Nuance Matters: Probing Epistemic Consistency in Causal Reasoning

0

Sign in to get full access
Overview
- This paper investigates how well large language models (LLMs) can reason about causal relationships and maintain logical consistency.
- The authors introduce a novel task called "Nuanced Causal Reasoning" to probe the epistemic consistency of LLMs.
- They find that despite impressive capabilities, LLMs often exhibit logical inconsistencies and flaws in causal reasoning.
- The research highlights the importance of developing more robust and consistent reasoning abilities in advanced AI systems.
Plain English Explanation
The paper examines how well large language models can understand and reason about cause-and-effect relationships. The authors created a new task called "Nuanced Causal Reasoning" to test the models' ability to maintain logical consistency when answering questions that require causal reasoning.
Despite the impressive capabilities of these language models, the research found that they often exhibit logical inconsistencies and make mistakes when it comes to causal reasoning. For example, a model might correctly identify a causal relationship in one context, but then contradict itself or make illogical inferences in a different context.
This work highlights the importance of developing more robust and consistent reasoning abilities in advanced AI systems. While these models can accomplish many impressive feats, the paper suggests there is still significant room for improvement when it comes to causal understanding and maintaining logical coherence across different scenarios.
Technical Explanation
The paper introduces a novel task called "Nuanced Causal Reasoning" to probe the epistemic consistency of large language models in causal reasoning. The task presents models with a series of questions that require understanding and reasoning about causal relationships in a nuanced way.
For example, a question might ask about the causal relationship between two events, and then later present a slightly modified scenario and ask the model to reason about the causal relationships again. The goal is to test whether the model can maintain logical consistency in its causal inferences across these related contexts.
The authors evaluate several state-of-the-art language models on this task and find that despite their impressive performance on other benchmarks, the models often exhibit logical inconsistencies and flaws in their causal reasoning abilities. The results suggest that even advanced AI systems struggle to reason about causality in a fully coherent and epistemically consistent manner.
Critical Analysis
The paper raises important points about the limitations of current large language models when it comes to causal reasoning and logical consistency. While these models have achieved remarkable successes in many areas, the authors demonstrate that there are still significant challenges in developing AI systems that can reason about causality in a nuanced and logically coherent way.
One potential criticism is that the "Nuanced Causal Reasoning" task may be quite challenging and not fully representative of real-world causal reasoning demands. The authors acknowledge this limitation and suggest that further research is needed to better understand the boundaries of current models' causal reasoning capabilities.
Additionally, the paper does not explore potential solutions or approaches for improving the logical consistency and causal reasoning abilities of large language models. Further research into model architectures, training techniques, or knowledge representation methods that could address these shortcomings would be a valuable next step.
Conclusion
This paper provides important insights into the limitations of large language models when it comes to causal reasoning and logical consistency. Despite their impressive capabilities, the research demonstrates that these models still struggle to maintain coherent and consistent causal inferences across different contexts.
The findings underscore the need for continued progress in developing AI systems with more robust and reliable reasoning abilities, particularly when it comes to understanding and reasoning about cause-and-effect relationships. As the use of these models continues to expand, ensuring their causal reasoning is logically consistent will be crucial for their safe and effective deployment in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Nuance Matters: Probing Epistemic Consistency in Causal Reasoning
Shaobo Cui, Junyou Li, Luca Mouchel, Yiyang Feng, Boi Faltings
To address this gap, our study introduces the concept of causal epistemic consistency, which focuses on the self-consistency of Large Language Models (LLMs) in differentiating intermediates with nuanced differences in causal reasoning. We propose a suite of novel metrics -- intensity ranking concordance, cross-group position agreement, and intra-group clustering -- to evaluate LLMs on this front. Through extensive empirical studies on 21 high-profile LLMs, including GPT-4, Claude3, and LLaMA3-70B, we have favoring evidence that current models struggle to maintain epistemic consistency in identifying the polarity and intensity of intermediates in causal reasoning. Additionally, we explore the potential of using internal token probabilities as an auxiliary tool to maintain causal epistemic consistency. In summary, our study bridges a critical gap in AI research by investigating the self-consistency over fine-grained intermediates involved in causal reasoning.
Read more9/4/2024
0
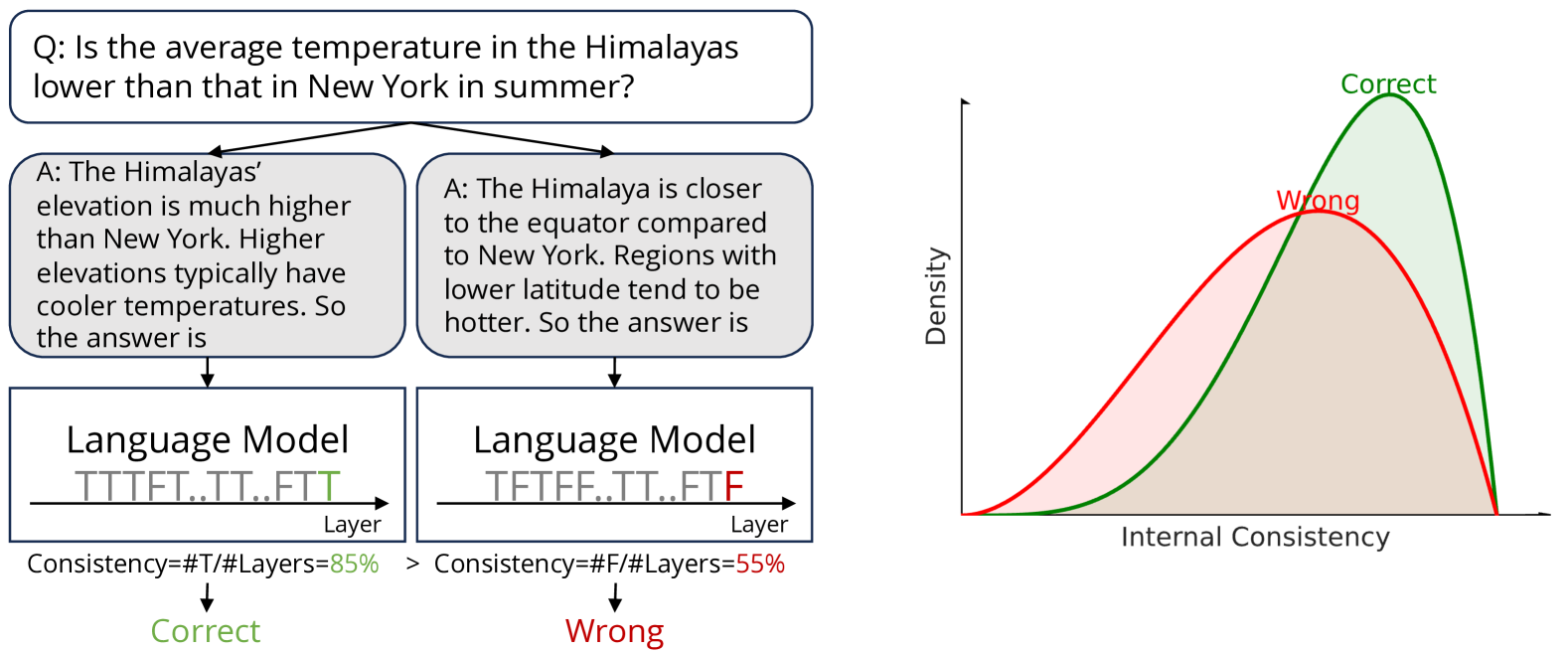
Calibrating Reasoning in Language Models with Internal Consistency
Zhihui Xie, Jizhou Guo, Tong Yu, Shuai Li
Large language models (LLMs) have demonstrated impressive capabilities in various reasoning tasks, aided by techniques like chain-of-thought (CoT) prompting that elicits verbalized reasoning. However, LLMs often generate text with obvious mistakes and contradictions, raising doubts about their ability to robustly process and utilize generated rationales. In this work, we investigate CoT reasoning in LLMs through the lens of internal representations, focusing on how these representations are influenced by generated rationales. Our preliminary analysis reveals that while generated rationales improve answer accuracy, inconsistencies emerge between the model's internal representations in middle layers and those in final layers, potentially undermining the reliability of their reasoning processes. To address this, we propose internal consistency as a measure of the model's confidence by examining the agreement of latent predictions decoded from intermediate layers. Extensive empirical studies across different models and datasets demonstrate that internal consistency effectively distinguishes between correct and incorrect reasoning paths. Motivated by this, we propose a new approach to calibrate CoT reasoning by up-weighting reasoning paths with high internal consistency, resulting in a significant boost in reasoning performance. Further analysis uncovers distinct patterns in attention and feed-forward modules across layers, providing insights into the emergence of internal inconsistency. In summary, our results demonstrate the potential of using internal representations for self-evaluation of LLMs.
Read more5/30/2024
💬
0
Evaluating Consistency and Reasoning Capabilities of Large Language Models
Yash Saxena, Sarthak Chopra, Arunendra Mani Tripathi
Large Language Models (LLMs) are extensively used today across various sectors, including academia, research, business, and finance, for tasks such as text generation, summarization, and translation. Despite their widespread adoption, these models often produce incorrect and misleading information, exhibiting a tendency to hallucinate. This behavior can be attributed to several factors, with consistency and reasoning capabilities being significant contributors. LLMs frequently lack the ability to generate explanations and engage in coherent reasoning, leading to inaccurate responses. Moreover, they exhibit inconsistencies in their outputs. This paper aims to evaluate and compare the consistency and reasoning capabilities of both public and proprietary LLMs. The experiments utilize the Boolq dataset as the ground truth, comprising questions, answers, and corresponding explanations. Queries from the dataset are presented as prompts to the LLMs, and the generated responses are evaluated against the ground truth answers. Additionally, explanations are generated to assess the models' reasoning abilities. Consistency is evaluated by repeatedly presenting the same query to the models and observing for variations in their responses. For measuring reasoning capabilities, the generated explanations are compared to the ground truth explanations using metrics such as BERT, BLEU, and F-1 scores. The findings reveal that proprietary models generally outperform public models in terms of both consistency and reasoning capabilities. However, even when presented with basic general knowledge questions, none of the models achieved a score of 90% in both consistency and reasoning. This study underscores the direct correlation between consistency and reasoning abilities in LLMs and highlights the inherent reasoning challenges present in current language models.
Read more4/26/2024
0
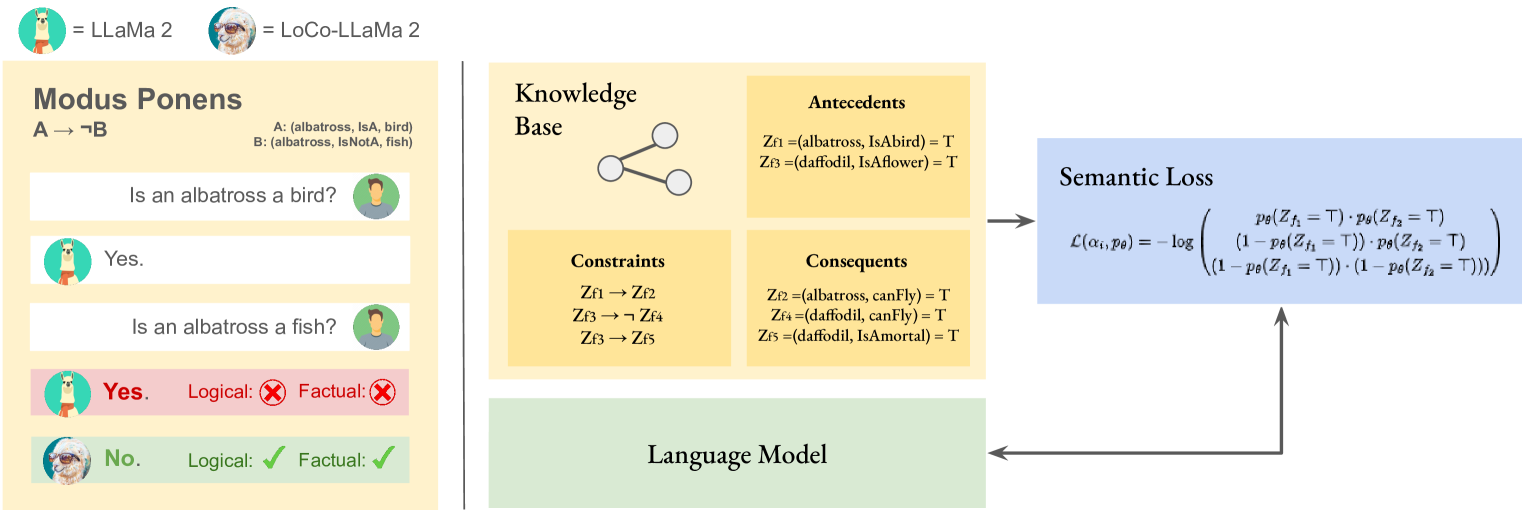
Towards Logically Consistent Language Models via Probabilistic Reasoning
Diego Calanzone, Stefano Teso, Antonio Vergari
Large language models (LLMs) are a promising venue for natural language understanding and generation tasks. However, current LLMs are far from reliable: they are prone to generate non-factual information and, more crucially, to contradict themselves when prompted to reason about beliefs of the world. These problems are currently addressed with large scale fine-tuning or by delegating consistent reasoning to external tools. In this work, we strive for a middle ground and introduce a training objective based on principled probabilistic reasoning that teaches a LLM to be consistent with external knowledge in the form of a set of facts and rules. Fine-tuning with our loss on a limited set of facts enables our LLMs to be more logically consistent than previous baselines and allows them to extrapolate to unseen but semantically similar factual knowledge more systematically.
Read more4/22/2024