Object-Conditioned Energy-Based Attention Map Alignment in Text-to-Image Diffusion Models

0

Sign in to get full access
Overview
- This paper introduces a novel technique called "Object-Conditioned Energy-Based Attention Map Alignment" for improving text-to-image diffusion models.
- The key idea is to leverage object-level information to better align the attention maps between text and image during the diffusion process.
- This approach aims to enhance the interpretability and controllability of text-to-image generation models.
Plain English Explanation
Text-to-image diffusion models are a type of AI system that can generate images from text descriptions. However, these models can sometimes struggle to fully capture the intended objects and their relationships in the final image.
The researchers behind this paper developed a new technique to address this issue. They introduced "Object-Conditioned Energy-Based Attention Map Alignment," which uses information about the key objects mentioned in the text to better align the model's attention during the image generation process.
The core idea is that by focusing the model's attention on the relevant objects, it can produce images that more closely match the intended content described in the text. This makes the generated images more interpretable and gives users more control over the output.
Technical Explanation
The key innovation in this paper is the "Object-Conditioned Energy-Based Attention Map Alignment" approach. The researchers first extract object-level information from the text input using a pre-trained object detection model. They then use this object-level data to guide the attention mechanism in the text-to-image diffusion model.
Specifically, they define an "energy-based" loss function that encourages the attention maps in the diffusion model to align with the detected objects. This helps ensure that the model's attention is focused on the relevant parts of the image during generation.
The researchers evaluate their approach on several text-to-image benchmarks and show that it leads to improved performance and better alignment between the generated images and the input text, compared to standard diffusion models. The method also provides more interpretable and controllable results.
Critical Analysis
One potential limitation of this approach is that it relies on the accuracy of the pre-trained object detection model. If the object-level information extracted from the text is noisy or incomplete, it could negatively impact the performance of the attention alignment.
Additionally, the energy-based loss function introduces additional complexity and hyperparameters that need to be tuned, which could make the training process more challenging. The researchers do not provide a detailed ablation study on the sensitivity of their approach to these hyperparameters.
It would also be interesting to see how this technique compares to other methods for improving text-to-image alignment, such as COMAT, BAMM, or Attention Calibration.
Conclusion
This paper presents a novel approach to improving text-to-image diffusion models by leveraging object-level information to better align the attention maps during generation. The researchers demonstrate that their "Object-Conditioned Energy-Based Attention Map Alignment" technique can lead to more interpretable and controllable text-to-image generation.
While the approach has some potential limitations, it represents an interesting step forward in enhancing the capabilities and transparency of these powerful generative models. As the field of text-to-image synthesis continues to advance, techniques like this one may play an important role in making these systems more reliable and useful for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Object-Conditioned Energy-Based Attention Map Alignment in Text-to-Image Diffusion Models
Yasi Zhang, Peiyu Yu, Ying Nian Wu
Text-to-image diffusion models have shown great success in generating high-quality text-guided images. Yet, these models may still fail to semantically align generated images with the provided text prompts, leading to problems like incorrect attribute binding and/or catastrophic object neglect. Given the pervasive object-oriented structure underlying text prompts, we introduce a novel object-conditioned Energy-Based Attention Map Alignment (EBAMA) method to address the aforementioned problems. We show that an object-centric attribute binding loss naturally emerges by approximately maximizing the log-likelihood of a $z$-parameterized energy-based model with the help of the negative sampling technique. We further propose an object-centric intensity regularizer to prevent excessive shifts of objects attention towards their attributes. Extensive qualitative and quantitative experiments, including human evaluation, on several challenging benchmarks demonstrate the superior performance of our method over previous strong counterparts. With better aligned attention maps, our approach shows great promise in further enhancing the text-controlled image editing ability of diffusion models.
Read more4/12/2024
0
Towards Better Text-to-Image Generation Alignment via Attention Modulation
Yihang Wu, Xiao Cao, Kaixin Li, Zitan Chen, Haonan Wang, Lei Meng, Zhiyong Huang
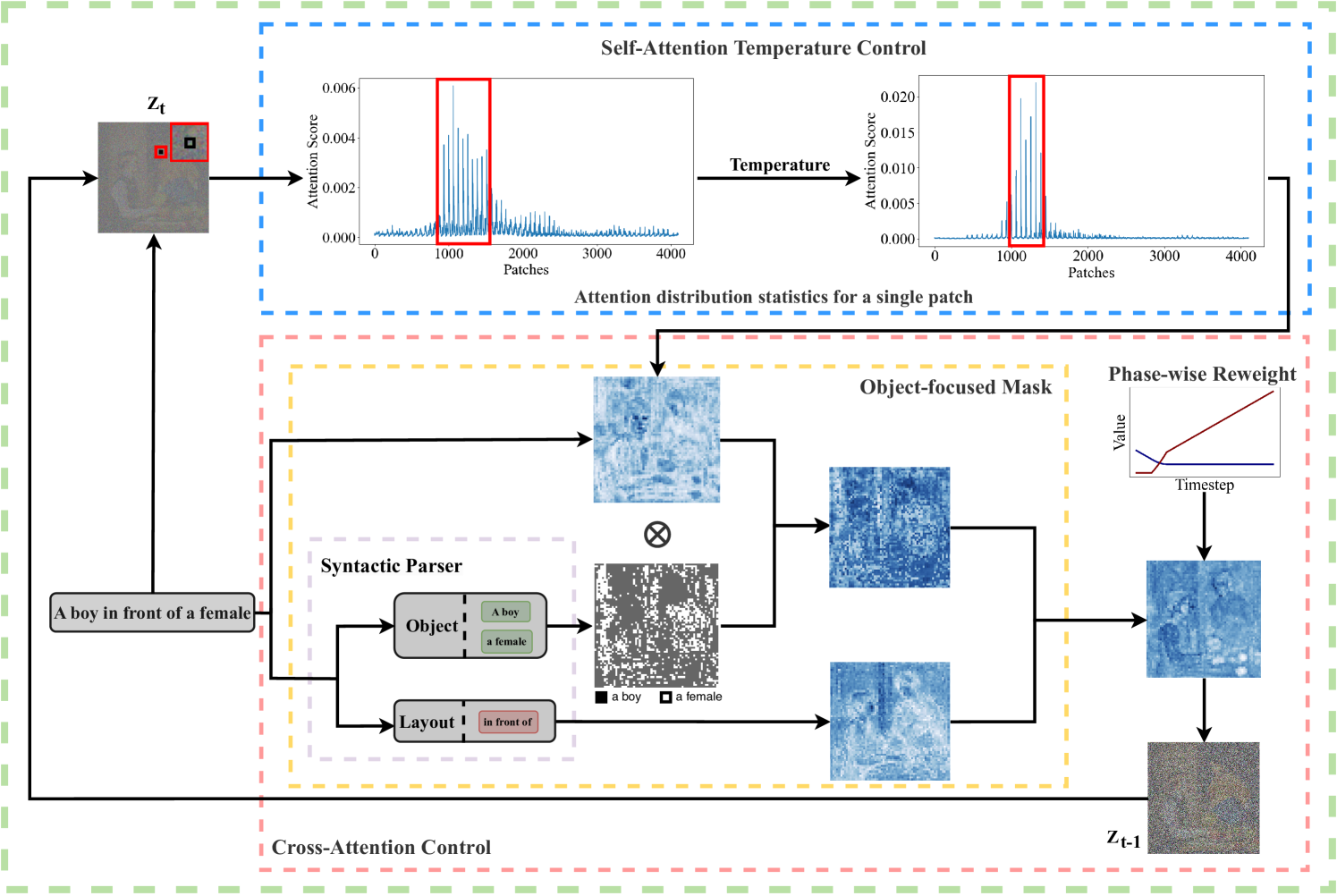
In text-to-image generation tasks, the advancements of diffusion models have facilitated the fidelity of generated results. However, these models encounter challenges when processing text prompts containing multiple entities and attributes. The uneven distribution of attention results in the issues of entity leakage and attribute misalignment. Training from scratch to address this issue requires numerous labeled data and is resource-consuming. Motivated by this, we propose an attribution-focusing mechanism, a training-free phase-wise mechanism by modulation of attention for diffusion model. One of our core ideas is to guide the model to concentrate on the corresponding syntactic components of the prompt at distinct timesteps. To achieve this, we incorporate a temperature control mechanism within the early phases of the self-attention modules to mitigate entity leakage issues. An object-focused masking scheme and a phase-wise dynamic weight control mechanism are integrated into the cross-attention modules, enabling the model to discern the affiliation of semantic information between entities more effectively. The experimental results in various alignment scenarios demonstrate that our model attain better image-text alignment with minimal additional computational cost.
Read more4/23/2024

0
Object-Attribute Binding in Text-to-Image Generation: Evaluation and Control
Maria Mihaela Trusca, Wolf Nuyts, Jonathan Thomm, Robert Honig, Thomas Hofmann, Tinne Tuytelaars, Marie-Francine Moens
Current diffusion models create photorealistic images given a text prompt as input but struggle to correctly bind attributes mentioned in the text to the right objects in the image. This is evidenced by our novel image-graph alignment model called EPViT (Edge Prediction Vision Transformer) for the evaluation of image-text alignment. To alleviate the above problem, we propose focused cross-attention (FCA) that controls the visual attention maps by syntactic constraints found in the input sentence. Additionally, the syntax structure of the prompt helps to disentangle the multimodal CLIP embeddings that are commonly used in T2I generation. The resulting DisCLIP embeddings and FCA are easily integrated in state-of-the-art diffusion models without additional training of these models. We show substantial improvements in T2I generation and especially its attribute-object binding on several datasets.footnote{Code and data will be made available upon acceptance.
Read more4/23/2024

0
I2AM: Interpreting Image-to-Image Latent Diffusion Models via Attribution Maps
Junseo Park, Hyeryung Jang
Large-scale diffusion models have made significant advancements in the field of image generation, especially through the use of cross-attention mechanisms that guide image formation based on textual descriptions. While the analysis of text-guided cross-attention in diffusion models has been extensively studied in recent years, its application in image-to-image diffusion models remains underexplored. This paper introduces the Image-to-Image Attribution Maps I2AM method, which aggregates patch-level cross-attention scores to enhance the interpretability of latent diffusion models across time steps, heads, and attention layers. I2AM facilitates detailed image-to-image attribution analysis, enabling observation of how diffusion models prioritize key features over time and head during the image generation process from reference images. Through extensive experiments, we first visualize the attribution maps of both generated and reference images, verifying that critical information from the reference image is effectively incorporated into the generated image, and vice versa. To further assess our understanding, we introduce a new evaluation metric tailored for reference-based image inpainting tasks. This metric, measuring the consistency between the attribution maps of generated and reference images, shows a strong correlation with established performance metrics for inpainting tasks, validating the potential use of I2AM in future research endeavors.
Read more7/18/2024