OED: Towards One-stage End-to-End Dynamic Scene Graph Generation

0

Sign in to get full access
Overview
- This paper introduces a new approach called OED (One-stage End-to-End Dynamic) for generating scene graphs from images in a single step.
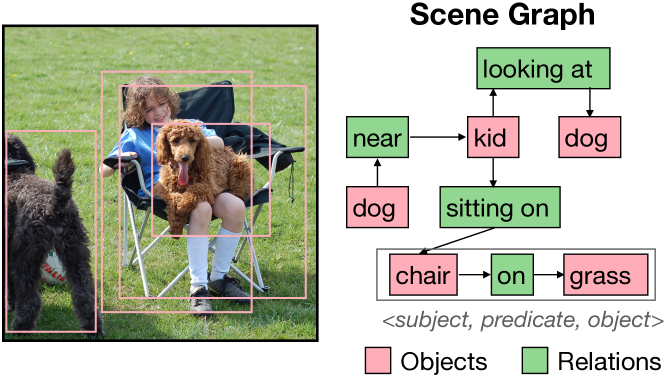
- Scene graphs are a way to represent the objects in an image and the relationships between them, which is useful for various computer vision tasks.
- Existing methods for generating scene graphs typically involve multiple stages, but the authors propose a one-stage end-to-end approach that aims to be more efficient and effective.
Plain English Explanation
The paper presents a new technique called OED (One-stage End-to-End Dynamic) for automatically creating scene graphs from images. Scene graphs are a way to represent the objects in an image and the relationships between them, which can be useful for tasks like image understanding and reasoning.
Generating scene graphs is a complex task, and previous methods have often required multiple steps or stages to complete. The authors of this paper propose a new approach that can do it all in a single step, from start to finish. This "one-stage end-to-end" design aims to be more efficient and effective than the multi-stage approaches used in the past.
The key idea behind OED is to combine the object detection, relationship prediction, and graph generation into a single neural network model. This allows the system to learn all the necessary skills simultaneously, rather than training separate models for each step. The authors claim this leads to better performance and faster processing times.
Overall, the OED method represents an important advance in the field of dynamic scene graph generation, which has important applications in areas like visual understanding and video analysis. By simplifying the process, the authors hope to make this technology more accessible and useful in real-world scenarios.
Technical Explanation
The OED approach combines object detection, relationship prediction, and graph generation into a single neural network model that can be trained end-to-end. This differs from previous methods that used separate models for each of these tasks.
The core architecture of OED consists of a backbone CNN encoder to extract visual features, followed by a set of task-specific heads. These include an object detection head to identify the objects in the image, a relationship prediction head to determine the connections between objects, and a graph generation head to assemble the final scene graph.
All of these components are trained jointly, allowing the model to learn the optimal representations and strategies for the overall scene graph generation task. The authors also introduce several novel techniques, such as a dynamic mask predictor and a learnable graph pool module, to improve the model's performance.
Experiments on standard benchmarks like Visual Genome and GQA show that OED achieves state-of-the-art results, outperforming previous multi-stage approaches. The one-stage design also leads to faster inference times, making the system more suitable for real-time applications.
Critical Analysis
One potential limitation of the OED approach is that it may struggle with very complex or crowded scenes, where accurately detecting all the objects and their relationships becomes increasingly challenging. The paper does not extensively explore the model's performance on such "in-the-wild" scenarios.
Additionally, the OED model is quite large and computationally intensive, which could limit its deployment on resource-constrained platforms like mobile devices. The authors mention plans to explore more efficient architecture designs in future work.
Another area for further research is the interpretability and explainability of the OED model's predictions. Since it is an end-to-end system, it may be more difficult to understand the reasoning behind its outputs, which could be important for certain applications.
Overall, the OED method represents a significant step forward in the field of dynamic scene graph generation, and the authors have made a compelling case for the benefits of their one-stage approach. However, as with any new technique, there is room for continued refinement and exploration of its strengths and limitations.
Conclusion
The OED (One-stage End-to-End Dynamic) method proposed in this paper offers a novel approach to the problem of scene graph generation from images. By combining all the necessary tasks - object detection, relationship prediction, and graph construction - into a single end-to-end model, the authors have demonstrated significant improvements in efficiency and effectiveness compared to previous multi-stage techniques.
The strong performance of OED on standard benchmarks suggests that this one-stage design could have a transformative impact on various computer vision applications that rely on scene understanding, from visual reasoning to video analysis. As the field continues to evolve, the principles and insights behind OED are likely to inspire further innovations in the quest for more powerful and versatile scene graph generation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
OED: Towards One-stage End-to-End Dynamic Scene Graph Generation
Guan Wang, Zhimin Li, Qingchao Chen, Yang Liu
Dynamic Scene Graph Generation (DSGG) focuses on identifying visual relationships within the spatial-temporal domain of videos. Conventional approaches often employ multi-stage pipelines, which typically consist of object detection, temporal association, and multi-relation classification. However, these methods exhibit inherent limitations due to the separation of multiple stages, and independent optimization of these sub-problems may yield sub-optimal solutions. To remedy these limitations, we propose a one-stage end-to-end framework, termed OED, which streamlines the DSGG pipeline. This framework reformulates the task as a set prediction problem and leverages pair-wise features to represent each subject-object pair within the scene graph. Moreover, another challenge of DSGG is capturing temporal dependencies, we introduce a Progressively Refined Module (PRM) for aggregating temporal context without the constraints of additional trackers or handcrafted trajectories, enabling end-to-end optimization of the network. Extensive experiments conducted on the Action Genome benchmark demonstrate the effectiveness of our design. The code and models are available at url{https://github.com/guanw-pku/OED}.
Read more5/28/2024

0
Towards Scene Graph Anticipation
Rohith Peddi, Saksham Singh, Saurabh, Parag Singla, Vibhav Gogate
Spatio-temporal scene graphs represent interactions in a video by decomposing scenes into individual objects and their pair-wise temporal relationships. Long-term anticipation of the fine-grained pair-wise relationships between objects is a challenging problem. To this end, we introduce the task of Scene Graph Anticipation (SGA). We adapt state-of-the-art scene graph generation methods as baselines to anticipate future pair-wise relationships between objects and propose a novel approach SceneSayer. In SceneSayer, we leverage object-centric representations of relationships to reason about the observed video frames and model the evolution of relationships between objects. We take a continuous time perspective and model the latent dynamics of the evolution of object interactions using concepts of NeuralODE and NeuralSDE, respectively. We infer representations of future relationships by solving an Ordinary Differential Equation and a Stochastic Differential Equation, respectively. Extensive experimentation on the Action Genome dataset validates the efficacy of the proposed methods.
Read more7/22/2024
0
Adaptive Visual Scene Understanding: Incremental Scene Graph Generation
Naitik Khandelwal, Xiao Liu, Mengmi Zhang
Scene graph generation (SGG) involves analyzing images to extract meaningful information about objects and their relationships. Given the dynamic nature of the visual world, it becomes crucial for AI systems to detect new objects and establish their new relationships with existing objects. To address the lack of continual learning methodologies in SGG, we introduce the comprehensive Continual ScenE Graph Generation (CSEGG) dataset along with 3 learning scenarios and 8 evaluation metrics. Our research investigates the continual learning performances of existing SGG methods on the retention of previous object entities and relationships as they learn new ones. Moreover, we also explore how continual object detection enhances generalization in classifying known relationships on unknown objects. We conduct extensive experiments benchmarking and analyzing the classical two-stage SGG methods and the most recent transformer-based SGG methods in continual learning settings, and gain valuable insights into the CSEGG problem. We invite the research community to explore this emerging field of study.
Read more4/15/2024

0
4D Panoptic Scene Graph Generation
Jingkang Yang, Jun Cen, Wenxuan Peng, Shuai Liu, Fangzhou Hong, Xiangtai Li, Kaiyang Zhou, Qifeng Chen, Ziwei Liu
We are living in a three-dimensional space while moving forward through a fourth dimension: time. To allow artificial intelligence to develop a comprehensive understanding of such a 4D environment, we introduce 4D Panoptic Scene Graph (PSG-4D), a new representation that bridges the raw visual data perceived in a dynamic 4D world and high-level visual understanding. Specifically, PSG-4D abstracts rich 4D sensory data into nodes, which represent entities with precise location and status information, and edges, which capture the temporal relations. To facilitate research in this new area, we build a richly annotated PSG-4D dataset consisting of 3K RGB-D videos with a total of 1M frames, each of which is labeled with 4D panoptic segmentation masks as well as fine-grained, dynamic scene graphs. To solve PSG-4D, we propose PSG4DFormer, a Transformer-based model that can predict panoptic segmentation masks, track masks along the time axis, and generate the corresponding scene graphs via a relation component. Extensive experiments on the new dataset show that our method can serve as a strong baseline for future research on PSG-4D. In the end, we provide a real-world application example to demonstrate how we can achieve dynamic scene understanding by integrating a large language model into our PSG-4D system.
Read more5/17/2024