Optimal Control of Agent-Based Dynamics under Deep Galerkin Feedback Laws

0
🤿
Sign in to get full access
Overview
- The paper investigates a sampling approach to address high-dimensional control problems using Deep Neural Networks.
- It proposes a drift relaxation-based sampling method to improve the performance of the Deep Galerkin Method on mean-field control problems.
- The resulting policies show significant cost reduction compared to manually optimised control functions and improvements over the Deep FBSDE approach on the Linear-Quadratic Regulator problem.
Plain English Explanation
As the complexity of control problems grows with increasing dimensionality, Deep Neural Networks promise to circumvent the exponentially increasing complexity. This paper focuses on addressing the sampling issues encountered by the Deep Galerkin Method, a technique used to solve high-dimensional control problems.
The researchers propose a drift relaxation-based sampling approach to improve the performance of the Deep Galerkin Method. This approach helps to alleviate the high-variance policy approximations that can arise in such complex scenarios. To validate their method, the researchers apply it to mean-field control problems, such as the Sznajd and Hegselmann-Krause models of opinion dynamics.
The policies generated by the researchers' approach demonstrate a significant reduction in cost compared to manually optimized control functions. Additionally, the policies show improvements over the Deep FBSDE (Forward-Backward Stochastic Differential Equation) approach on the Linear-Quadratic Regulator problem, a well-known benchmark in control theory.
Technical Explanation
The paper investigates a drift relaxation-based sampling approach to address the sampling issues encountered by the Deep Galerkin Method when solving high-dimensional control problems. The Deep Galerkin Method is a technique that leverages Deep Neural Networks to circumvent the exponentially increasing complexity that arises with growing dimensionality.
The researchers propose a drift relaxation-based sampling approach to improve the performance of the Deep Galerkin Method on mean-field control problems, such as the Sznajd and Hegselmann-Krause models of opinion dynamics. This approach helps to alleviate the high-variance policy approximations that can occur in such complex scenarios.
The resulting policies demonstrate a significant reduction in cost compared to manually optimized control functions. Furthermore, the policies show improvements over the Deep FBSDE approach on the Linear-Quadratic Regulator problem, a well-studied benchmark in control theory.
Critical Analysis
The paper presents a novel sampling approach to address the high-dimensional control problems encountered when using the Deep Galerkin Method. The researchers' drift relaxation-based sampling technique is an interesting solution to the sampling issues that can arise in such complex scenarios.
However, the paper does not provide extensive discussion on the limitations of the proposed approach. It would be valuable to understand the specific conditions or problem settings where the drift relaxation-based sampling might not perform as well, or if there are any potential drawbacks to the method.
Additionally, the paper could benefit from a more in-depth analysis of the convergence properties of the Deep Galerkin Method and how the proposed sampling approach might impact the overall convergence of the method.
Further research could also explore the application of the drift relaxation-based sampling approach to a broader range of high-dimensional control problems, beyond the specific mean-field control examples presented in the paper.
Conclusion
This paper presents a drift relaxation-based sampling approach to address the sampling issues encountered by the Deep Galerkin Method when solving high-dimensional control problems. The proposed method demonstrates significant cost reduction in mean-field control problems and improvements over the Deep FBSDE approach on the Linear-Quadratic Regulator problem.
The research highlights the potential of Deep Neural Networks to circumvent the exponentially increasing complexity of high-dimensional control problems, and the importance of addressing sampling challenges to ensure the effectiveness of such techniques.
This work contributes to the ongoing efforts to improve the performance of deep learning-based methods in the field of optimal control and decision-making, with potential applications in a wide range of domains, from robotics and transportation to finance and energy systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Optimal Control of Agent-Based Dynamics under Deep Galerkin Feedback Laws
Frederik Kelbel
Ever since the concepts of dynamic programming were introduced, one of the most difficult challenges has been to adequately address high-dimensional control problems. With growing dimensionality, the utilisation of Deep Neural Networks promises to circumvent the issue of an otherwise exponentially increasing complexity. The paper specifically investigates the sampling issues the Deep Galerkin Method is subjected to. It proposes a drift relaxation-based sampling approach to alleviate the symptoms of high-variance policy approximations. This is validated on mean-field control problems; namely, the variations of the opinion dynamics presented by the Sznajd and the Hegselmann-Krause model. The resulting policies induce a significant cost reduction over manually optimised control functions and show improvements on the Linear-Quadratic Regulator problem over the Deep FBSDE approach.
Read more6/14/2024

0
Real-time optimal control of high-dimensional parametrized systems by deep learning-based reduced order models
Matteo Tomasetto, Andrea Manzoni, Francesco Braghin
Steering a system towards a desired target in a very short amount of time is challenging from a computational standpoint. Indeed, the intrinsically iterative nature of optimal control problems requires multiple simulations of the physical system to be controlled. Moreover, the control action needs to be updated whenever the underlying scenario undergoes variations. Full-order models based on, e.g., the Finite Element Method, do not meet these requirements due to the computational burden they usually entail. On the other hand, conventional reduced order modeling techniques such as the Reduced Basis method, are intrusive, rely on a linear superimposition of modes, and lack of efficiency when addressing nonlinear time-dependent dynamics. In this work, we propose a non-intrusive Deep Learning-based Reduced Order Modeling (DL-ROM) technique for the rapid control of systems described in terms of parametrized PDEs in multiple scenarios. In particular, optimal full-order snapshots are generated and properly reduced by either Proper Orthogonal Decomposition or deep autoencoders (or a combination thereof) while feedforward neural networks are exploited to learn the map from scenario parameters to reduced optimal solutions. Nonlinear dimensionality reduction therefore allows us to consider state variables and control actions that are both low-dimensional and distributed. After (i) data generation, (ii) dimensionality reduction, and (iii) neural networks training in the offline phase, optimal control strategies can be rapidly retrieved in an online phase for any scenario of interest. The computational speedup and the high accuracy obtained with the proposed approach are assessed on different PDE-constrained optimization problems, ranging from the minimization of energy dissipation in incompressible flows modelled through Navier-Stokes equations to the thermal active cooling in heat transfer.
Read more9/10/2024
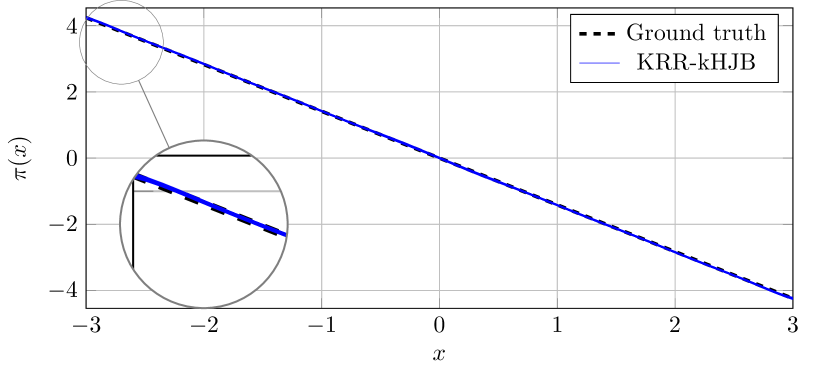
0
Data-Driven Optimal Feedback Laws via Kernel Mean Embeddings
Petar Bevanda, Nicolas Hoischen, Stefan Sosnowski, Sandra Hirche, Boris Houska
This paper proposes a fully data-driven approach for optimal control of nonlinear control-affine systems represented by a stochastic diffusion. The focus is on the scenario where both the nonlinear dynamics and stage cost functions are unknown, while only control penalty function and constraints are provided. Leveraging the theory of reproducing kernel Hilbert spaces, we introduce novel kernel mean embeddings (KMEs) to identify the Markov transition operators associated with controlled diffusion processes. The KME learning approach seamlessly integrates with modern convex operator-theoretic Hamilton-Jacobi-Bellman recursions. Thus, unlike traditional dynamic programming methods, our approach exploits the ``kernel trick'' to break the curse of dimensionality. We demonstrate the effectiveness of our method through numerical examples, highlighting its ability to solve a large class of nonlinear optimal control problems.
Read more7/24/2024
🤿
0
A deep learning method for solving stochastic optimal control problems driven by fully-coupled FBSDEs
Shaolin Ji, Shige Peng, Ying Peng, Xichuan Zhang
In this paper,we mainly focus on the numerical solution of high-dimensional stochastic optimal control problem driven by fully-coupled forward-backward stochastic differential equations (FBSDEs in short) through deep learning. We first transform the problem into a stochastic Stackelberg differential game problem (leader-follower problem), then a bi-level optimization method is developed where the leader's cost functional and the follower's cost functional are optimized alternatively via deep neural networks. As for the numerical results, we compute two examples of the investment-consumption problem solved through stochastic recursive utility models, and the results of both examples demonstrate the effectiveness of our proposed algorithm.
Read more8/21/2024