PaliGemma: A versatile 3B VLM for transfer

202

Sign in to get full access
Overview
- Introduces PaliGemma, a versatile 3-billion parameter Vision-Language Model (VLM) for transfer learning
- Highlights PaliGemma's ability to achieve strong performance across a wide range of vision and language tasks
- Demonstrates PaliGemma's effectiveness in few-shot learning scenarios and its potential for practical applications
Plain English Explanation
PaliGemma is a large artificial intelligence (AI) model that can understand and generate both text and images. It was developed by researchers to be a versatile and powerful tool for transferring knowledge to different tasks.
The key idea behind PaliGemma is that by training on a massive amount of data, the model can learn general patterns and skills that can be applied to a wide variety of problems. This means that PaliGemma can be used as a starting point for training smaller, more specialized models for tasks like image classification, language translation, or even creative writing.
One of the main advantages of PaliGemma is its ability to learn quickly, even with just a few examples. This "few-shot learning" capability makes it useful for real-world applications where large labeled datasets may not be available. For example, PaliGemma could be used to build a system that can recognize and describe rare or unusual animals from just a handful of photos.
Overall, PaliGemma represents an important step forward in the development of large vision-language models that can go beyond human-level visual understanding and serve as powerful foundations for a wide range of AI applications.
Technical Explanation
The researchers behind PaliGemma developed a 3-billion parameter VLM that is trained on a diverse dataset of images and text. The model architecture is based on the popular LLAVA design, which uses a transformer-based encoder-decoder structure to jointly process and generate both visual and textual information.
During training, PaliGemma is exposed to a wide range of tasks, including image classification, visual question answering, image captioning, and natural language processing. This multitask learning approach allows the model to acquire a rich set of skills that can be leveraged for downstream applications.
The researchers demonstrate PaliGemma's effectiveness through extensive experiments on various benchmark datasets. They show that PaliGemma can achieve competitive or state-of-the-art performance on tasks like zero-shot image classification and few-shot learning, outperforming smaller, task-specialized models.
Critical Analysis
While the results presented in the paper are impressive, it's important to consider some potential limitations and areas for future research:
-
The size and complexity of PaliGemma may make it computationally expensive to fine-tune or deploy in some real-world scenarios, especially on resource-constrained devices. Techniques for model compression or distillation could help address this issue.
-
The paper does not provide a detailed analysis of PaliGemma's performance on more subjective or creative tasks, such as open-ended text generation or artistic image synthesis. Further research is needed to understand the model's capabilities and limitations in these areas.
-
While PaliGemma's few-shot learning abilities are promising, the paper does not explore the underlying mechanisms that enable this behavior. Additional research could help elucidate the learning strategies that allow the model to generalize effectively from limited data.
Overall, PaliGemma represents an exciting development in the field of large vision-language models, and the researchers have demonstrated its potential for a wide range of applications. However, continued investigation and refinement will be necessary to fully harness the power of this technology.
Conclusion
The PaliGemma model introduced in this paper is a versatile and powerful 3-billion parameter VLM that can be effectively used for transfer learning across a wide range of vision and language tasks. Its strong performance, particularly in few-shot learning scenarios, suggests that it could be a valuable tool for building practical AI applications with limited data.
While the paper highlights the impressive capabilities of PaliGemma, it also raises important questions about the model's scalability, generalization abilities, and potential biases. Addressing these concerns through further research and development will be crucial for realizing the full potential of large vision-language models like PaliGemma.
Overall, the PaliGemma paper represents an important contribution to the field of multimodal AI, and the insights and techniques presented here could help pave the way for even more sophisticated and capable AI systems in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
202
PaliGemma: A versatile 3B VLM for transfer
Lucas Beyer, Andreas Steiner, Andr'e Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, Thomas Unterthiner, Daniel Keysers, Skanda Koppula, Fangyu Liu, Adam Grycner, Alexey Gritsenko, Neil Houlsby, Manoj Kumar, Keran Rong, Julian Eisenschlos, Rishabh Kabra, Matthias Bauer, Matko Bov{s}njak, Xi Chen, Matthias Minderer, Paul Voigtlaender, Ioana Bica, Ivana Balazevic, Joan Puigcerver, Pinelopi Papalampidi, Olivier Henaff, Xi Xiong, Radu Soricut, Jeremiah Harmsen, Xiaohua Zhai
PaliGemma is an open Vision-Language Model (VLM) that is based on the SigLIP-So400m vision encoder and the Gemma-2B language model. It is trained to be a versatile and broadly knowledgeable base model that is effective to transfer. It achieves strong performance on a wide variety of open-world tasks. We evaluate PaliGemma on almost 40 diverse tasks including standard VLM benchmarks, but also more specialized tasks such as remote-sensing and segmentation.
Read more7/11/2024
0
LLaVA-Gemma: Accelerating Multimodal Foundation Models with a Compact Language Model
Musashi Hinck, Matthew L. Olson, David Cobbley, Shao-Yen Tseng, Vasudev Lal
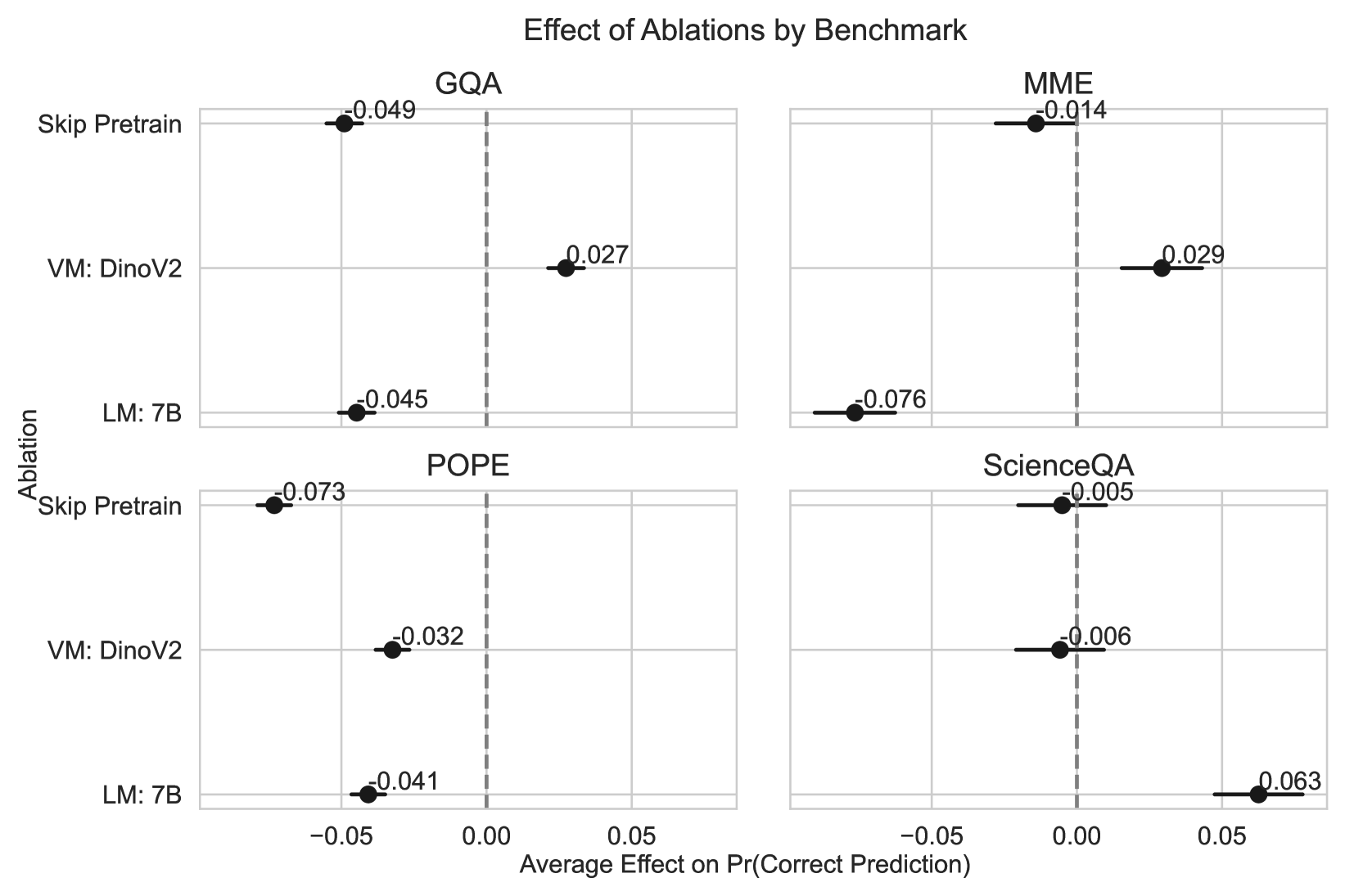
We train a suite of multimodal foundation models (MMFM) using the popular LLaVA framework with the recently released Gemma family of large language models (LLMs). Of particular interest is the 2B parameter Gemma model, which provides opportunities to construct capable small-scale MMFMs. In line with findings from other papers in this space, we test the effect of ablating three design features: pretraining the connector, utilizing a more powerful image backbone, and increasing the size of the language backbone. The resulting models, which we call LLaVA-Gemma, exhibit moderate performance on an array of evaluations, but fail to improve past the current comparably sized SOTA models. Closer analysis of performance shows mixed effects; skipping pretraining tends to reduce performance, larger vision models sometimes improve performance, and increasing language model size has inconsistent effects. We publicly release training recipes, code and weights for our models for the LLaVA-Gemma models.
Read more6/12/2024
0
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivi`ere, Mihir Sanjay Kale, Juliette Love, Pouya Tafti, L'eonard Hussenot, Pier Giuseppe Sessa, Aakanksha Chowdhery, Adam Roberts, Aditya Barua, Alex Botev, Alex Castro-Ros, Ambrose Slone, Am'elie H'eliou, Andrea Tacchetti, Anna Bulanova, Antonia Paterson, Beth Tsai, Bobak Shahriari, Charline Le Lan, Christopher A. Choquette-Choo, Cl'ement Crepy, Daniel Cer, Daphne Ippolito, David Reid, Elena Buchatskaya, Eric Ni, Eric Noland, Geng Yan, George Tucker, George-Christian Muraru, Grigory Rozhdestvenskiy, Henryk Michalewski, Ian Tenney, Ivan Grishchenko, Jacob Austin, James Keeling, Jane Labanowski, Jean-Baptiste Lespiau, Jeff Stanway, Jenny Brennan, Jeremy Chen, Johan Ferret, Justin Chiu, Justin Mao-Jones, Katherine Lee, Kathy Yu, Katie Millican, Lars Lowe Sjoesund, Lisa Lee, Lucas Dixon, Machel Reid, Maciej Miku{l}a, Mateo Wirth, Michael Sharman, Nikolai Chinaev, Nithum Thain, Olivier Bachem, Oscar Chang, Oscar Wahltinez, Paige Bailey, Paul Michel, Petko Yotov, Rahma Chaabouni, Ramona Comanescu, Reena Jana, Rohan Anil, Ross McIlroy, Ruibo Liu, Ryan Mullins, Samuel L Smith, Sebastian Borgeaud, Sertan Girgin, Sholto Douglas, Shree Pandya, Siamak Shakeri, Soham De, Ted Klimenko, Tom Hennigan, Vlad Feinberg, Wojciech Stokowiec, Yu-hui Chen, Zafarali Ahmed, Zhitao Gong, Tris Warkentin, Ludovic Peran, Minh Giang, Cl'ement Farabet, Oriol Vinyals, Jeff Dean, Koray Kavukcuoglu, Demis Hassabis, Zoubin Ghahramani, Douglas Eck, Joelle Barral, Fernando Pereira, Eli Collins, Armand Joulin, Noah Fiedel, Evan Senter, Alek Andreev, Kathleen Kenealy
This work introduces Gemma, a family of lightweight, state-of-the art open models built from the research and technology used to create Gemini models. Gemma models demonstrate strong performance across academic benchmarks for language understanding, reasoning, and safety. We release two sizes of models (2 billion and 7 billion parameters), and provide both pretrained and fine-tuned checkpoints. Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks, and we present comprehensive evaluations of safety and responsibility aspects of the models, alongside a detailed description of model development. We believe the responsible release of LLMs is critical for improving the safety of frontier models, and for enabling the next wave of LLM innovations.
Read more4/17/2024

0
Vision-Language Model Based Handwriting Verification
Mihir Chauhan, Abhishek Satbhai, Mohammad Abuzar Hashemi, Mir Basheer Ali, Bina Ramamurthy, Mingchen Gao, Siwei Lyu, Sargur Srihari
Handwriting Verification is a critical in document forensics. Deep learning based approaches often face skepticism from forensic document examiners due to their lack of explainability and reliance on extensive training data and handcrafted features. This paper explores using Vision Language Models (VLMs), such as OpenAI's GPT-4o and Google's PaliGemma, to address these challenges. By leveraging their Visual Question Answering capabilities and 0-shot Chain-of-Thought (CoT) reasoning, our goal is to provide clear, human-understandable explanations for model decisions. Our experiments on the CEDAR handwriting dataset demonstrate that VLMs offer enhanced interpretability, reduce the need for large training datasets, and adapt better to diverse handwriting styles. However, results show that the CNN-based ResNet-18 architecture outperforms the 0-shot CoT prompt engineering approach with GPT-4o (Accuracy: 70%) and supervised fine-tuned PaliGemma (Accuracy: 71%), achieving an accuracy of 84% on the CEDAR AND dataset. These findings highlight the potential of VLMs in generating human-interpretable decisions while underscoring the need for further advancements to match the performance of specialized deep learning models.
Read more8/1/2024