Musical Word Embedding for Music Tagging and Retrieval
2404.13569
0
0

Abstract
Word embedding has become an essential means for text-based information retrieval. Typically, word embeddings are learned from large quantities of general and unstructured text data. However, in the domain of music, the word embedding may have difficulty understanding musical contexts or recognizing music-related entities like artists and tracks. To address this issue, we propose a new approach called Musical Word Embedding (MWE), which involves learning from various types of texts, including both everyday and music-related vocabulary. We integrate MWE into an audio-word joint representation framework for tagging and retrieving music, using words like tag, artist, and track that have different levels of musical specificity. Our experiments show that using a more specific musical word like track results in better retrieval performance, while using a less specific term like tag leads to better tagging performance. To balance this compromise, we suggest multi-prototype training that uses words with different levels of musical specificity jointly. We evaluate both word embedding and audio-word joint embedding on four tasks (tag rank prediction, music tagging, query-by-tag, and query-by-track) across two datasets (Million Song Dataset and MTG-Jamendo). Our findings show that the suggested MWE is more efficient and robust than the conventional word embedding.
Create account to get full access
Overview
- This paper proposes a novel "musical word embedding" approach to improve music tagging and retrieval.
- The authors develop a neural network model that can learn vector representations (embeddings) of musical concepts and tags, allowing for more effective music understanding and applications.
- The proposed approach outperforms existing methods on several music-related tasks, demonstrating the benefits of this musical word embedding technique.
Plain English Explanation
The paper focuses on a challenge in the field of music technology: how can we better understand and work with the vast amount of music data available online and in digital collections? The researchers tackle this problem by developing a new way to represent musical concepts and tags as numerical vectors, known as "word embeddings."
Similar to how language models can learn numerical representations of words that capture their meanings and relationships, the authors' approach can learn embeddings for musical concepts like genres, instruments, and mood tags. These embeddings allow the model to understand the similarity and differences between musical elements, which can then be leveraged for improved music tagging, retrieval, and other applications.
For example, the model might learn that the embeddings for "guitar" and "bass" are closer together than the embeddings for "guitar" and "violin," reflecting their musical similarity. This type of knowledge can then be used to better categorize and organize music collections, or to recommend similar songs to users based on the tags associated with them.
By developing this "musical word embedding" technique, the researchers have created a powerful tool for bridging the gap between the human understanding of music and the way it is represented in computer systems. This could lead to significant advancements in music information retrieval, music auto-tagging, and other music-related applications.
Technical Explanation
The core of the paper's technical approach is a neural network model that learns numerical embeddings for a vocabulary of musical concepts, including genres, instruments, moods, and other tags. This is similar to the way language models like BERT learn vector representations of words that capture their semantic relationships.
To train the musical word embeddings, the authors leverage a large dataset of music tracks and associated tags. The model is trained to predict the tags given the audio features of each track, while also learning the embeddings that best represent the relationships between the tags.
The resulting embeddings are then evaluated on a range of music-related tasks, such as tag prediction, tag clustering, and music retrieval. The authors show that their musical word embedding approach outperforms previous methods that did not explicitly model the structure of the musical tag space.
Additionally, the paper explores ways to further enhance the embedding performance, including leveraging large language models and incorporating external knowledge.
Critical Analysis
The paper presents a compelling approach to addressing an important challenge in music information retrieval. By developing a method to learn meaningful numerical representations of musical concepts, the researchers have opened up new possibilities for more effective music understanding and applications.
One potential limitation noted in the paper is the reliance on a fixed vocabulary of tags. While the authors demonstrate the effectiveness of their approach on this dataset, it would be valuable to explore how the embeddings could be extended to handle more open-ended musical descriptions and user-generated tags.
Additionally, the paper does not delve deeply into the interpretability of the learned embeddings. It would be interesting to further analyze the embeddings to gain insights into how the model is capturing the underlying structure of music and musical concepts.
Overall, this work represents an important step forward in bridging the gap between the human perception of music and the way it is represented in computer systems. As the researchers continue to build upon this foundation, we can expect to see even more exciting advancements in the field of music information retrieval and related areas.
Conclusion
The proposed "musical word embedding" approach in this paper offers a novel and effective way to represent musical concepts and tags as numerical vectors. By learning these embeddings, the model can better capture the relationships between musical elements, leading to improved performance on a variety of music-related tasks.
This work highlights the potential of applying advanced language modeling techniques to the domain of music, opening up new possibilities for more intelligent and intuitive music applications. As the authors continue to refine and expand upon this approach, we can expect to see even greater advancements in the field of music information retrieval and the broader understanding of music through computational means.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Fusing Audio and Metadata Embeddings Improves Language-based Audio Retrieval
Paul Primus, Gerhard Widmer
0
0
Matching raw audio signals with textual descriptions requires understanding the audio's content and the description's semantics and then drawing connections between the two modalities. This paper investigates a hybrid retrieval system that utilizes audio metadata as an additional clue to understand the content of audio signals before matching them with textual queries. We experimented with metadata often attached to audio recordings, such as keywords and natural-language descriptions, and we investigated late and mid-level fusion strategies to merge audio and metadata. Our hybrid approach with keyword metadata and late fusion improved the retrieval performance over a content-based baseline by 2.36 and 3.69 pp. mAP@10 on the ClothoV2 and AudioCaps benchmarks, respectively.
6/26/2024
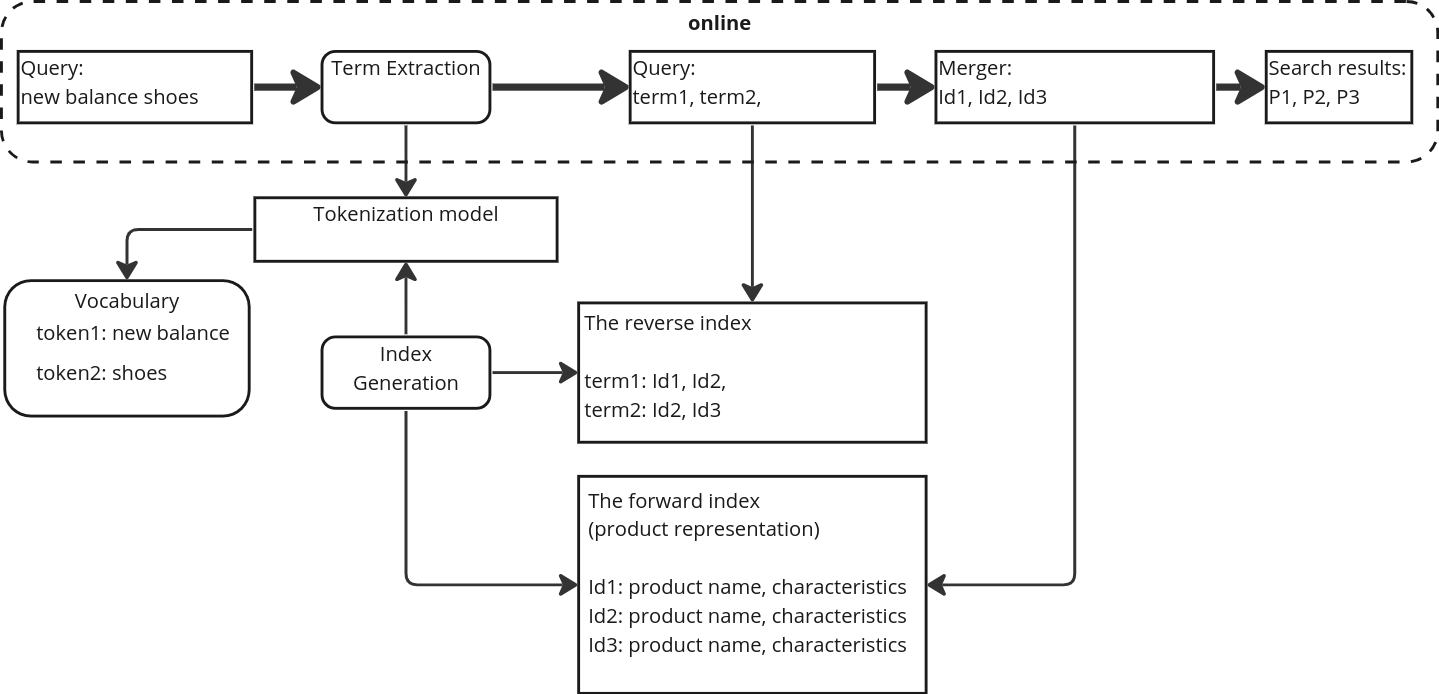
Multi-word Term Embeddings Improve Lexical Product Retrieval
Viktor Shcherbakov, Fedor Krasnov
0
0
Product search is uniquely different from search for documents, Internet resources or vacancies, therefore it requires the development of specialized search systems. The present work describes the H1 embdedding model, designed for an offline term indexing of product descriptions at e-commerce platforms. The model is compared to other state-of-the-art (SoTA) embedding models within a framework of hybrid product search system that incorporates the advantages of lexical methods for product retrieval and semantic embedding-based methods. We propose an approach to building semantically rich term vocabularies for search indexes. Compared to other production semantic models, H1 paired with the proposed approach stands out due to its ability to process multi-word product terms as one token. As an example, for search queries new balance shoes, gloria jeans kids wear brand entity will be represented as one token - new balance, gloria jeans. This results in an increased precision of the system without affecting the recall. The hybrid search system with proposed model scores mAP@12 = 56.1% and R@1k = 86.6% on the WANDS public dataset, beating other SoTA analogues.
6/4/2024
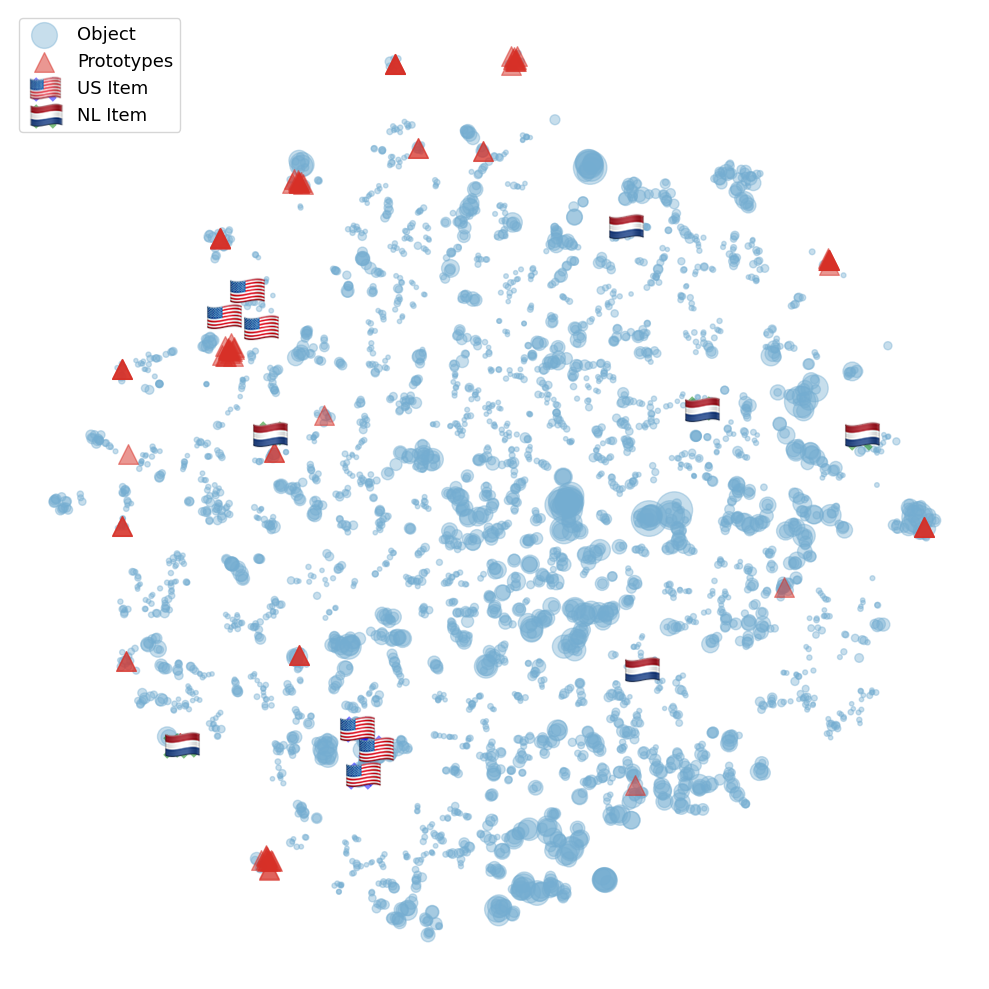
Advancing Cultural Inclusivity: Optimizing Embedding Spaces for Balanced Music Recommendations
Armin Moradi, Nicola Neophytou, Golnoosh Farnadi
0
0
Popularity bias in music recommendation systems -- where artists and tracks with the highest listen counts are recommended more often -- can also propagate biases along demographic and cultural axes. In this work, we identify these biases in recommendations for artists from underrepresented cultural groups in prototype-based matrix factorization methods. Unlike traditional matrix factorization methods, prototype-based approaches are interpretable. This allows us to directly link the observed bias in recommendations for minority artists (the effect) to specific properties of the embedding space (the cause). We mitigate popularity bias in music recommendation through capturing both users' and songs' cultural nuances in the embedding space. To address these challenges while maintaining recommendation quality, we propose two novel enhancements to the embedding space: i) we propose an approach to filter-out the irrelevant prototypes used to represent each user and item to improve generalizability, and ii) we introduce regularization techniques to reinforce a more uniform distribution of prototypes within the embedding space. Our results demonstrate significant improvements in reducing popularity bias and enhancing demographic and cultural fairness in music recommendations while achieving competitive -- if not better -- overall performance.
5/29/2024

Investigating Design Choices in Joint-Embedding Predictive Architectures for General Audio Representation Learning
Alain Riou, Stefan Lattner, Gaetan Hadjeres, Geoffroy Peeters
0
0
This paper addresses the problem of self-supervised general-purpose audio representation learning. We explore the use of Joint-Embedding Predictive Architectures (JEPA) for this task, which consists of splitting an input mel-spectrogram into two parts (context and target), computing neural representations for each, and training the neural network to predict the target representations from the context representations. We investigate several design choices within this framework and study their influence through extensive experiments by evaluating our models on various audio classification benchmarks, including environmental sounds, speech and music downstream tasks. We focus notably on which part of the input data is used as context or target and show experimentally that it significantly impacts the model's quality. In particular, we notice that some effective design choices in the image domain lead to poor performance on audio, thus highlighting major differences between these two modalities.
5/15/2024