Nostra Domina at EvaLatin 2024: Improving Latin Polarity Detection through Data Augmentation

0

Sign in to get full access
Overview
- The paper presents a method for improving Latin polarity detection through data augmentation.
- The authors developed a model called "Nostra Domina" that was tested on the EvaLatin 2024 dataset.
- The key contributions include automatic annotation of the dataset and leveraging data augmentation techniques to enhance the model's performance.
Plain English Explanation
The paper focuses on improving the ability of artificial intelligence (AI) systems to detect the sentiment or "polarity" (positive or negative) of text written in Latin. This is an important task for understanding and analyzing historical Latin documents and literature.
The researchers created a new AI model called "Nostra Domina" and tested it on a dataset of Latin text called EvaLatin 2024. To improve the model's performance, they developed a technique called "data augmentation", which involves creating additional training data by making small, controlled modifications to the existing data.
By using this data augmentation approach, the researchers were able to significantly enhance the model's ability to accurately detect the polarity (positive or negative sentiment) in Latin text. This is an important step forward in the field of natural language processing for historical languages like Latin.
Technical Explanation
The paper describes the development of a new model called "Nostra Domina" for the task of Latin polarity detection, which was evaluated on the EvaLatin 2024 dataset. A key contribution of the work is the authors' approach to automatically annotating the dataset to create training data for the model.
To further improve the model's performance, the researchers leveraged data augmentation techniques, such as synonym replacement and back-translation. This helps the model generalize better by exposing it to a greater diversity of training examples.
The results show that the "Nostra Domina" model with data augmentation outperformed previous state-of-the-art approaches on the EvaLatin 2024 benchmark. The authors also discuss the potential for their techniques to be applied to other sentiment analysis tasks and other historical languages.
Critical Analysis
The paper provides a thorough explanation of the data augmentation techniques used and their impact on the model's performance. However, the authors could have explored additional data sources or model architectures to further improve the Nostra Domina model.
Additionally, the paper does not address potential biases in the automatically annotated training data or the implications of deploying such a system in real-world applications. More discussion on the ethical considerations and limitations of the approach would have strengthened the critical analysis.
Conclusion
The Nostra Domina model, combined with data augmentation, represents a significant advancement in the field of Latin polarity detection. By leveraging innovative techniques to enhance the training data, the researchers have demonstrated the potential to improve the performance of natural language processing models for historical languages.
This work lays the foundation for further research into sentiment analysis for Latin and other under-resourced languages. The insights gained from this study could also be applied to other text classification tasks, contributing to the broader goal of making AI systems more accurate and robust.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Nostra Domina at EvaLatin 2024: Improving Latin Polarity Detection through Data Augmentation
Stephen Bothwell, Abigail Swenor, David Chiang
This paper describes submissions from the team Nostra Domina to the EvaLatin 2024 shared task of emotion polarity detection. Given the low-resource environment of Latin and the complexity of sentiment in rhetorical genres like poetry, we augmented the available data through automatic polarity annotation. We present two methods for doing so on the basis of the $k$-means algorithm, and we employ a variety of Latin large language models (LLMs) in a neural architecture to better capture the underlying contextual sentiment representations. Our best approach achieved the second highest macro-averaged Macro-$F_1$ score on the shared task's test set.
Read more4/12/2024

0
TartuNLP at EvaLatin 2024: Emotion Polarity Detection
Aleksei Dorkin, Kairit Sirts
This paper presents the TartuNLP team submission to EvaLatin 2024 shared task of the emotion polarity detection for historical Latin texts. Our system relies on two distinct approaches to annotating training data for supervised learning: 1) creating heuristics-based labels by adopting the polarity lexicon provided by the organizers and 2) generating labels with GPT4. We employed parameter efficient fine-tuning using the adapters framework and experimented with both monolingual and cross-lingual knowledge transfer for training language and task adapters. Our submission with the LLM-generated labels achieved the overall first place in the emotion polarity detection task. Our results show that LLM-based annotations show promising results on texts in Latin.
Read more5/3/2024

0
BSC-UPC at EmoSPeech-IberLEF2024: Attention Pooling for Emotion Recognition
Marc Casals-Salvador, Federico Costa, Miquel India, Javier Hernando
The domain of speech emotion recognition (SER) has persistently been a frontier within the landscape of machine learning. It is an active field that has been revolutionized in the last few decades and whose implementations are remarkable in multiple applications that could affect daily life. Consequently, the Iberian Languages Evaluation Forum (IberLEF) of 2024 held a competitive challenge to leverage the SER results with a Spanish corpus. This paper presents the approach followed with the goal of participating in this competition. The main architecture consists of different pre-trained speech and text models to extract features from both modalities, utilizing an attention pooling mechanism. The proposed system has achieved the first position in the challenge with an 86.69% in Macro F1-Score.
Read more7/18/2024
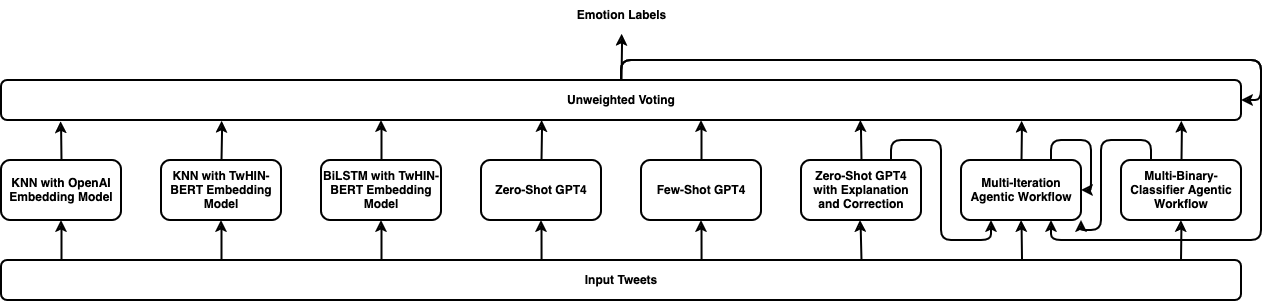
0
TEII: Think, Explain, Interact and Iterate with Large Language Models to Solve Cross-lingual Emotion Detection
Long Cheng, Qihao Shao, Christine Zhao, Sheng Bi, Gina-Anne Levow
Cross-lingual emotion detection allows us to analyze global trends, public opinion, and social phenomena at scale. We participated in the Explainability of Cross-lingual Emotion Detection (EXALT) shared task, achieving an F1-score of 0.6046 on the evaluation set for the emotion detection sub-task. Our system outperformed the baseline by more than 0.16 F1-score absolute, and ranked second amongst competing systems. We conducted experiments using fine-tuning, zero-shot learning, and few-shot learning for Large Language Model (LLM)-based models as well as embedding-based BiLSTM and KNN for non-LLM-based techniques. Additionally, we introduced two novel methods: the Multi-Iteration Agentic Workflow and the Multi-Binary-Classifier Agentic Workflow. We found that LLM-based approaches provided good performance on multilingual emotion detection. Furthermore, ensembles combining all our experimented models yielded higher F1-scores than any single approach alone.
Read more5/28/2024