Enhanced Visual Question Answering: A Comparative Analysis and Textual Feature Extraction Via Convolutions
2405.00479
0
0
Abstract
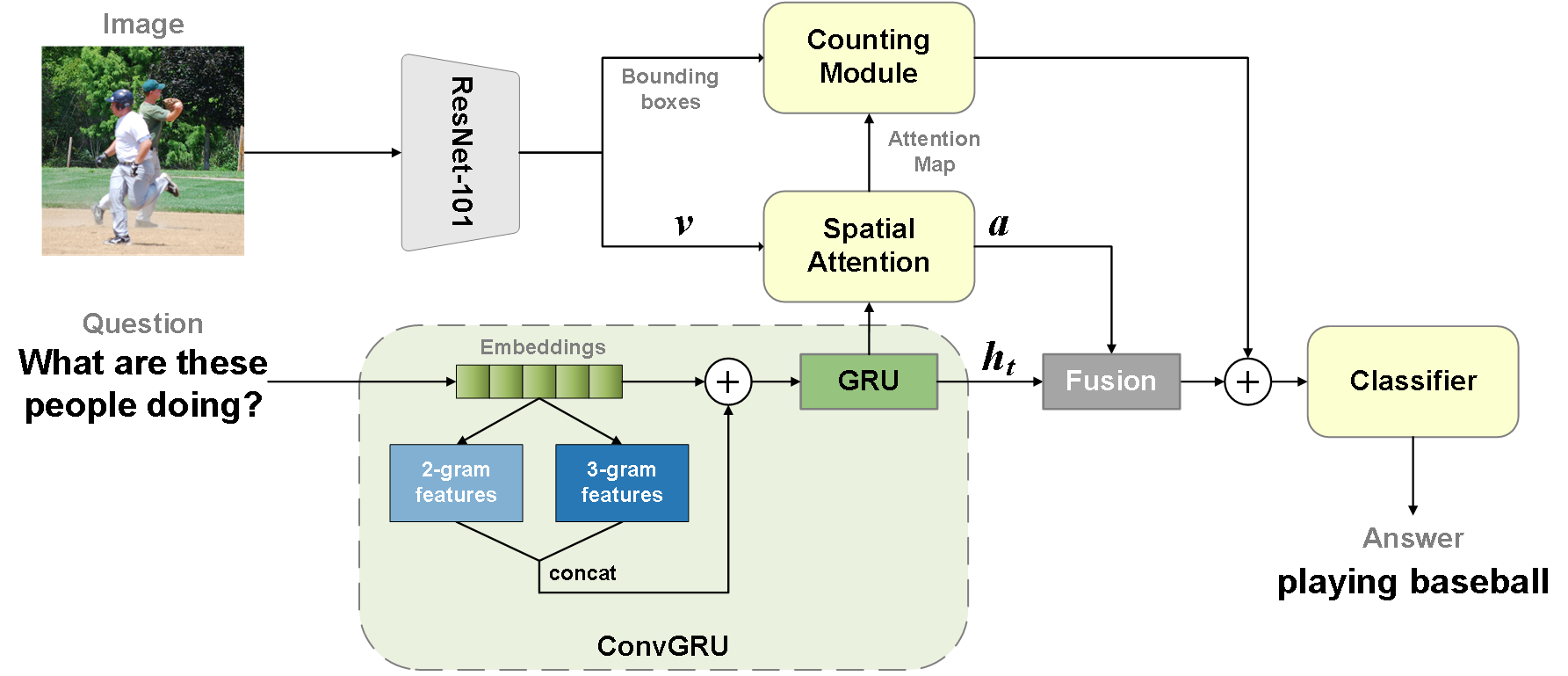
Visual Question Answering (VQA) has emerged as a highly engaging field in recent years, attracting increasing research efforts aiming to enhance VQA accuracy through the deployment of advanced models such as Transformers. Despite this growing interest, there has been limited exploration into the comparative analysis and impact of textual modalities within VQA, particularly in terms of model complexity and its effect on performance. In this work, we conduct a comprehensive comparison between complex textual models that leverage long dependency mechanisms and simpler models focusing on local textual features within a well-established VQA framework. Our findings reveal that employing complex textual encoders is not invariably the optimal approach for the VQA-v2 dataset. Motivated by this insight, we introduce an improved model, ConvGRU, which incorporates convolutional layers to enhance the representation of question text. Tested on the VQA-v2 dataset, ConvGRU achieves better performance without substantially increasing parameter complexity.
Create account to get full access
Overview
- This research paper presents a comparative analysis of enhanced visual question answering (VQA) models, focusing on textual feature extraction using convolutions.
- The paper explores different approaches to improve the performance of VQA systems, which aim to answer questions about the contents of an image.
- The researchers investigate the impact of various techniques, such as exploring diverse methods for visual question answering, utilizing visual question answering in design, and using large-scale VQA datasets.
Plain English Explanation
Visual question answering (VQA) is a technology that allows computers to answer questions about the contents of an image. This research paper explores different ways to improve the performance of VQA systems. The researchers tested various approaches, such as using different machine learning models, leveraging large VQA datasets, and focusing on how to best extract and use textual information from the questions.
The goal is to create VQA systems that can better understand the context and content of an image and provide more accurate and relevant answers to questions about it. This could have applications in areas like enhancing visual question answering through question-driven interactions, or using compact multimodal deep neural networks for VQA on mobile devices.
Technical Explanation
The paper begins by reviewing prior research on VQA, including work on exploring diverse methods, utilizing VQA in design, and large-scale VQA datasets. The authors then present their own enhanced VQA model, which focuses on improving the extraction and use of textual features from the questions using convolutional neural networks.
The model takes an image and a textual question as input, and produces an answer as output. The key innovation is the use of convolutional layers to better capture relevant textual features from the question, which are then combined with visual features from the image. The researchers experimented with different convolutional architectures and hyperparameters to optimize this textual feature extraction process.
Through extensive experiments on benchmark VQA datasets, the authors demonstrate that their enhanced VQA model outperforms previous state-of-the-art approaches. They provide detailed analysis of the model's performance, ablation studies, and comparisons to other techniques like question-driven VQA enhancement and compact multimodal networks.
Critical Analysis
The paper presents a thorough and well-designed study on improving VQA systems through enhanced textual feature extraction. The experimental results are convincing, and the authors have done a good job of situating their work within the broader context of VQA research.
However, one potential limitation is the reliance on benchmark datasets, which may not fully capture the complexity and diversity of real-world VQA scenarios. Additionally, the paper does not delve deeply into the interpretability or explainability of the model's decision-making process, which could be an important consideration for real-world applications.
Furthermore, the researchers acknowledge that their approach is computationally intensive, which could limit its practical deployment, especially on mobile or resource-constrained devices. Exploring more efficient architectures or compression techniques could be an area for future research.
Conclusion
This research paper makes a valuable contribution to the field of visual question answering by demonstrating the benefits of improved textual feature extraction using convolutional neural networks. The enhanced VQA model proposed by the authors outperforms previous state-of-the-art approaches and highlights the importance of carefully leveraging both visual and textual information for accurate and contextual question answering.
While the paper has some limitations, it provides a strong foundation for further research and development in this area. Advancing VQA technology could have significant implications for a wide range of applications, from enhancing visual question answering through question-driven interactions to using compact multimodal deep neural networks for mobile VQA.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Exploring Diverse Methods in Visual Question Answering
Panfeng Li, Qikai Yang, Xieming Geng, Wenjing Zhou, Zhicheng Ding, Yi Nian
0
0
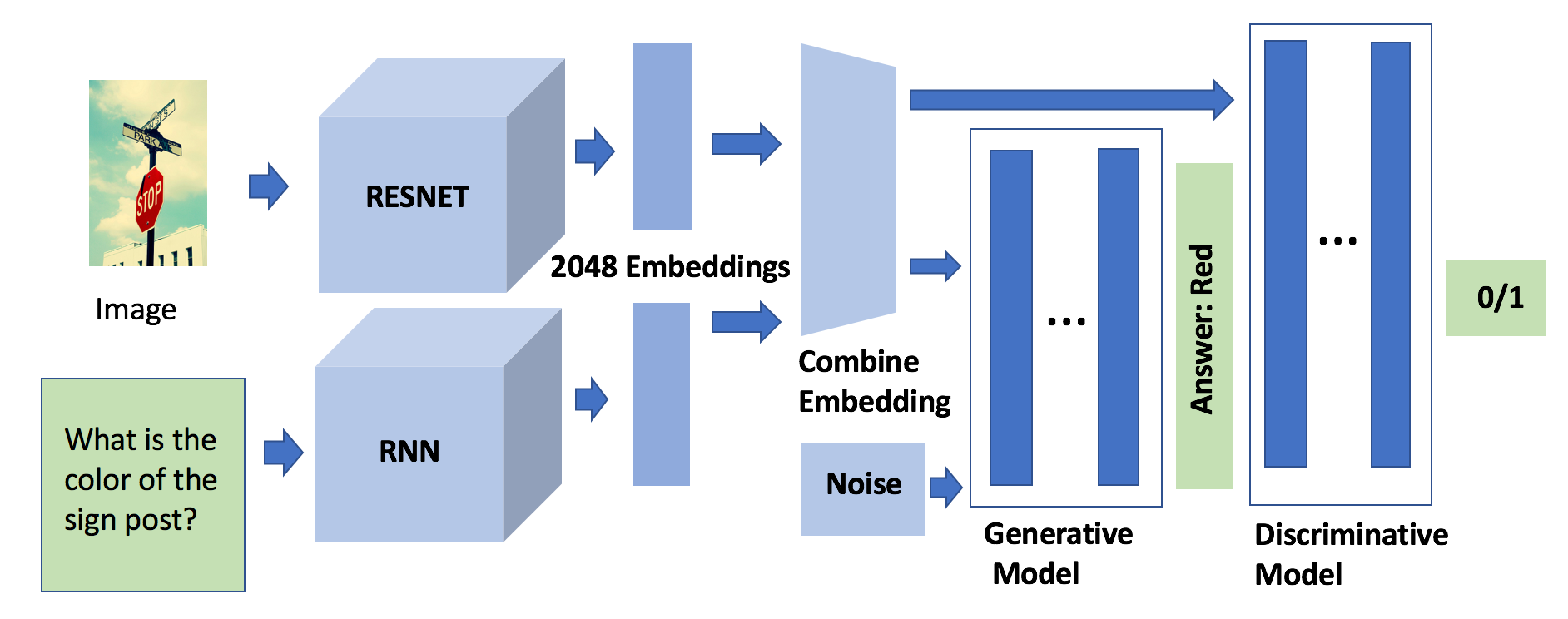
This study explores innovative methods for improving Visual Question Answering (VQA) using Generative Adversarial Networks (GANs), autoencoders, and attention mechanisms. Leveraging a balanced VQA dataset, we investigate three distinct strategies. Firstly, GAN-based approaches aim to generate answer embeddings conditioned on image and question inputs, showing potential but struggling with more complex tasks. Secondly, autoencoder-based techniques focus on learning optimal embeddings for questions and images, achieving comparable results with GAN due to better ability on complex questions. Lastly, attention mechanisms, incorporating Multimodal Compact Bilinear pooling (MCB), address language priors and attention modeling, albeit with a complexity-performance trade-off. This study underscores the challenges and opportunities in VQA and suggests avenues for future research, including alternative GAN formulations and attentional mechanisms.
5/22/2024

Precision Empowers, Excess Distracts: Visual Question Answering With Dynamically Infused Knowledge In Language Models
Manas Jhalani, Annervaz K M, Pushpak Bhattacharyya
0
0
In the realm of multimodal tasks, Visual Question Answering (VQA) plays a crucial role by addressing natural language questions grounded in visual content. Knowledge-Based Visual Question Answering (KBVQA) advances this concept by adding external knowledge along with images to respond to questions. We introduce an approach for KBVQA, augmenting the existing vision-language transformer encoder-decoder (OFA) model. Our main contribution involves enhancing questions by incorporating relevant external knowledge extracted from knowledge graphs, using a dynamic triple extraction method. We supply a flexible number of triples from the knowledge graph as context, tailored to meet the requirements for answering the question. Our model, enriched with knowledge, demonstrates an average improvement of 4.75% in Exact Match Score over the state-of-the-art on three different KBVQA datasets. Through experiments and analysis, we demonstrate that furnishing variable triples for each question improves the reasoning capabilities of the language model in contrast to supplying a fixed number of triples. This is illustrated even for recent large language models. Additionally, we highlight the model's generalization capability by showcasing its SOTA-beating performance on a small dataset, achieved through straightforward fine-tuning.
6/17/2024

Optimizing Visual Question Answering Models for Driving: Bridging the Gap Between Human and Machine Attention Patterns
Kaavya Rekanar, Martin Hayes, Ganesh Sistu, Ciaran Eising
0
0
Visual Question Answering (VQA) models play a critical role in enhancing the perception capabilities of autonomous driving systems by allowing vehicles to analyze visual inputs alongside textual queries, fostering natural interaction and trust between the vehicle and its occupants or other road users. This study investigates the attention patterns of humans compared to a VQA model when answering driving-related questions, revealing disparities in the objects observed. We propose an approach integrating filters to optimize the model's attention mechanisms, prioritizing relevant objects and improving accuracy. Utilizing the LXMERT model for a case study, we compare attention patterns of the pre-trained and Filter Integrated models, alongside human answers using images from the NuImages dataset, gaining insights into feature prioritization. We evaluated the models using a Subjective scoring framework which shows that the integration of the feature encoder filter has enhanced the performance of the VQA model by refining its attention mechanisms.
6/14/2024
Design as Desired: Utilizing Visual Question Answering for Multimodal Pre-training
Tongkun Su, Jun Li, Xi Zhang, Haibo Jin, Hao Chen, Qiong Wang, Faqin Lv, Baoliang Zhao, Yin Hu
0
0
Multimodal pre-training demonstrates its potential in the medical domain, which learns medical visual representations from paired medical reports. However, many pre-training tasks require extra annotations from clinicians, and most of them fail to explicitly guide the model to learn the desired features of different pathologies. To the best of our knowledge, we are the first to utilize Visual Question Answering (VQA) for multimodal pre-training to guide the framework focusing on targeted pathological features. In this work, we leverage descriptions in medical reports to design multi-granular question-answer pairs associated with different diseases, which assist the framework in pre-training without requiring extra annotations from experts. We also propose a novel pre-training framework with a quasi-textual feature transformer, a module designed to transform visual features into a quasi-textual space closer to the textual domain via a contrastive learning strategy. This narrows the vision-language gap and facilitates modality alignment. Our framework is applied to four downstream tasks: report generation, classification, segmentation, and detection across five datasets. Extensive experiments demonstrate the superiority of our framework compared to other state-of-the-art methods. Our code will be released upon acceptance.
4/9/2024