, efficiently adapting to novel categories and capturing unique discriminative clues for effective retrieval within each target category. With these designs, our DP-CLIP outperforms the state-of-the-art fine-grained zero-shot SBIR method by 7.3% in Acc.@1 on the Sketchy dataset. Meanwhile, in the other two category-level zero-shot SBIR benchmarks, our method also achieves promising performance.
4/30/2024
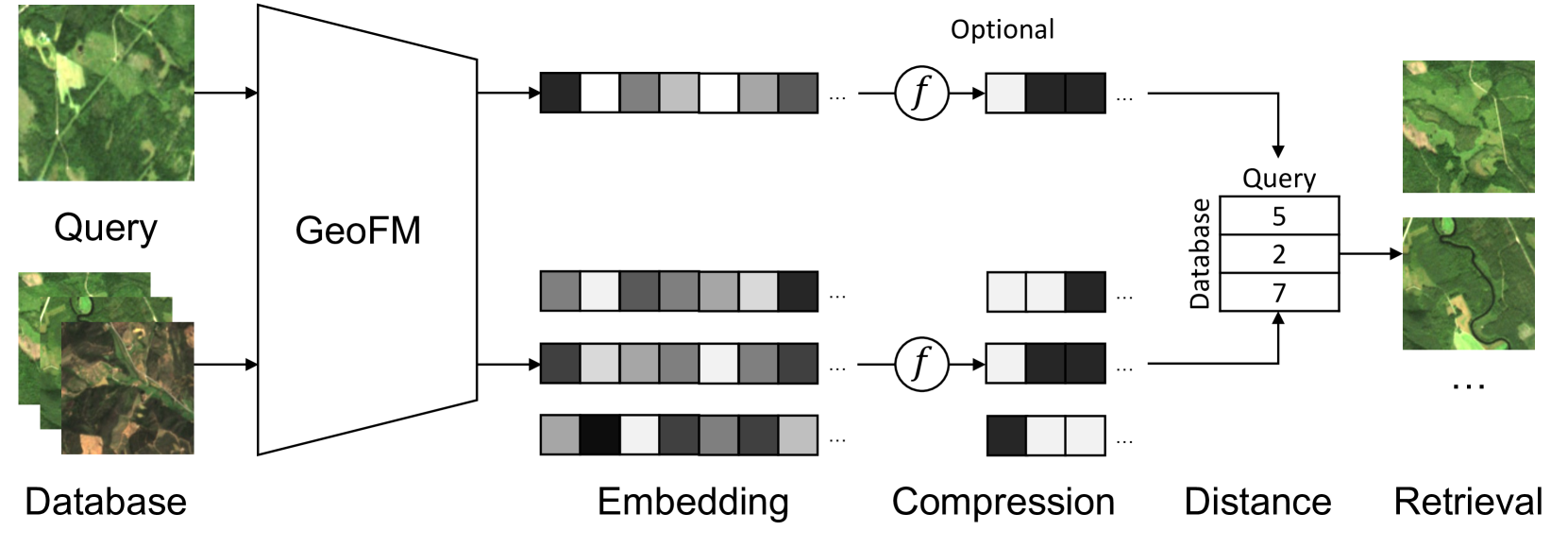
Multi-Spectral Remote Sensing Image Retrieval Using Geospatial Foundation Models
Benedikt Blumenstiel, Viktoria Moor, Romeo Kienzler, Thomas Brunschwiler
0
0
Image retrieval enables an efficient search through vast amounts of satellite imagery and returns similar images to a query. Deep learning models can identify images across various semantic concepts without the need for annotations. This work proposes to use Geospatial Foundation Models, like Prithvi, for remote sensing image retrieval with multiple benefits: i) the models encode multi-spectral satellite data and ii) generalize without further fine-tuning. We introduce two datasets to the retrieval task and observe a strong performance: Prithvi processes six bands and achieves a mean Average Precision of 97.62% on BigEarthNet-43 and 44.51% on ForestNet-12, outperforming other RGB-based models. Further, we evaluate three compression methods with binarized embeddings balancing retrieval speed and accuracy. They match the retrieval speed of much shorter hash codes while maintaining the same accuracy as floating-point embeddings but with a 32-fold compression. The code is available at https://github.com/IBM/remote-sensing-image-retrieval.
5/24/2024