Open-World Visual Reasoning by a Neuro-Symbolic Program of Zero-Shot Symbols

0
Sign in to get full access
Overview
- This paper presents a neuro-symbolic programming approach for open-world visual reasoning that leverages zero-shot symbols.
- The research is supported by the TNO ERP APPL.AI program.
- The proposed method aims to enable robots to reason about and interact with the world in a more flexible and adaptable way.
Plain English Explanation
This research explores a new way for robots to understand and reason about the world around them. Traditionally, robots have been limited to a specific set of predefined tasks and objects they can recognize and interact with. However, the real world is much more complex and unpredictable, with countless objects, actions, and situations that a robot may encounter.
The researchers in this paper have developed a "neuro-symbolic" approach that combines the strengths of neural networks (which excel at recognizing patterns in data) and symbolic reasoning (which is better at logical inference and abstract thinking). This allows the robot to not only recognize familiar objects and actions, but also reason about new or unfamiliar ones using a flexible set of "zero-shot" symbols.
For example, if a robot encounters a new type of tool it has never seen before, it can use its understanding of the underlying properties and functions of tools to reason about how to interact with this new object, even without any prior experience with it. This open-world reasoning capability is a significant advancement in the field of robotics, as it enables robots to be more adaptable and capable of handling the complexities of the real world.
The research is supported by the TNO ERP APPL.AI program, which suggests that this work has practical applications in areas such as open-world robotics, zero-shot models, and language-vision integration.
Technical Explanation
The proposed approach combines neural networks and symbolic reasoning to enable open-world visual reasoning. The key components include:
-
Neuro-Symbolic Programming: The system integrates neural networks for perceptual processing with a symbolic reasoning engine for logical inference and knowledge representation.
-
Zero-Shot Symbols: The system can reason about novel objects, actions, and situations using a flexible set of "zero-shot" symbols that encode abstract concepts and properties, rather than being tied to specific instances.
-
Knowledge Representation: The system maintains a knowledge base of symbols, relationships, and rules that can be used to reason about the world in a more flexible and adaptable way.
The researchers evaluate their approach on a range of open-world visual reasoning tasks, including object-grounded visual commonsense reasoning, spatial language reasoning, and task planning in open-world environments. The results demonstrate the system's ability to reason about novel situations and outperform baseline approaches that rely on more limited, instance-based representations.
Critical Analysis
The paper presents a promising approach to open-world visual reasoning, but there are a few potential limitations and areas for further research:
-
Scalability: The knowledge representation and reasoning components of the system may become increasingly complex as the number of symbols, relationships, and rules grows. Scalability and efficient knowledge management will be essential for real-world deployment.
-
Bias and Generalization: Like any machine learning system, the neuro-symbolic approach may be susceptible to biases in the training data or knowledge base. Careful evaluation of the system's ability to generalize to diverse and novel situations will be important.
-
Real-World Deployment: While the paper demonstrates the system's capabilities in simulation and controlled environments, further research is needed to address the challenges of deploying such a system in the real world, where the environment is more complex and dynamic.
Overall, this research represents an exciting step forward in the field of open-world robotics and visual reasoning. By integrating neural networks and symbolic reasoning, the proposed approach shows promise for enabling more adaptable and capable robots that can better understand and interact with the complexities of the real world.
Conclusion
This paper presents a neuro-symbolic programming approach for open-world visual reasoning that leverages zero-shot symbols. The key innovation is the integration of neural networks and symbolic reasoning to enable robots to reason about novel objects, actions, and situations in a more flexible and adaptable way.
The research has significant implications for the field of robotics, as it suggests a path towards more capable and adaptable robots that can better navigate the complexities of the real world. While there are still some challenges to address, this work represents an important step forward in the quest to develop intelligent systems that can truly understand and interact with the world around them.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Open-World Visual Reasoning by a Neuro-Symbolic Program of Zero-Shot Symbols
Gertjan Burghouts, Fieke Hillerstrom, Erwin Walraven, Michael van Bekkum, Frank Ruis, Joris Sijs, Jelle van Mil, Judith Dijk
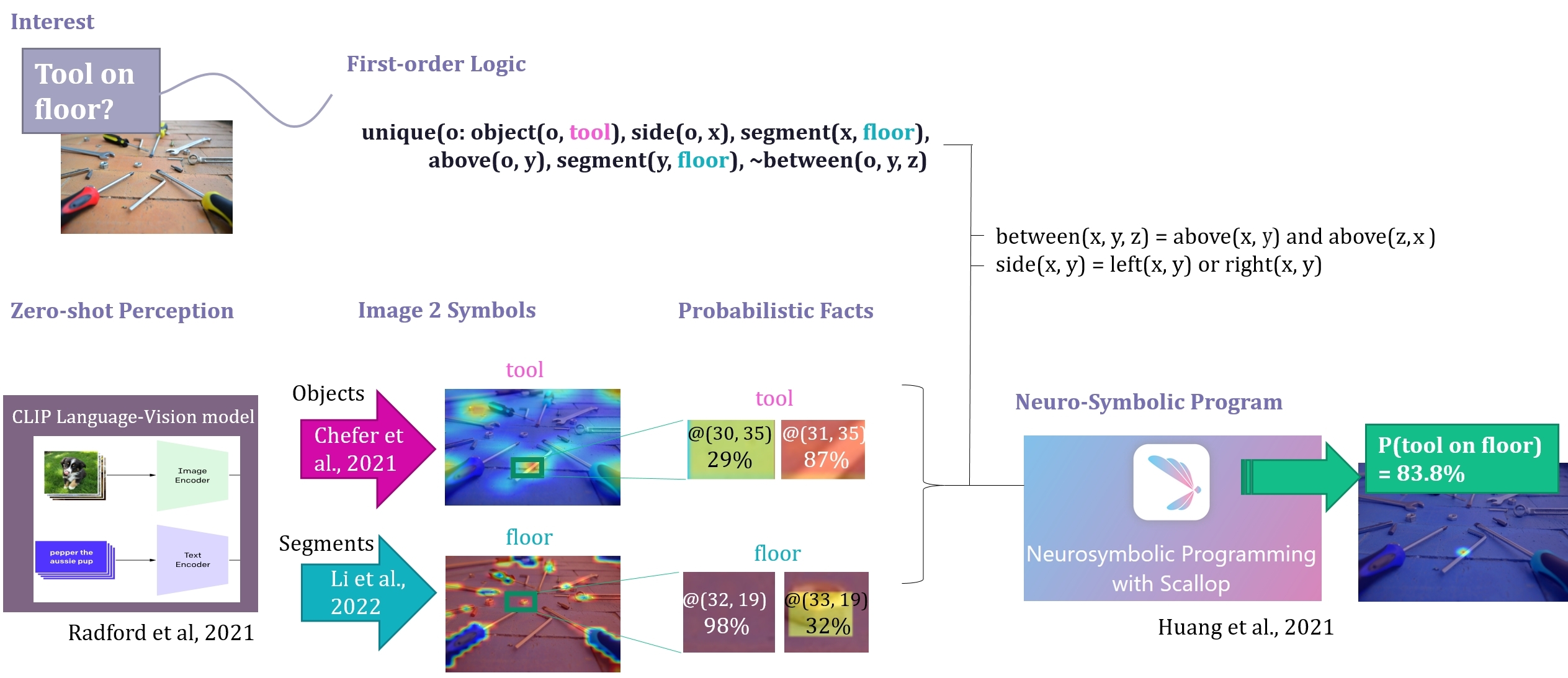
We consider the problem of finding spatial configurations of multiple objects in images, e.g., a mobile inspection robot is tasked to localize abandoned tools on the floor. We define the spatial configuration of objects by first-order logic in terms of relations and attributes. A neuro-symbolic program matches the logic formulas to probabilistic object proposals for the given image, provided by language-vision models by querying them for the symbols. This work is the first to combine neuro-symbolic programming (reasoning) and language-vision models (learning) to find spatial configurations of objects in images in an open world setting. We show the effectiveness by finding abandoned tools on floors and leaking pipes. We find that most prediction errors are due to biases in the language-vision model.
Read more7/19/2024

0
ALGO: Object-Grounded Visual Commonsense Reasoning for Open-World Egocentric Action Recognition
Sanjoy Kundu, Shubham Trehan, Sathyanarayanan N. Aakur
Learning to infer labels in an open world, i.e., in an environment where the target labels are unknown, is an important characteristic for achieving autonomy. Foundation models pre-trained on enormous amounts of data have shown remarkable generalization skills through prompting, particularly in zero-shot inference. However, their performance is restricted to the correctness of the target label's search space. In an open world, this target search space can be unknown or exceptionally large, which severely restricts the performance of such models. To tackle this challenging problem, we propose a neuro-symbolic framework called ALGO - Action Learning with Grounded Object recognition that uses symbolic knowledge stored in large-scale knowledge bases to infer activities in egocentric videos with limited supervision using two steps. First, we propose a neuro-symbolic prompting approach that uses object-centric vision-language models as a noisy oracle to ground objects in the video through evidence-based reasoning. Second, driven by prior commonsense knowledge, we discover plausible activities through an energy-based symbolic pattern theory framework and learn to ground knowledge-based action (verb) concepts in the video. Extensive experiments on four publicly available datasets (EPIC-Kitchens, GTEA Gaze, GTEA Gaze Plus) demonstrate its performance on open-world activity inference.
Read more6/11/2024

0
Neuro-symbolic Training for Reasoning over Spatial Language
Tanawan Premsri, Parisa Kordjamshidi
Recent research shows that more data and larger models can provide more accurate solutions to natural language problems requiring reasoning. However, models can easily fail to provide solutions in unobserved complex input compositions due to not achieving the level of abstraction required for generalizability. To alleviate this issue, we propose training the language models with neuro-symbolic techniques that can exploit the logical rules of reasoning as constraints and provide additional supervision sources to the model. Training models to adhere to the regulations of reasoning pushes them to make more effective abstractions needed for generalizability and transfer learning. We focus on a challenging problem of spatial reasoning over text. Our results on various benchmarks using multiple language models confirm our hypothesis of effective domain transfer based on neuro-symbolic training.
Read more6/21/2024

0
Towards Open-World Grasping with Large Vision-Language Models
Georgios Tziafas, Hamidreza Kasaei
The ability to grasp objects in-the-wild from open-ended language instructions constitutes a fundamental challenge in robotics. An open-world grasping system should be able to combine high-level contextual with low-level physical-geometric reasoning in order to be applicable in arbitrary scenarios. Recent works exploit the web-scale knowledge inherent in large language models (LLMs) to plan and reason in robotic context, but rely on external vision and action models to ground such knowledge into the environment and parameterize actuation. This setup suffers from two major bottlenecks: a) the LLM's reasoning capacity is constrained by the quality of visual grounding, and b) LLMs do not contain low-level spatial understanding of the world, which is essential for grasping in contact-rich scenarios. In this work we demonstrate that modern vision-language models (VLMs) are capable of tackling such limitations, as they are implicitly grounded and can jointly reason about semantics and geometry. We propose OWG, an open-world grasping pipeline that combines VLMs with segmentation and grasp synthesis models to unlock grounded world understanding in three stages: open-ended referring segmentation, grounded grasp planning and grasp ranking via contact reasoning, all of which can be applied zero-shot via suitable visual prompting mechanisms. We conduct extensive evaluation in cluttered indoor scene datasets to showcase OWG's robustness in grounding from open-ended language, as well as open-world robotic grasping experiments in both simulation and hardware that demonstrate superior performance compared to previous supervised and zero-shot LLM-based methods.
Read more7/16/2024