MVSA-Net: Multi-View State-Action Recognition for Robust and Deployable Trajectory Generation

0
👁️
Sign in to get full access
Overview
- The paper introduces a technique called "Multi-View State-Action Network" (MVSA-Net) to improve robot learning from observation (LfO) by using multiple camera viewpoints to overcome occlusions.
- LfO allows robots to learn tasks by simply observing humans perform them, reducing the need for tedious programming.
- However, existing single-view LfO models struggle when the task is occluded from the camera's perspective.
- MVSA-Net addresses this limitation by fusing information from multiple camera views to better recognize the state and actions in each frame.
Plain English Explanation
The paper describes a way to help robots learn new tasks more easily. Traditionally, robots need to be programmed step-by-step to perform a task, which can be very time-consuming. An alternative approach is learn-from-observation (LfO), where the robot simply watches a person doing the task and tries to learn from that.
One key challenge with LfO is that the robot's camera may not always have a clear view of what the person is doing, especially if there are objects in the way (called "occlusions"). To address this, the researchers developed a new system called MVSA-Net that uses multiple cameras to observe the task from different angles. By combining the information from these multiple viewpoints, MVSA-Net can better recognize the steps of the task even when parts of it are blocked from any single camera's perspective.
The researchers tested MVSA-Net on two different tasks and found that it was better able to identify the correct sequence of states and actions compared to single-camera approaches, especially when there were occlusions present. This suggests MVSA-Net could make it easier for robots to learn new tasks through simple observation, without the need for extensive manual programming.
Technical Explanation
The core of the LfO pipeline is transforming the depth camera frames into corresponding task state and action pairs, which can then be used for techniques like imitation learning or inverse reinforcement learning. While existing computer vision models can analyze videos for activity recognition, the SA-Net model is specifically designed for robotic LfO from RGB-D data.
However, SA-Net and similar models only analyze data from a single camera viewpoint. This makes them highly sensitive to occlusions that frequently occur in real-world deployments. To address this limitation, the researchers present MVSA-Net, which extends the SA-Net architecture to leverage multiple synchronized camera viewpoints.
MVSA-Net takes in RGB-D data from multiple cameras, integrates the information across views, and outputs more robust state-action predictions even in the presence of occlusions. Experiments on two different task domains show that MVSA-Net outperforms single-view approaches in recognizing the correct state-action trajectory, especially when occlusions are present.
The researchers also conduct ablation studies to evaluate how MVSA-Net's performance is affected by factors like camera placement and environmental conditions. These analyses help establish the contributions of MVSA-Net's architectural components and demonstrate its potential for more reliable and deployable LfO systems.
Critical Analysis
The paper makes a compelling case for the benefits of MVSA-Net over single-view LfO approaches. By leveraging multiple synchronized camera viewpoints, the system is able to better handle occlusions that can severely degrade the performance of existing methods.
However, the paper does not fully address the practical challenges of deploying a multi-camera setup in real-world factory or warehouse environments. Factors like camera calibration, synchronization, and placement would need to be carefully considered to ensure robust performance. The authors mention these as potential limitations, but do not provide much detail on how to overcome them.
Additionally, the paper focuses primarily on improving state-action recognition, but does not delve into how this capability would translate to the robot's ability to actually learn and execute the observed tasks. Further research may be needed to understand the downstream implications of MVSA-Net's performance gains.
Overall, the MVSA-Net approach represents a promising step forward for making robot learning from observation more practical and reliable. But there are still some open questions and practical considerations that would need to be addressed before widespread deployment.
Conclusion
The key contribution of this paper is the introduction of MVSA-Net, a multi-view extension to the SA-Net model that enables more robust state-action recognition for robot learning from observation (LfO). By fusing information from multiple synchronized camera viewpoints, MVSA-Net can better handle occlusions that frequently occur in real-world environments, outperforming single-view approaches.
The demonstrated performance improvements suggest MVSA-Net could significantly enhance the accessibility and deployability of LfO systems, reducing the need for tedious manual robot programming. With further research into practical implementation details, MVSA-Net holds the potential to make it easier for robots to learn new skills simply by observing humans, a capability that could have wide-ranging implications for industrial automation and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
0
MVSA-Net: Multi-View State-Action Recognition for Robust and Deployable Trajectory Generation
Ehsan Asali, Prashant Doshi, Jin Sun
The learn-from-observation (LfO) paradigm is a human-inspired mode for a robot to learn to perform a task simply by watching it being performed. LfO can facilitate robot integration on factory floors by minimizing disruption and reducing tedious programming. A key component of the LfO pipeline is a transformation of the depth camera frames to the corresponding task state and action pairs, which are then relayed to learning techniques such as imitation or inverse reinforcement learning for understanding the task parameters. While several existing computer vision models analyze videos for activity recognition, SA-Net specifically targets robotic LfO from RGB-D data. However, SA-Net and many other models analyze frame data captured from a single viewpoint. Their analysis is therefore highly sensitive to occlusions of the observed task, which are frequent in deployments. An obvious way of reducing occlusions is to simultaneously observe the task from multiple viewpoints and synchronously fuse the multiple streams in the model. Toward this, we present multi-view SA-Net, which generalizes the SA-Net model to allow the perception of multiple viewpoints of the task activity, integrate them, and better recognize the state and action in each frame. Performance evaluations on two distinct domains establish that MVSA-Net recognizes the state-action pairs under occlusion more accurately compared to single-view MVSA-Net and other baselines. Our ablation studies further evaluate its performance under different ambient conditions and establish the contribution of the architecture components. As such, MVSA-Net offers a significantly more robust and deployable state-action trajectory generation compared to previous methods.
Read more4/9/2024
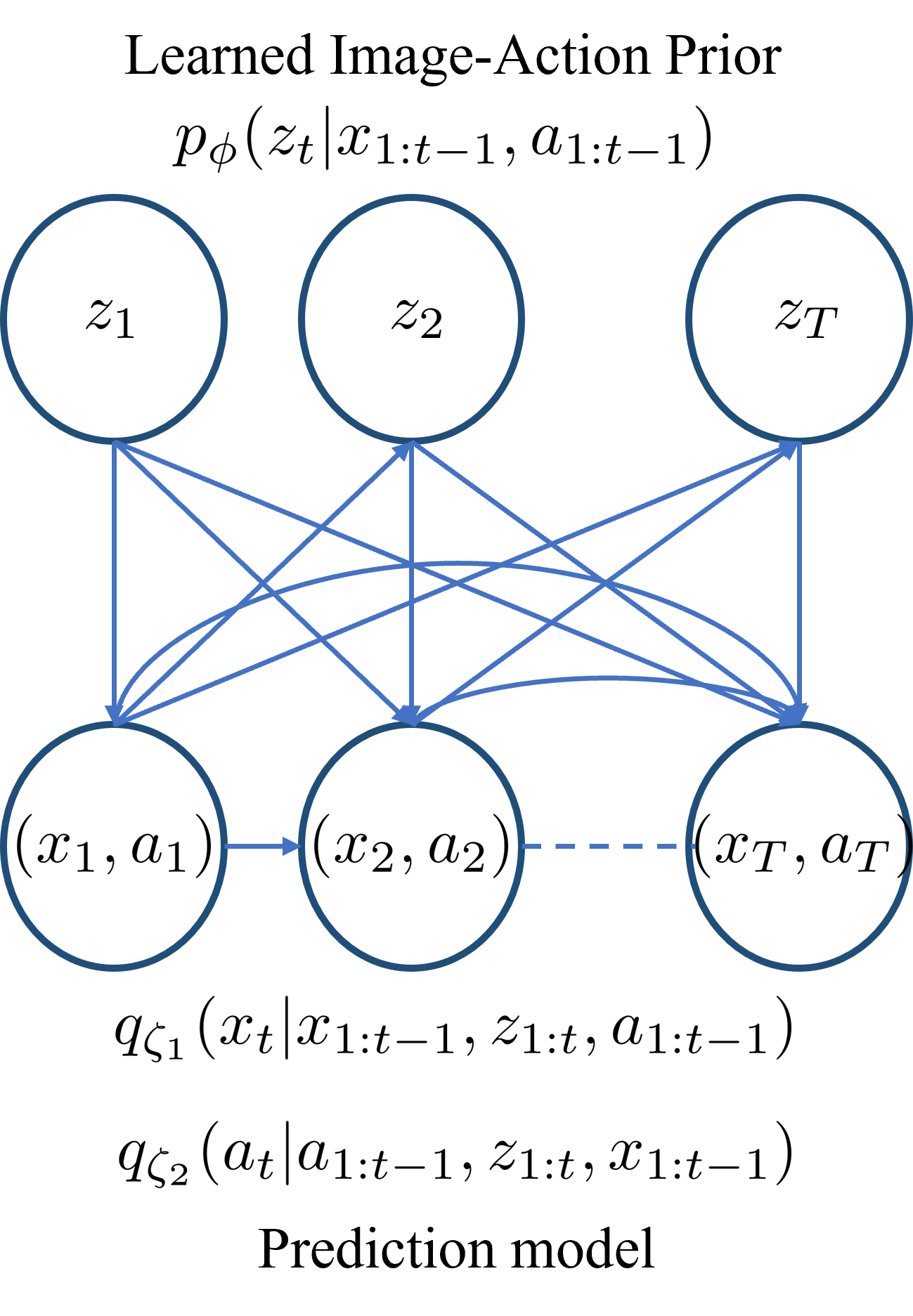
0
Video Generation with Learned Action Prior
Meenakshi Sarkar, Devansh Bhardwaj, Debasish Ghose
Stochastic video generation is particularly challenging when the camera is mounted on a moving platform, as camera motion interacts with observed image pixels, creating complex spatio-temporal dynamics and making the problem partially observable. Existing methods typically address this by focusing on raw pixel-level image reconstruction without explicitly modelling camera motion dynamics. We propose a solution by considering camera motion or action as part of the observed image state, modelling both image and action within a multi-modal learning framework. We introduce three models: Video Generation with Learning Action Prior (VG-LeAP) treats the image-action pair as an augmented state generated from a single latent stochastic process and uses variational inference to learn the image-action latent prior; Causal-LeAP, which establishes a causal relationship between action and the observed image frame at time $t$, learning an action prior conditioned on the observed image states; and RAFI, which integrates the augmented image-action state concept into flow matching with diffusion generative processes, demonstrating that this action-conditioned image generation concept can be extended to other diffusion-based models. We emphasize the importance of multi-modal training in partially observable video generation problems through detailed empirical studies on our new video action dataset, RoAM.
Read more6/21/2024

0
Self-supervised Multi-actor Social Activity Understanding in Streaming Videos
Shubham Trehan, Sathyanarayanan N. Aakur
This work addresses the problem of Social Activity Recognition (SAR), a critical component in real-world tasks like surveillance and assistive robotics. Unlike traditional event understanding approaches, SAR necessitates modeling individual actors' appearance and motions and contextualizing them within their social interactions. Traditional action localization methods fall short due to their single-actor, single-action assumption. Previous SAR research has relied heavily on densely annotated data, but privacy concerns limit their applicability in real-world settings. In this work, we propose a self-supervised approach based on multi-actor predictive learning for SAR in streaming videos. Using a visual-semantic graph structure, we model social interactions, enabling relational reasoning for robust performance with minimal labeled data. The proposed framework achieves competitive performance on standard group activity recognition benchmarks. Evaluation on three publicly available action localization benchmarks demonstrates its generalizability to arbitrary action localization.
Read more6/21/2024
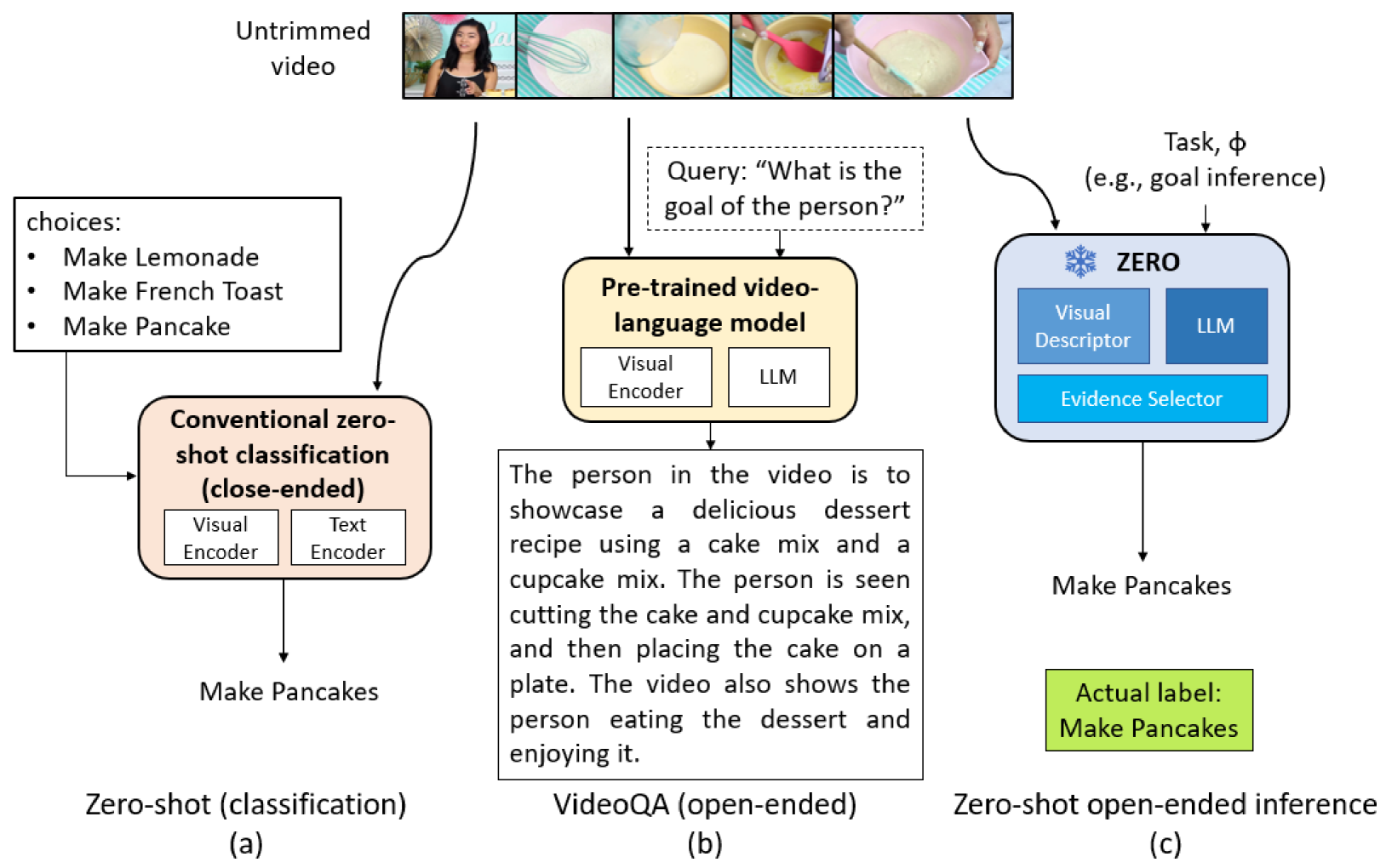
0
Training-Free Action Recognition and Goal Inference with Dynamic Frame Selection
Ee Yeo Keat, Zhang Hao, Alexander Matyasko, Basura Fernando
We introduce VidTFS, a Training-free, open-vocabulary video goal and action inference framework that combines the frozen vision foundational model (VFM) and large language model (LLM) with a novel dynamic Frame Selection module. Our experiments demonstrate that the proposed frame selection module improves the performance of the framework significantly. We validate the performance of the proposed VidTFS on four widely used video datasets, including CrossTask, COIN, UCF101, and ActivityNet, covering goal inference and action recognition tasks under open-vocabulary settings without requiring any training or fine-tuning. The results show that VidTFS outperforms pretrained and instruction-tuned multimodal language models that directly stack LLM and VFM for downstream video inference tasks. Our VidTFS with its adaptability shows the future potential for generalizing to new training-free video inference tasks.
Read more8/29/2024