Multilingual Diversity Improves Vision-Language Representations
2405.16915
0
0
📊
Abstract
Massive web-crawled image-text datasets lay the foundation for recent progress in multimodal learning. These datasets are designed with the goal of training a model to do well on standard computer vision benchmarks, many of which, however, have been shown to be English-centric (e.g., ImageNet). Consequently, existing data curation techniques gravitate towards using predominantly English image-text pairs and discard many potentially useful non-English samples. Our work questions this practice. Multilingual data is inherently enriching not only because it provides a gateway to learn about culturally salient concepts, but also because it depicts common concepts differently from monolingual data. We thus conduct a systematic study to explore the performance benefits of using more samples of non-English origins with respect to English vision tasks. By translating all multilingual image-text pairs from a raw web crawl to English and re-filtering them, we increase the prevalence of (translated) multilingual data in the resulting training set. Pre-training on this dataset outperforms using English-only or English-dominated datasets on ImageNet, ImageNet distribution shifts, image-English-text retrieval and on average across 38 tasks from the DataComp benchmark. On a geographically diverse task like GeoDE, we also observe improvements across all regions, with the biggest gain coming from Africa. In addition, we quantitatively show that English and non-English data are significantly different in both image and (translated) text space. We hope that our findings motivate future work to be more intentional about including multicultural and multilingual data, not just when non-English or geographically diverse tasks are involved, but to enhance model capabilities at large.
Create account to get full access
Overview
- Researchers investigate the benefits of using more non-English data samples for training machine learning models on English vision tasks.
- They create a dataset by translating multilingual image-text pairs from a web crawl into English, increasing the prevalence of multilingual data.
- Pre-training on this dataset leads to improved performance on ImageNet, distribution shifts, image-text retrieval, and a diverse set of tasks.
- The paper highlights the value of including multicultural and multilingual data to enhance model capabilities, not just for non-English or geographically diverse tasks.
Plain English Explanation
Most large datasets used to train computer vision and multimodal models are predominantly in English. While this may work well for tasks focused on English-speaking regions, it can limit a model's understanding of concepts and perspectives from other cultures and languages.
The researchers in this paper wanted to explore whether including more non-English data could actually improve performance on standard English vision tasks. To do this, they took a large multilingual dataset from the web and translated all the non-English image-text pairs into English. This gave them a more diverse dataset that they could use to pre-train a model.
When they tested this pre-trained model, they found that it outperformed models trained on English-only or English-dominated datasets across a variety of tasks. This was true not just for tasks involving non-English or geographically diverse data, but also for standard English vision benchmarks like ImageNet.
The researchers believe this is because the non-English data provides a richer understanding of concepts, perspectives, and visual depictions that can be helpful even for tasks focused on English-speaking regions. They hope their findings will motivate the AI community to be more intentional about including multicultural and multilingual data in model training, not just for niche tasks, but to generally enhance model capabilities.
Technical Explanation
The researchers conducted a systematic study to explore the performance benefits of using more non-English data samples when training models on English vision tasks. They started with a raw web-crawled dataset containing multilingual image-text pairs, and translated all non-English pairs into English. This allowed them to increase the prevalence of (translated) multilingual data in the resulting training set.
They then pre-trained a model on this more diverse dataset and evaluated its performance on a range of tasks, including ImageNet classification, ImageNet distribution shifts, image-English-text retrieval, and 38 tasks from the DataComp benchmark. Across the board, the pre-trained model outperformed models trained on English-only or English-dominated datasets.
The researchers also conducted quantitative analyses to show that English and non-English data are significantly different in both image and (translated) text space. This suggests the non-English data is providing unique information that helps the model develop a richer, more well-rounded understanding of concepts, even for English-centric tasks.
Critical Analysis
The researchers acknowledge that their dataset curation technique, while effective, may not capture all the nuances and cultural context present in the original non-English data. Translating the text to English could potentially lead to some loss of meaning or subtle connotations.
Additionally, the paper does not delve into the specific mechanisms by which the inclusion of non-English data leads to performance gains. More research would be needed to fully understand the underlying reasons and how they could be further leveraged.
Nevertheless, the findings presented in this paper are compelling and raise important questions about the role of multicultural and multilingual data in AI development. As the researchers note, this work could motivate the field to be more intentional about diversifying the data used to train large language models and other multimodal systems, not just for niche tasks, but to generally enhance their capabilities and better serve a global audience.
Conclusion
This research demonstrates that incorporating more non-English data can lead to significant performance improvements on a wide range of English vision tasks, from standard benchmarks to geographically diverse challenges. The findings suggest that multilingual and multicultural data can provide a richer understanding of concepts, perspectives, and visual depictions that can benefit models even when the end task is focused on English-speaking regions.
By highlighting the value of including diverse data sources, this work could inspire the AI community to be more intentional about diversifying their datasets and model training approaches. This could ultimately lead to the development of more capable, equitable, and globally relevant AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
No Filter: Cultural and Socioeconomic Diversityin Contrastive Vision-Language Models
Ang'eline Pouget, Lucas Beyer, Emanuele Bugliarello, Xiao Wang, Andreas Peter Steiner, Xiaohua Zhai, Ibrahim Alabdulmohsin
0
0
We study cultural and socioeconomic diversity in contrastive vision-language models (VLMs). Using a broad range of benchmark datasets and evaluation metrics, we bring to attention several important findings. First, the common filtering of training data to English image-text pairs disadvantages communities of lower socioeconomic status and negatively impacts cultural understanding. Notably, this performance gap is not captured by - and even at odds with - the currently popular evaluation metrics derived from the Western-centric ImageNet and COCO datasets. Second, pretraining with global, unfiltered data before fine-tuning on English content can improve cultural understanding without sacrificing performance on said popular benchmarks. Third, we introduce the task of geo-localization as a novel evaluation metric to assess cultural diversity in VLMs. Our work underscores the value of using diverse data to create more inclusive multimodal systems and lays the groundwork for developing VLMs that better represent global perspectives.
5/27/2024
👀
Constructing Multilingual Visual-Text Datasets Revealing Visual Multilingual Ability of Vision Language Models
Jesse Atuhurra, Iqra Ali, Tatsuya Hiraoka, Hidetaka Kamigaito, Tomoya Iwakura, Taro Watanabe
0
0
Large language models (LLMs) have increased interest in vision language models (VLMs), which process image-text pairs as input. Studies investigating the visual understanding ability of VLMs have been proposed, but such studies are still preliminary because existing datasets do not permit a comprehensive evaluation of the fine-grained visual linguistic abilities of VLMs across multiple languages. To further explore the strengths of VLMs, such as GPT-4V cite{openai2023GPT4}, we developed new datasets for the systematic and qualitative analysis of VLMs. Our contribution is four-fold: 1) we introduced nine vision-and-language (VL) tasks (including object recognition, image-text matching, and more) and constructed multilingual visual-text datasets in four languages: English, Japanese, Swahili, and Urdu through utilizing templates containing textit{questions} and prompting GPT4-V to generate the textit{answers} and the textit{rationales}, 2) introduced a new VL task named textit{unrelatedness}, 3) introduced rationales to enable human understanding of the VLM reasoning process, and 4) employed human evaluation to measure the suitability of proposed datasets for VL tasks. We show that VLMs can be fine-tuned on our datasets. Our work is the first to conduct such analyses in Swahili and Urdu. Also, it introduces textit{rationales} in VL analysis, which played a vital role in the evaluation.
6/26/2024
🖼️
Tagengo: A Multilingual Chat Dataset
Peter Devine
0
0
Open source large language models (LLMs) have shown great improvements in recent times. However, many of these models are focused solely on popular spoken languages. We present a high quality dataset of more than 70k prompt-response pairs in 74 languages which consist of human generated prompts and synthetic responses. We use this dataset to train a state-of-the-art open source English LLM to chat multilingually. We evaluate our model on MT-Bench chat benchmarks in 6 languages, finding that our multilingual model outperforms previous state-of-the-art open source LLMs across each language. We further find that training on more multilingual data is beneficial to the performance in a chosen target language (Japanese) compared to simply training on only data in that language. These results indicate the necessity of training on large amounts of high quality multilingual data to make a more accessible LLM.
5/22/2024
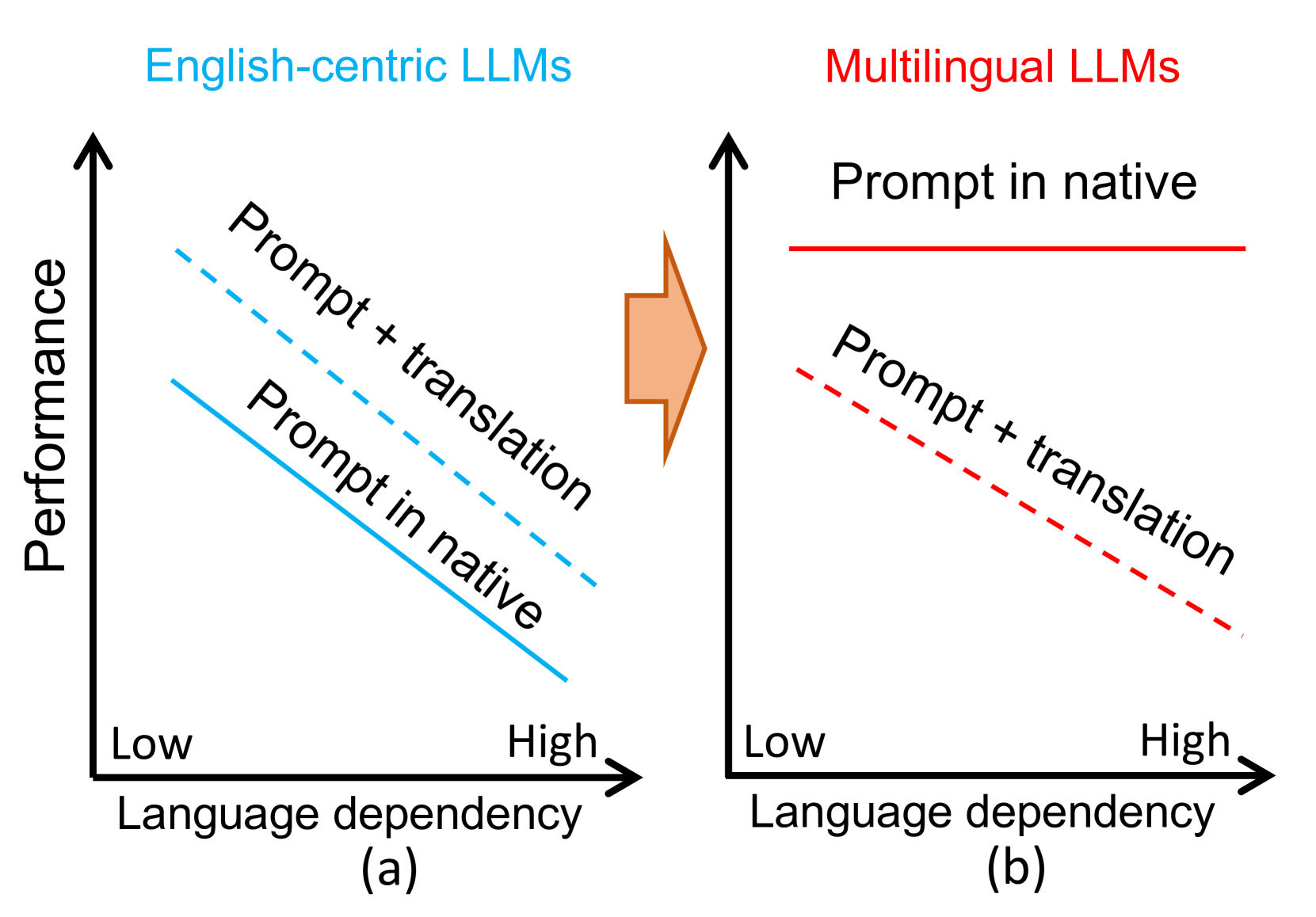
Is Translation All You Need? A Study on Solving Multilingual Tasks with Large Language Models
Chaoqun Liu, Wenxuan Zhang, Yiran Zhao, Anh Tuan Luu, Lidong Bing
0
0
Large language models (LLMs) have demonstrated multilingual capabilities; yet, they are mostly English-centric due to the imbalanced training corpora. Existing works leverage this phenomenon to improve their multilingual performances through translation, primarily on natural language processing (NLP) tasks. This work extends the evaluation from NLP tasks to real user queries and from English-centric LLMs to non-English-centric LLMs. While translation into English can help improve the performance of multilingual NLP tasks for English-centric LLMs, it may not be optimal for all scenarios. For culture-related tasks that need deep language understanding, prompting in the native language tends to be more promising as it better captures the nuances of culture and language. Our experiments reveal varied behaviors among different LLMs and tasks in the multilingual context. Therefore, we advocate for more comprehensive multilingual evaluation and more efforts toward developing multilingual LLMs beyond English-centric ones.
6/21/2024