Optimal Reward Labeling: Bridging Offline Preference and Reward-Based Reinforcement Learning
2406.10445
0
0

Abstract
Offline reinforcement learning has become one of the most practical RL settings. A recent success story has been RLHF, offline preference-based RL (PBRL) with preference from humans. However, most existing works on offline RL focus on the standard setting with scalar reward feedback. It remains unknown how to universally transfer the existing rich understanding of offline RL from the reward-based to the preference-based setting. In this work, we propose a general framework to bridge this gap. Our key insight is transforming preference feedback to scalar rewards via optimal reward labeling (ORL), and then any reward-based offline RL algorithms can be applied to the dataset with the reward labels. We theoretically show the connection between several recent PBRL techniques and our framework combined with specific offline RL algorithms in terms of how they utilize the preference signals. By combining reward labeling with different algorithms, our framework can lead to new and potentially more efficient offline PBRL algorithms. We empirically test our framework on preference datasets based on the standard D4RL benchmark. When combined with a variety of efficient reward-based offline RL algorithms, the learning result achieved under our framework is comparable to training the same algorithm on the dataset with actual rewards in many cases and better than the recent PBRL baselines in most cases.
Create account to get full access
Related Work
Offline Reward Learning and Preference Optimization
Several recent papers have explored the problem of learning rewards or preferences from offline data, with the goal of using this information to guide reinforcement learning (RL) agents.
The Unified Linear Programming Framework for Offline Reward Learning paper presents a framework for learning rewards from preference data, and shows how this can be used to optimize an agent's policy. The Value-Incentivized Preference Optimization paper takes a similar approach, but combines reward learning with policy optimization in a unified framework.
Online Preference Learning
Other work has looked at the problem of learning preferences in an online, interactive setting. The Online Bandit Learning from Offline Preference Data paper explores how to use offline preference data to guide an online bandit algorithm. And the Online Iterative Reinforcement Learning from Human Feedback paper investigates using human feedback to iteratively refine an RL agent's policy.
Incorporating Diverse Human Preferences
Finally, some researchers have looked at the challenge of incorporating a diverse range of human preferences into RL systems. The Reinforcement Learning from Diverse Human Preferences paper explores this problem, and proposes methods for aggregating preferences from multiple sources.
Overall, this body of work highlights the importance of bridging the gap between offline preference data and online RL. The current paper aims to contribute to this effort by proposing a new approach that combines these two perspectives.
Plain English Explanation
The main idea behind this paper is to find a way to use information about human preferences, collected offline, to help train reinforcement learning (RL) agents to behave in a way that aligns with those preferences.
Traditionally, RL agents are trained by giving them a reward signal that encourages them to take actions that maximize that reward. But figuring out the right reward function can be challenging, especially when dealing with complex, real-world tasks.
This paper proposes a new approach called "Optimal Reward Labeling" that tries to bridge the gap between offline preference data and online RL. The key insight is to use the preference data to learn an optimal reward function that captures what humans actually care about, and then use that reward function to train the RL agent.
The paper builds on several recent papers that have explored similar ideas, such as learning rewards from preference data, or using human feedback to refine RL policies. But it proposes a new, integrated framework that combines these different approaches in a principled way.
One of the key advantages of this approach is that it can potentially incorporate a diverse range of human preferences, rather than trying to distill everything down to a single reward function. This could lead to RL agents that behave in more nuanced, human-aligned ways.
Of course, there are still many challenges to overcome, such as how to effectively elicit and aggregate preference data, and how to ensure that the learned reward function is accurate and generalizable. But this paper represents an important step towards bridging the gap between offline preferences and online RL.
Technical Explanation
The core idea of the paper is to learn an optimal reward function from offline preference data, and then use that reward function to train a reinforcement learning (RL) agent.
The authors propose a framework called "Optimal Reward Labeling" (ORL) that consists of two main components:
-
Reward Learning: The first step is to learn an optimal reward function from offline preference data, using techniques like Unified Linear Programming Framework for Offline Reward Learning or Value-Incentivized Preference Optimization. This reward function should capture the underlying preferences expressed in the offline data.
-
Reward-Based RL: Once the reward function is learned, the authors use it to train an RL agent using standard reward-based RL algorithms. The goal is for the agent to learn a policy that maximizes the learned reward function, which should in turn align with the preferences expressed in the offline data.
The authors argue that this approach has several advantages over traditional RL or preference learning methods. By separating the reward learning and policy optimization steps, it can potentially incorporate a wider range of preference data sources, including both Online Bandit Learning from Offline Preference Data and Online Iterative Reinforcement Learning from Human Feedback.
Additionally, the framework can handle Reinforcement Learning from Diverse Human Preferences, by learning a single reward function that captures the aggregated preferences from multiple sources.
The authors validate their approach through a series of experiments on both synthetic and real-world environments, demonstrating its advantages over existing methods. They also discuss potential limitations and areas for future research, such as how to effectively elicit and aggregate diverse preference data.
Critical Analysis
The key insight of this paper – combining offline preference data with online reward-based RL – is a promising approach that could help address some of the challenges in aligning RL agents with human values. By separating the reward learning and policy optimization steps, the ORL framework provides a modular and flexible way to incorporate a wide range of preference data sources.
That said, the authors acknowledge several important limitations and areas for further research. One key challenge is how to effectively elicit and aggregate diverse human preferences, especially when they may be conflicting or context-dependent. The paper does not provide a detailed solution to this problem, which is an important area for future work.
Additionally, the authors note that the quality of the learned reward function is critical to the success of the overall approach. If the reward function does not accurately capture the underlying preferences, the RL agent may still fail to behave in an aligned way. Developing robust reward learning techniques that can handle noisy or biased preference data is an important area for further research.
Finally, the paper focuses primarily on the algorithmic aspects of the ORL framework, without delving deeply into the ethical and societal implications of this approach. As RL systems become more pervasive and influential, it will be crucial to carefully consider the potential risks and unintended consequences of methods that aim to align agent behavior with human preferences. Ongoing research and public discourse in this area is essential.
Overall, the Optimal Reward Labeling framework represents an important step towards bridging the gap between offline preference data and online RL. However, significant challenges remain in making this approach robust, scalable, and aligned with broader ethical considerations. Continued research and open dialogue will be key to realizing the full potential of this approach.
Conclusion
This paper proposes a new framework called "Optimal Reward Labeling" that aims to bridge the gap between offline preference data and online reward-based reinforcement learning (RL). The core idea is to learn an optimal reward function from the preference data, and then use that reward function to train an RL agent.
This approach has several potential advantages over traditional RL or preference learning methods. By separating the reward learning and policy optimization steps, it can potentially incorporate a wider range of preference data sources, including both offline and online feedback. It can also handle diverse human preferences by learning a single reward function that captures the aggregated preferences from multiple sources.
The authors validate their approach through experiments, demonstrating its advantages over existing methods. However, they also acknowledge several important limitations and areas for further research, such as how to effectively elicit and aggregate diverse preference data, and how to ensure the learned reward function accurately captures underlying human values.
Overall, the Optimal Reward Labeling framework represents an important step towards aligning RL agents with human preferences. But significant challenges remain, both in the technical aspects of the approach and in the broader ethical and societal implications. Continued research and open dialogue will be essential to realizing the full potential of this approach and ensuring it is deployed responsibly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Preference Elicitation for Offline Reinforcement Learning
Aliz'ee Pace, Bernhard Scholkopf, Gunnar Ratsch, Giorgia Ramponi
0
0
Applying reinforcement learning (RL) to real-world problems is often made challenging by the inability to interact with the environment and the difficulty of designing reward functions. Offline RL addresses the first challenge by considering access to an offline dataset of environment interactions labeled by the reward function. In contrast, Preference-based RL does not assume access to the reward function and learns it from preferences, but typically requires an online interaction with the environment. We bridge the gap between these frameworks by exploring efficient methods for acquiring preference feedback in a fully offline setup. We propose Sim-OPRL, an offline preference-based reinforcement learning algorithm, which leverages a learned environment model to elicit preference feedback on simulated rollouts. Drawing on insights from both the offline RL and the preference-based RL literature, our algorithm employs a pessimistic approach for out-of-distribution data, and an optimistic approach for acquiring informative preferences about the optimal policy. We provide theoretical guarantees regarding the sample complexity of our approach, dependent on how well the offline data covers the optimal policy. Finally, we demonstrate the empirical performance of Sim-OPRL in different environments.
6/27/2024
🐍
A Unified Linear Programming Framework for Offline Reward Learning from Human Demonstrations and Feedback
Kihyun Kim, Jiawei Zhang, Asuman Ozdaglar, Pablo A. Parrilo
0
0
Inverse Reinforcement Learning (IRL) and Reinforcement Learning from Human Feedback (RLHF) are pivotal methodologies in reward learning, which involve inferring and shaping the underlying reward function of sequential decision-making problems based on observed human demonstrations and feedback. Most prior work in reward learning has relied on prior knowledge or assumptions about decision or preference models, potentially leading to robustness issues. In response, this paper introduces a novel linear programming (LP) framework tailored for offline reward learning. Utilizing pre-collected trajectories without online exploration, this framework estimates a feasible reward set from the primal-dual optimality conditions of a suitably designed LP, and offers an optimality guarantee with provable sample efficiency. Our LP framework also enables aligning the reward functions with human feedback, such as pairwise trajectory comparison data, while maintaining computational tractability and sample efficiency. We demonstrate that our framework potentially achieves better performance compared to the conventional maximum likelihood estimation (MLE) approach through analytical examples and numerical experiments.
6/5/2024
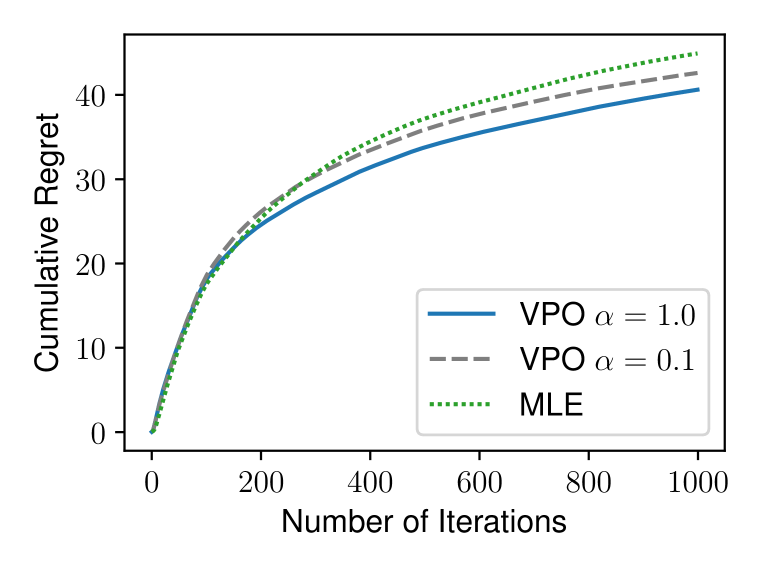
Value-Incentivized Preference Optimization: A Unified Approach to Online and Offline RLHF
Shicong Cen, Jincheng Mei, Katayoon Goshvadi, Hanjun Dai, Tong Yang, Sherry Yang, Dale Schuurmans, Yuejie Chi, Bo Dai
0
0
Reinforcement learning from human feedback (RLHF) has demonstrated great promise in aligning large language models (LLMs) with human preference. Depending on the availability of preference data, both online and offline RLHF are active areas of investigation. A key bottleneck is understanding how to incorporate uncertainty estimation in the reward function learned from the preference data for RLHF, regardless of how the preference data is collected. While the principles of optimism or pessimism under uncertainty are well-established in standard reinforcement learning (RL), a practically-implementable and theoretically-grounded form amenable to large language models is not yet available, as standard techniques for constructing confidence intervals become intractable under arbitrary policy parameterizations. In this paper, we introduce a unified approach to online and offline RLHF -- value-incentivized preference optimization (VPO) -- which regularizes the maximum-likelihood estimate of the reward function with the corresponding value function, modulated by a $textit{sign}$ to indicate whether the optimism or pessimism is chosen. VPO also directly optimizes the policy with implicit reward modeling, and therefore shares a simpler RLHF pipeline similar to direct preference optimization. Theoretical guarantees of VPO are provided for both online and offline settings, matching the rates of their standard RL counterparts. Moreover, experiments on text summarization and dialog verify the practicality and effectiveness of VPO.
6/6/2024

Online Bandit Learning with Offline Preference Data
Akhil Agnihotri, Rahul Jain, Deepak Ramachandran, Zheng Wen
0
0
Reinforcement Learning with Human Feedback (RLHF) is at the core of fine-tuning methods for generative AI models for language and images. Such feedback is often sought as rank or preference feedback from human raters, as opposed to eliciting scores since the latter tends to be very noisy. On the other hand, RL theory and algorithms predominantly assume that a reward feedback is available. In particular, approaches for online learning that can be helpful in adaptive data collection via active learning cannot incorporate offline preference data. In this paper, we adopt a finite-armed linear bandit model as a prototypical model of online learning. We consider an offline preference dataset to be available generated by an expert of unknown 'competence'. We propose $texttt{warmPref-PS}$, a posterior sampling algorithm for online learning that can be warm-started with an offline dataset with noisy preference feedback. We show that by modeling the competence of the expert that generated it, we are able to use such a dataset most effectively. We support our claims with novel theoretical analysis of its Bayesian regret, as well as extensive empirical evaluation of an approximate algorithm which performs substantially better (almost 25 to 50% regret reduction in our studies) as compared to baselines.
6/17/2024