Visual Grounding Methods for VQA are Working for the Wrong Reasons!
2004.05704
0
0
🚀
Abstract
Existing Visual Question Answering (VQA) methods tend to exploit dataset biases and spurious statistical correlations, instead of producing right answers for the right reasons. To address this issue, recent bias mitigation methods for VQA propose to incorporate visual cues (e.g., human attention maps) to better ground the VQA models, showcasing impressive gains. However, we show that the performance improvements are not a result of improved visual grounding, but a regularization effect which prevents over-fitting to linguistic priors. For instance, we find that it is not actually necessary to provide proper, human-based cues; random, insensible cues also result in similar improvements. Based on this observation, we propose a simpler regularization scheme that does not require any external annotations and yet achieves near state-of-the-art performance on VQA-CPv2.
Create account to get full access
Overview
- Existing Visual Question Answering (VQA) methods often rely on dataset biases and statistical correlations rather than producing the right answers for the right reasons.
- Recent bias mitigation methods for VQA propose incorporating visual cues (e.g., human attention maps) to better ground the VQA models, leading to impressive performance gains.
- However, this paper shows that the performance improvements are not due to improved visual grounding, but rather a regularization effect that prevents overfitting to linguistic priors.
- The paper proposes a simpler regularization scheme that does not require any external annotations and still achieves near state-of-the-art performance on VQA-CPv2.
Plain English Explanation
Visual Question Answering (VQA) is a task where a computer system is asked a question about an image and must provide the correct answer. However, existing VQA methods often rely on shortcuts, such as exploiting patterns in the dataset, rather than truly understanding the image and question.
To address this issue, some researchers have proposed incorporating visual cues, like human attention maps, to help the VQA models better ground their answers in the visual information. This has led to impressive performance gains on VQA benchmarks. However, this paper shows that these performance improvements are not actually due to the models learning to better understand the images. Instead, the visual cues are acting as a regularizer, preventing the models from overfitting to linguistic biases in the dataset.
Surprisingly, the researchers found that it doesn't even matter if the visual cues are meaningful or not - random, nonsensical cues also lead to similar performance improvements. Based on this finding, the paper proposes a simpler regularization technique that doesn't require any extra annotations, yet still achieves near state-of-the-art results on a popular VQA benchmark called VQA-CPv2.
Technical Explanation
This paper investigates the surprisingly effective performance of recent bias mitigation methods for Visual Question Answering (VQA). These methods incorporate visual cues, such as human attention maps, to better ground the VQA models and reduce their reliance on dataset biases and spurious correlations.
The authors conduct a series of experiments to understand the underlying reasons for the performance gains observed with these bias mitigation techniques. Contrary to the common assumption, they find that the improvements are not due to the models learning to better ground their reasoning in the visual input. Instead, the visual cues serve as a regularizer, preventing the models from overfitting to linguistic priors in the dataset.
The key evidence for this claim is that even random, meaningless visual cues lead to similar performance improvements as human-annotated attention maps. This suggests that the visual cues are not actually helping the models to understand the images better, but rather acting as a general regularization mechanism.
Based on this finding, the authors propose a simpler regularization scheme that does not require any external annotations. This approach, which they call "Visual Cue Regularization" (VCR), achieves near state-of-the-art performance on the VQA-CPv2 benchmark without the need for additional visual inputs.
Critical Analysis
The findings of this paper challenge the common assumption that incorporating visual cues, such as human attention maps, is necessary for improving the visual grounding of VQA models. Instead, the authors demonstrate that these visual cues primarily act as a regularizer, preventing the models from overfitting to linguistic biases in the dataset.
While the authors provide a compelling explanation for the performance gains observed with bias mitigation methods, the paper does not fully address the potential limitations of their proposed VCR approach. For instance, it remains unclear how well VCR would generalize to more complex visual reasoning tasks that require a deeper understanding of the image-question relationship, such as weakly-supervised 3D visual grounding.
Additionally, the paper does not explore the potential benefits of using meaningful visual cues, even if they are not strictly necessary for achieving state-of-the-art performance. It is possible that such cues could still provide additional insights or strengthen the models' visual understanding in more nuanced ways.
Overall, this paper offers a thought-provoking perspective on the role of visual cues in VQA and highlights the importance of carefully evaluating the underlying reasons for performance improvements, rather than simply accepting them at face value. The proposed VCR approach provides a promising alternative to more complex bias mitigation techniques, but further research is needed to fully understand its strengths, limitations, and potential applications.
Conclusion
This paper challenges the common assumption that incorporating visual cues, such as human attention maps, is necessary for improving the visual grounding of Visual Question Answering (VQA) models. The authors demonstrate that the performance gains observed with recent bias mitigation methods are not due to the models learning to better understand the images, but rather a regularization effect that prevents overfitting to linguistic priors in the dataset.
By showing that even random, meaningless visual cues can lead to similar performance improvements, the paper provides a more nuanced understanding of how these bias mitigation techniques work. This insight informs the authors' proposal of a simpler regularization scheme, called Visual Cue Regularization (VCR), which achieves near state-of-the-art results on the VQA-CPv2 benchmark without requiring any external annotations.
The findings of this paper have important implications for the development of more robust and interpretable VQA systems. By questioning the assumed benefits of incorporating visual cues, the authors encourage the research community to critically examine the underlying mechanisms driving performance improvements in this domain. This work also highlights the need for continued exploration of efficient regularization techniques that can help VQA models overcome dataset biases and produce answers for the right reasons.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

On the Role of Visual Grounding in VQA
Daniel Reich, Tanja Schultz
0
0
Visual Grounding (VG) in VQA refers to a model's proclivity to infer answers based on question-relevant image regions. Conceptually, VG identifies as an axiomatic requirement of the VQA task. In practice, however, DNN-based VQA models are notorious for bypassing VG by way of shortcut (SC) learning without suffering obvious performance losses in standard benchmarks. To uncover the impact of SC learning, Out-of-Distribution (OOD) tests have been proposed that expose a lack of VG with low accuracy. These tests have since been at the center of VG research and served as basis for various investigations into VG's impact on accuracy. However, the role of VG in VQA still remains not fully understood and has not yet been properly formalized. In this work, we seek to clarify VG's role in VQA by formalizing it on a conceptual level. We propose a novel theoretical framework called Visually Grounded Reasoning (VGR) that uses the concepts of VG and Reasoning to describe VQA inference in ideal OOD testing. By consolidating fundamental insights into VG's role in VQA, VGR helps to reveal rampant VG-related SC exploitation in OOD testing, which explains why the relationship between VG and OOD accuracy has been difficult to define. Finally, we propose an approach to create OOD tests that properly emphasize a requirement for VG, and show how to improve performance on them.
6/27/2024

Optimizing Visual Question Answering Models for Driving: Bridging the Gap Between Human and Machine Attention Patterns
Kaavya Rekanar, Martin Hayes, Ganesh Sistu, Ciaran Eising
0
0
Visual Question Answering (VQA) models play a critical role in enhancing the perception capabilities of autonomous driving systems by allowing vehicles to analyze visual inputs alongside textual queries, fostering natural interaction and trust between the vehicle and its occupants or other road users. This study investigates the attention patterns of humans compared to a VQA model when answering driving-related questions, revealing disparities in the objects observed. We propose an approach integrating filters to optimize the model's attention mechanisms, prioritizing relevant objects and improving accuracy. Utilizing the LXMERT model for a case study, we compare attention patterns of the pre-trained and Filter Integrated models, alongside human answers using images from the NuImages dataset, gaining insights into feature prioritization. We evaluated the models using a Subjective scoring framework which shows that the integration of the feature encoder filter has enhanced the performance of the VQA model by refining its attention mechanisms.
6/14/2024
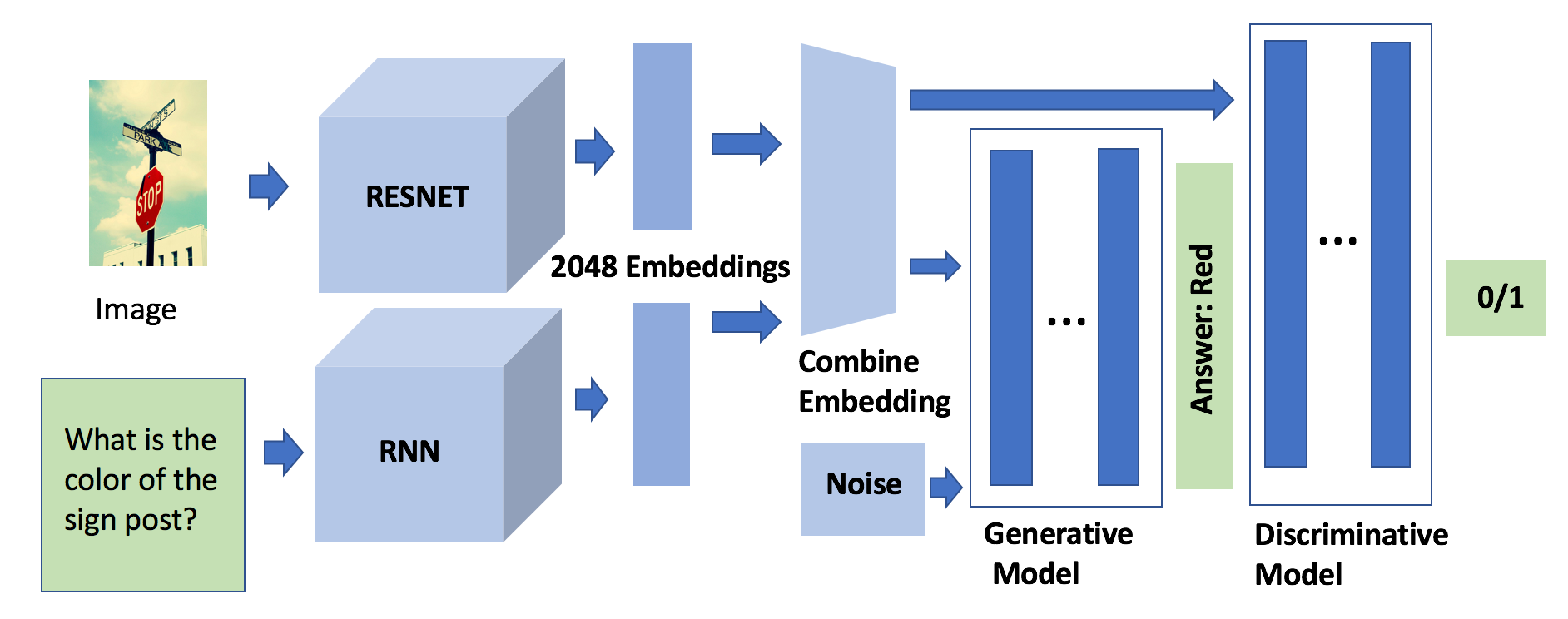
Exploring Diverse Methods in Visual Question Answering
Panfeng Li, Qikai Yang, Xieming Geng, Wenjing Zhou, Zhicheng Ding, Yi Nian
0
0
This study explores innovative methods for improving Visual Question Answering (VQA) using Generative Adversarial Networks (GANs), autoencoders, and attention mechanisms. Leveraging a balanced VQA dataset, we investigate three distinct strategies. Firstly, GAN-based approaches aim to generate answer embeddings conditioned on image and question inputs, showing potential but struggling with more complex tasks. Secondly, autoencoder-based techniques focus on learning optimal embeddings for questions and images, achieving comparable results with GAN due to better ability on complex questions. Lastly, attention mechanisms, incorporating Multimodal Compact Bilinear pooling (MCB), address language priors and attention modeling, albeit with a complexity-performance trade-off. This study underscores the challenges and opportunities in VQA and suggests avenues for future research, including alternative GAN formulations and attentional mechanisms.
5/22/2024

Selectively Answering Visual Questions
Julian Martin Eisenschlos, Hern'an Maina, Guido Ivetta, Luciana Benotti
0
0
Recently, large multi-modal models (LMMs) have emerged with the capacity to perform vision tasks such as captioning and visual question answering (VQA) with unprecedented accuracy. Applications such as helping the blind or visually impaired have a critical need for precise answers. It is specially important for models to be well calibrated and be able to quantify their uncertainty in order to selectively decide when to answer and when to abstain or ask for clarifications. We perform the first in-depth analysis of calibration methods and metrics for VQA with in-context learning LMMs. Studying VQA on two answerability benchmarks, we show that the likelihood score of visually grounded models is better calibrated than in their text-only counterparts for in-context learning, where sampling based methods are generally superior, but no clear winner arises. We propose Avg BLEU, a calibration score combining the benefits of both sampling and likelihood methods across modalities.
6/4/2024