Multimodal Guidance Network for Missing-Modality Inference in Content Moderation

0
🌐
Sign in to get full access
Overview
- Multimodal deep learning, especially vision-language models, have made significant progress in recent years.
- These models excel at many downstream tasks like content moderation and violence detection.
- However, standard multimodal approaches assume consistent modalities between training and inference, limiting their real-world applicability.
- Existing research addresses this by reconstructing missing modalities, but this increases computational costs, which can be critical for large, deployed systems.
Plain English Explanation
Multimodal deep learning models that combine vision and language have become very powerful, helping with tasks like detecting violent content or moderating online posts. The key insight is that these models can understand the world better by looking at images and text together, not just one or the other.
However, a limitation of these models is that they assume the same type of information (modalities) will be available during training and when actually using the model. In real-world scenarios, sometimes certain modalities (like audio or video) may not be present when the model needs to make a prediction. Prior work has tried to address this by reconstructing the missing modalities, but this adds extra computational costs, which can be a problem for large-scale systems.
The paper proposes a new approach that avoids this issue. Instead of reconstructing missing modalities, it trains single-modality models (e.g., just text or just vision) to take advantage of the multimodal representations learned during training. This allows the single-modality models to perform well without the extra computational burden of the full multimodal model.
Technical Explanation
The key innovation in this paper is a "guidance network" that promotes knowledge sharing during training of multimodal models. Typical multimodal architectures use separate sub-networks for each modality (e.g., vision and language) that are then combined. In contrast, the guidance network allows these sub-networks to learn from each other, improving their individual performance.
Specifically, the guidance network takes the output representations from the sub-networks and uses them to guide the training of each other. This encourages the sub-networks to learn more general, transferable representations that are useful for both modalities. During inference, only the single-modality sub-networks are used, avoiding the computational overhead of the full multimodal model.
The researchers evaluate their approach on a violence detection task, showing that the single-modality models trained with their guidance network significantly outperform traditionally trained counterparts, while requiring less computation.
Critical Analysis
The paper presents a promising approach to address the challenge of missing modalities in real-world multimodal deep learning applications. By training single-modality models to leverage multimodal representations, the method avoids the computational overhead of reconstructing missing modalities, which can be an important practical concern.
One potential limitation is that the guidance network adds some additional complexity to the training process, which may make it more difficult to implement or optimize. The paper does not provide a detailed analysis of the training dynamics or convergence properties of the guidance network.
Additionally, the evaluation is focused on a single task (violence detection), and it would be valuable to see how the approach generalizes to other multimodal applications, such as image-text generation or sentiment analysis. Further research could also explore how the guidance network performs under different levels of missing modalities or modality mismatches between training and inference.
Conclusion
This paper presents an innovative approach to address the challenge of missing modalities in multimodal deep learning. By training single-modality models to leverage multimodal representations through a guidance network, the method avoids the computational overhead of reconstructing missing modalities, making it a promising solution for real-world applications with practical constraints.
The results on violence detection are compelling, but further research is needed to fully understand the strengths, limitations, and generalizability of this approach across a wider range of multimodal tasks and scenarios. Overall, this work contributes an important step towards more robust and efficient multimodal deep learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
0
Multimodal Guidance Network for Missing-Modality Inference in Content Moderation
Zhuokai Zhao, Harish Palani, Tianyi Liu, Lena Evans, Ruth Toner
Multimodal deep learning, especially vision-language models, have gained significant traction in recent years, greatly improving performance on many downstream tasks, including content moderation and violence detection. However, standard multimodal approaches often assume consistent modalities between training and inference, limiting applications in many real-world use cases, as some modalities may not be available during inference. While existing research mitigates this problem through reconstructing the missing modalities, they unavoidably increase unnecessary computational cost, which could be just as critical, especially for large, deployed infrastructures in industry. To this end, we propose a novel guidance network that promotes knowledge sharing during training, taking advantage of the multimodal representations to train better single-modality models to be used for inference. Real-world experiments in violence detection shows that our proposed framework trains single-modality models that significantly outperform traditionally trained counterparts, while avoiding increases in computational cost for inference.
Read more8/6/2024
0
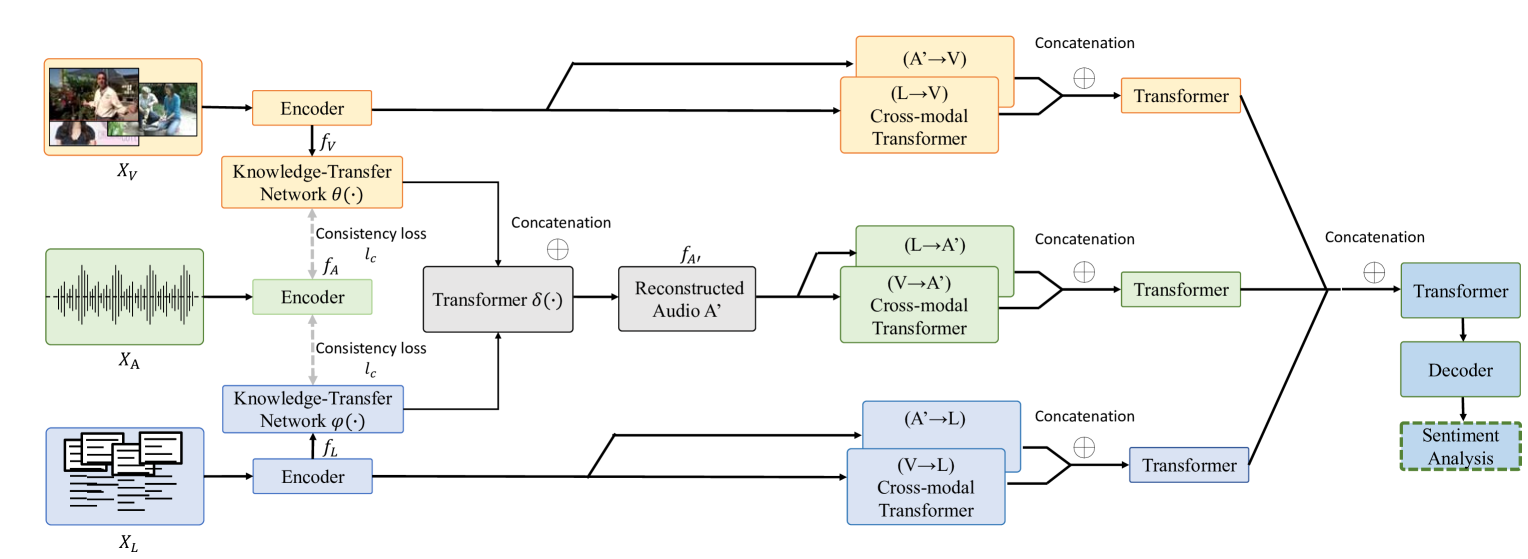
Multimodal Sentiment Analysis with Missing Modality: A Knowledge-Transfer Approach
Weide Liu, Huijing Zhan, Hao Chen, Fengmao Lv
Multimodal sentiment analysis aims to identify the emotions expressed by individuals through visual, language, and acoustic cues. However, most of the existing research efforts assume that all modalities are available during both training and testing, making their algorithms susceptible to the missing modality scenario. In this paper, we propose a novel knowledge-transfer network to translate between different modalities to reconstruct the missing audio modalities. Moreover, we develop a cross-modality attention mechanism to retain the maximal information of the reconstructed and observed modalities for sentiment prediction. Extensive experiments on three publicly available datasets demonstrate significant improvements over baselines and achieve comparable results to the previous methods with complete multi-modality supervision.
Read more7/12/2024

0
Modality Invariant Multimodal Learning to Handle Missing Modalities: A Single-Branch Approach
Muhammad Saad Saeed, Shah Nawaz, Muhammad Zaigham Zaheer, Muhammad Haris Khan, Karthik Nandakumar, Muhammad Haroon Yousaf, Hassan Sajjad, Tom De Schepper, Markus Schedl
Multimodal networks have demonstrated remarkable performance improvements over their unimodal counterparts. Existing multimodal networks are designed in a multi-branch fashion that, due to the reliance on fusion strategies, exhibit deteriorated performance if one or more modalities are missing. In this work, we propose a modality invariant multimodal learning method, which is less susceptible to the impact of missing modalities. It consists of a single-branch network sharing weights across multiple modalities to learn inter-modality representations to maximize performance as well as robustness to missing modalities. Extensive experiments are performed on four challenging datasets including textual-visual (UPMC Food-101, Hateful Memes, Ferramenta) and audio-visual modalities (VoxCeleb1). Our proposed method achieves superior performance when all modalities are present as well as in the case of missing modalities during training or testing compared to the existing state-of-the-art methods.
Read more8/15/2024
0
Missing Modality Prediction for Unpaired Multimodal Learning via Joint Embedding of Unimodal Models
Donggeun Kim, Taesup Kim
Multimodal learning typically relies on the assumption that all modalities are fully available during both the training and inference phases. However, in real-world scenarios, consistently acquiring complete multimodal data presents significant challenges due to various factors. This often leads to the issue of missing modalities, where data for certain modalities are absent, posing considerable obstacles not only for the availability of multimodal pretrained models but also for their fine-tuning and the preservation of robustness in downstream tasks. To address these challenges, we propose a novel framework integrating parameter-efficient fine-tuning of unimodal pretrained models with a self-supervised joint-embedding learning method. This framework enables the model to predict the embedding of a missing modality in the representation space during inference. Our method effectively predicts the missing embedding through prompt tuning, leveraging information from available modalities. We evaluate our approach on several multimodal benchmark datasets and demonstrate its effectiveness and robustness across various scenarios of missing modalities.
Read more7/18/2024