Noisy Node Classification by Bi-level Optimization based Multi-teacher Distillation

0

Sign in to get full access
Overview
- This paper proposes a novel approach for node classification in noisy graph data using a multi-teacher distillation framework and bi-level optimization.
- The method leverages the knowledge of multiple teacher models to guide the training of a more robust student model, while also addressing the challenge of noisy labels in the input data.
- The authors demonstrate the effectiveness of their approach through experiments on several real-world graph datasets, showing improvements over state-of-the-art methods for node classification in the presence of noisy labels.
Plain English Explanation
In many real-world scenarios, the data we have for training machine learning models may contain errors or noise. This can be a significant challenge, especially when working with graph-structured data, where the connections between nodes (e.g., people in a social network) can also be noisy or unreliable.
The authors of this paper have developed a new method to address this problem. Their approach involves training multiple "teacher" models, each of which has been designed to focus on different aspects of the data. These teacher models then work together to guide the training of a single, more robust "student" model, which is better able to handle the noisy labels and connections in the input data.
The key innovation of this method is the use of a "bi-level optimization" approach, which allows the student model to learn from the combined knowledge of the teacher models, while also adapting to the specific characteristics of the input data. This helps the student model to become more accurate and reliable, even in the presence of noisy or unreliable information.
The authors have tested their method on several real-world graph datasets, and have shown that it outperforms other state-of-the-art techniques for node classification in noisy settings. This suggests that their approach could be useful for a wide range of applications, from social network analysis to recommendation systems, where the input data may be imperfect or incomplete.
Technical Explanation
The proposed method, known as "Noisy Node Classification by Bi-level Optimization based Multi-teacher Distillation" (NNCBMD), is a novel approach for addressing the problem of node classification in the presence of noisy labels and connections in graph-structured data.
At the core of NNCBMD is a multi-teacher distillation framework, where multiple teacher models are trained to capture different aspects of the input data. These teacher models are then used to guide the training of a single, more robust student model. The key innovation is the use of a bi-level optimization approach, which allows the student model to learn from the combined knowledge of the teacher models, while also adapting to the specific characteristics of the input data.
The NNCBMD method consists of two main stages: (1) training the teacher models, and (2) training the student model. In the first stage, the authors train multiple teacher models, each with a different architecture or learning objective, to capture diverse representations of the input data. In the second stage, the student model is trained using a bi-level optimization approach, where the upper-level objective is to minimize the loss of the student model on the clean (non-noisy) data, and the lower-level objective is to minimize the loss of the student model on the noisy data, guided by the outputs of the teacher models.
The authors evaluate their approach on several real-world graph datasets, including link to "Graph Convolutional Network for Semi-supervised Node Classification", link to "Cluster-based Graph Collaborative Filtering", and link to "Decouple Graph Neural Networks for Train-time Multiple Simple Graphs". The results show that NNCBMD outperforms state-of-the-art methods for node classification in the presence of noisy labels and connections, demonstrating the effectiveness of the bi-level optimization-based multi-teacher distillation approach.
Critical Analysis
The NNCBMD method presents a promising approach for addressing the challenge of noisy data in graph-structured settings. By leveraging the combined knowledge of multiple teacher models, the student model is able to learn more robust and reliable representations, even when the input data is imperfect.
One potential limitation of the method is the complexity of the bi-level optimization approach, which may be computationally intensive and require careful tuning of hyperparameters. Additionally, the authors do not explore the scalability of their method to larger graph datasets or more complex graph structures, which could be an important consideration for real-world applications.
Moreover, the authors do not provide a detailed analysis of the types of noise or label errors that their method is most effective at handling. It would be valuable to understand the specific characteristics of the input data that NNCBMD is best suited for, as well as any potential weaknesses or failure modes of the approach.
Despite these potential limitations, the overall approach presented in this paper represents a significant advancement in the field of graph-based machine learning, and the authors' demonstration of its effectiveness on real-world datasets is a notable contribution. Researchers and practitioners working on link to "Improve Knowledge Distillation via Label Revision and Data Augmentation" and link to "Trusted Multi-view Learning for Label Noise" may find the NNCBMD method particularly relevant and inspiring for their own work.
Conclusion
The NNCBMD method proposed in this paper offers a novel and effective approach for addressing the challenge of noisy labels and connections in graph-structured data. By leveraging a multi-teacher distillation framework and a bi-level optimization strategy, the authors have developed a technique that can significantly improve the performance of node classification tasks, even in the presence of unreliable or erroneous input data.
The successful application of NNCBMD on several real-world graph datasets suggests that this method could have a wide range of practical applications, from social network analysis to recommendation systems. As researchers and practitioners continue to grapple with the complexities of working with imperfect data, the insights and innovations presented in this paper may prove invaluable in developing more robust and reliable machine learning solutions for graph-based problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Noisy Node Classification by Bi-level Optimization based Multi-teacher Distillation
Yujing Liu, Zongqian Wu, Zhengyu Lu, Ci Nie, Guoqiu Wen, Ping Hu, Xiaofeng Zhu
Previous graph neural networks (GNNs) usually assume that the graph data is with clean labels for representation learning, but it is not true in real applications. In this paper, we propose a new multi-teacher distillation method based on bi-level optimization (namely BO-NNC), to conduct noisy node classification on the graph data. Specifically, we first employ multiple self-supervised learning methods to train diverse teacher models, and then aggregate their predictions through a teacher weight matrix. Furthermore, we design a new bi-level optimization strategy to dynamically adjust the teacher weight matrix based on the training progress of the student model. Finally, we design a label improvement module to improve the label quality. Extensive experimental results on real datasets show that our method achieves the best results compared to state-of-the-art methods.
Read more5/9/2024

0
Graph Knowledge Distillation to Mixture of Experts
Pavel Rumiantsev, Mark Coates
In terms of accuracy, Graph Neural Networks (GNNs) are the best architectural choice for the node classification task. Their drawback in real-world deployment is the latency that emerges from the neighbourhood processing operation. One solution to the latency issue is to perform knowledge distillation from a trained GNN to a Multi-Layer Perceptron (MLP), where the MLP processes only the features of the node being classified (and possibly some pre-computed structural information). However, the performance of such MLPs in both transductive and inductive settings remains inconsistent for existing knowledge distillation techniques. We propose to address the performance concerns by using a specially-designed student model instead of an MLP. Our model, named Routing-by-Memory (RbM), is a form of Mixture-of-Experts (MoE), with a design that enforces expert specialization. By encouraging each expert to specialize on a certain region on the hidden representation space, we demonstrate experimentally that it is possible to derive considerably more consistent performance across multiple datasets.
Read more6/19/2024
🏷️
0
Article Classification with Graph Neural Networks and Multigraphs
Khang Ly, Yury Kashnitsky, Savvas Chamezopoulos, Valeria Krzhizhanovskaya
Classifying research output into context-specific label taxonomies is a challenging and relevant downstream task, given the volume of existing and newly published articles. We propose a method to enhance the performance of article classification by enriching simple Graph Neural Network (GNN) pipelines with multi-graph representations that simultaneously encode multiple signals of article relatedness, e.g. references, co-authorship, shared publication source, shared subject headings, as distinct edge types. Fully supervised transductive node classification experiments are conducted on the Open Graph Benchmark OGBN-arXiv dataset and the PubMed diabetes dataset, augmented with additional metadata from Microsoft Academic Graph and PubMed Central, respectively. The results demonstrate that multi-graphs consistently improve the performance of a variety of GNN models compared to the default graphs. When deployed with SOTA textual node embedding methods, the transformed multi-graphs enable simple and shallow 2-layer GNN pipelines to achieve results on par with more complex architectures.
Read more5/29/2024
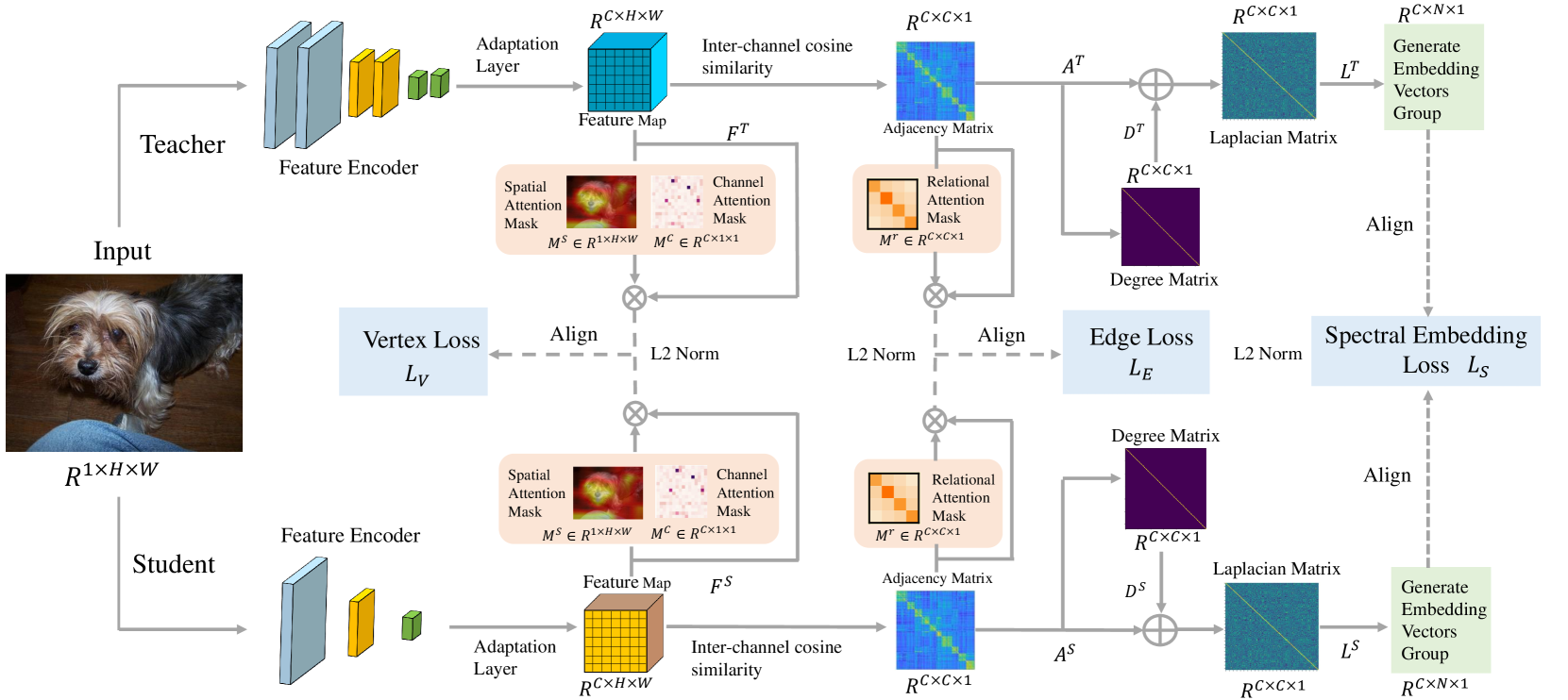
0
Exploring Graph-based Knowledge: Multi-Level Feature Distillation via Channels Relational Graph
Zhiwei Wang, Jun Huang, Longhua Ma, Chengyu Wu, Hongyu Ma
In visual tasks, large teacher models capture essential features and deep information, enhancing performance. However, distilling this information into smaller student models often leads to performance loss due to structural differences and capacity limitations. To tackle this, we propose a distillation framework based on graph knowledge, including a multi-level feature alignment strategy and an attention-guided mechanism to provide a targeted learning trajectory for the student model. We emphasize spectral embedding (SE) as a key technique in our distillation process, which merges the student's feature space with the relational knowledge and structural complexities similar to the teacher network. This method captures the teacher's understanding in a graph-based representation, enabling the student model to more accurately mimic the complex structural dependencies present in the teacher model. Compared to methods that focus only on specific distillation areas, our strategy not only considers key features within the teacher model but also endeavors to capture the relationships and interactions among feature sets, encoding these complex pieces of information into a graph structure to understand and utilize the dynamic relationships among these pieces of information from a global perspective. Experiments show that our method outperforms previous feature distillation methods on the CIFAR-100, MS-COCO, and Pascal VOC datasets, proving its efficiency and applicability.
Read more5/17/2024