Language-Guided Object-Centric Diffusion Policy for Collision-Aware Robotic Manipulation

0

Sign in to get full access
Overview
- This paper introduces a language-guided object-centric diffusion policy for collision-aware robotic manipulation tasks.
- The proposed approach uses language instructions to guide the policy learning process and improve the generalization of the learned policies to new tasks and environments.
- The policy is trained using 3D diffusion models and is capable of handling collisions and constraints during the manipulation process.
Plain English Explanation
The researchers developed a new way for robots to learn how to manipulate objects in their environment. Their approach uses language-guided object-centric diffusion policy to teach robots how to complete various tasks, like picking up and moving objects, while avoiding collisions.
The key idea is to provide the robot with language instructions that describe the task, rather than just showing it examples. This helps the robot understand the high-level goal and generalize the learned skills to new situations. For example, the robot might learn from instructions like "pick up the red cup and place it on the table."
The researchers train the robot's policy using 3D diffusion models, which are a type of machine learning algorithm that can generate diverse and realistic manipulation motions. This allows the robot to handle complex constraints and collisions during the task execution.
Overall, this approach aims to make robots more flexible and adaptable, so they can follow high-level instructions and navigate unpredictable environments to complete a wide range of manipulation tasks.
Technical Explanation
The paper presents a language-guided object-centric diffusion policy for collision-aware robotic manipulation. The key components of the proposed approach are:
-
Language Conditioning: The policy is conditioned on natural language instructions that describe the task, in addition to the robot's observations. This allows the policy to learn task-relevant skills and generalize to new situations.
-
Object-Centric Representation: The policy operates on an object-centric representation of the scene, which encodes information about individual objects and their properties. This helps the policy reason about the manipulation of specific objects.
-
3D Diffusion Policy: The policy is trained using a 3D diffusion model, which can generate diverse and realistic manipulation motions while respecting physical constraints and avoiding collisions.
-
Constrained Inpainting: The policy uses a constrained inpainting mechanism to plan manipulation actions that satisfy task-specific constraints, such as avoiding obstacles or maintaining object stability.
The researchers evaluate the proposed approach on a range of robotic manipulation tasks, including picking, placing, and packing objects. The results show that the language-guided, object-centric diffusion policy outperforms baseline methods in terms of task success rate and generalization to new environments.
Critical Analysis
The paper presents a compelling approach to improving the flexibility and generalization of robotic manipulation policies. By incorporating language instructions and object-centric representations, the proposed method can learn task-relevant skills that are more transferable to new situations.
However, the paper does not provide a thorough analysis of the limitations and potential issues with the approach. For example, it is unclear how the policy would perform in the presence of significant clutter or complex object interactions, which could pose challenges for the constraint-guided diffusion policies used in the system.
Additionally, the paper does not discuss the computational and memory requirements of the 3D diffusion model, which could be a concern for real-world deployment on resource-constrained robotic platforms. Further research is needed to assess the scalability and efficiency of the proposed approach.
Overall, the paper presents a promising direction for improving the versatility and robustness of robotic manipulation systems, but more work is needed to fully understand the limitations and potential issues of the approach.
Conclusion
This paper introduces a novel language-guided object-centric diffusion policy for collision-aware robotic manipulation. The key innovation is the use of natural language instructions to guide the policy learning process and improve the generalization of the learned skills to new tasks and environments.
By incorporating object-centric representations and 3D diffusion models, the proposed approach can generate diverse and realistic manipulation motions while respecting physical constraints and avoiding collisions. The experimental results demonstrate the effectiveness of the method on a range of robotic manipulation tasks.
While the paper presents a compelling approach, further research is needed to fully understand the limitations and scalability of the proposed system. Nonetheless, this work represents an important step towards developing more flexible and adaptable robotic manipulation capabilities, with potential applications in areas such as household assistance, logistics, and manufacturing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Language-Guided Object-Centric Diffusion Policy for Collision-Aware Robotic Manipulation
Hang Li, Qian Feng, Zhi Zheng, Jianxiang Feng, Alois Knoll
Learning from demonstrations faces challenges in generalizing beyond the training data and is fragile even to slight visual variations. To tackle this problem, we introduce Lan-o3dp, a language guided object centric diffusion policy that takes 3d representation of task relevant objects as conditional input and can be guided by cost function for safety constraints at inference time. Lan-o3dp enables strong generalization in various aspects, such as background changes, visual ambiguity and can avoid novel obstacles that are unseen during the demonstration process. Specifically, We first train a diffusion policy conditioned on point clouds of target objects and then harness a large language model to decompose the user instruction into task related units consisting of target objects and obstacles, which can be used as visual observation for the policy network or converted to a cost function, guiding the generation of trajectory towards collision free region at test time. Our proposed method shows training efficiency and higher success rates compared with the baselines in simulation experiments. In real world experiments, our method exhibits strong generalization performance towards unseen instances, cluttered scenes, scenes of multiple similar objects and demonstrates training free capability of obstacle avoidance.
Read more7/8/2024
0
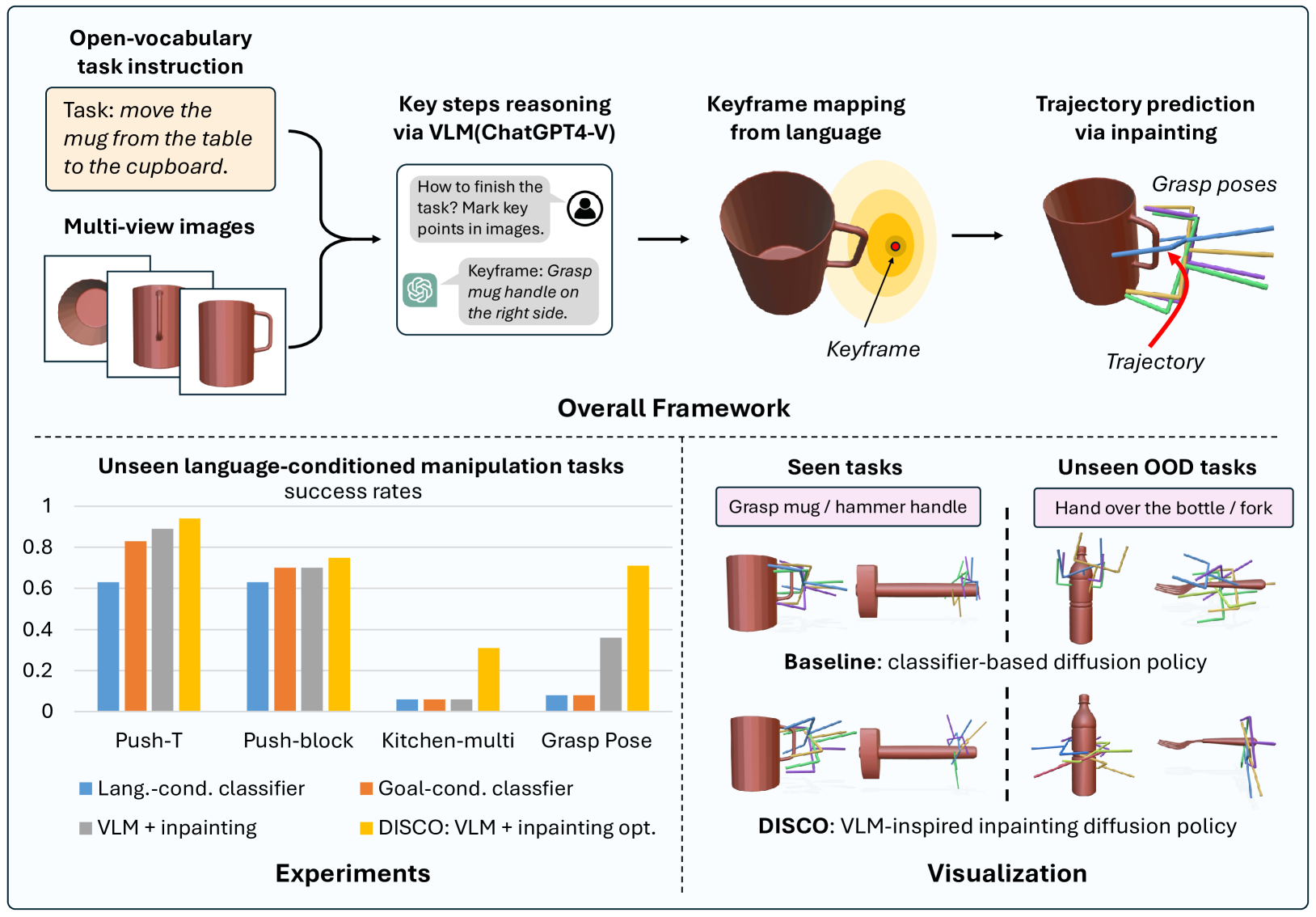
Language-Guided Manipulation with Diffusion Policies and Constrained Inpainting
Ce Hao, Kelvin Lin, Siyuan Luo, Harold Soh
Diffusion policies have demonstrated robust performance in generative modeling, prompting their application in robotic manipulation controlled via language descriptions. In this paper, we introduce a zero-shot, open-vocabulary diffusion policy method for robot manipulation. Using Vision-Language Models (VLMs), our method transforms linguistic task descriptions into actionable keyframes in 3D space. These keyframes serve to guide the diffusion process via inpainting. However, naively enforcing the diffusion process to adhere to the generated keyframes is problematic: the keyframes from the VLMs may be incorrect and lead to action sequences where the diffusion model performs poorly. To address these challenges, we develop an inpainting optimization strategy that balances adherence to the keyframes v.s. the training data distribution. Experimental evaluations demonstrate that our approach surpasses the performance of traditional fine-tuned language-conditioned methods in both simulated and real-world settings.
Read more9/24/2024
0
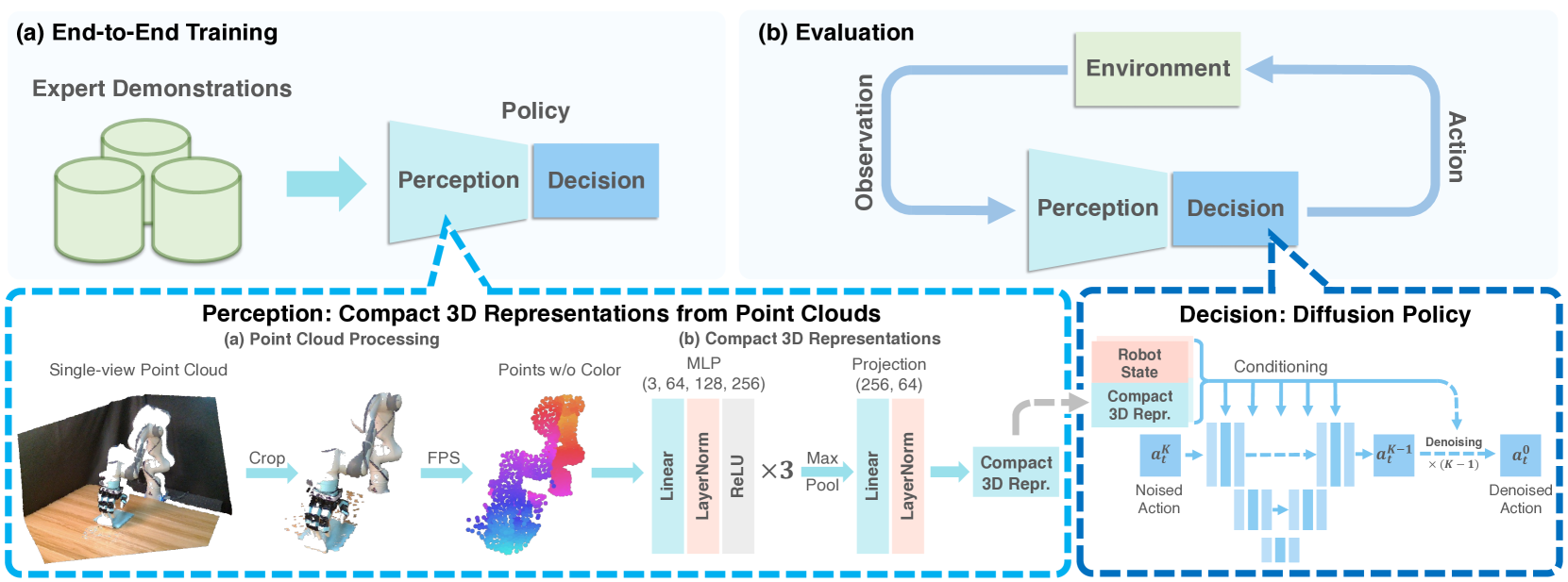
3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, Huazhe Xu
Imitation learning provides an efficient way to teach robots dexterous skills; however, learning complex skills robustly and generalizablely usually consumes large amounts of human demonstrations. To tackle this challenging problem, we present 3D Diffusion Policy (DP3), a novel visual imitation learning approach that incorporates the power of 3D visual representations into diffusion policies, a class of conditional action generative models. The core design of DP3 is the utilization of a compact 3D visual representation, extracted from sparse point clouds with an efficient point encoder. In our experiments involving 72 simulation tasks, DP3 successfully handles most tasks with just 10 demonstrations and surpasses baselines with a 24.2% relative improvement. In 4 real robot tasks, DP3 demonstrates precise control with a high success rate of 85%, given only 40 demonstrations of each task, and shows excellent generalization abilities in diverse aspects, including space, viewpoint, appearance, and instance. Interestingly, in real robot experiments, DP3 rarely violates safety requirements, in contrast to baseline methods which frequently do, necessitating human intervention. Our extensive evaluation highlights the critical importance of 3D representations in real-world robot learning. Videos, code, and data are available on https://3d-diffusion-policy.github.io .
Read more5/29/2024
🎯
0
Part-Guided 3D RL for Sim2Real Articulated Object Manipulation
Pengwei Xie, Rui Chen, Siang Chen, Yuzhe Qin, Fanbo Xiang, Tianyu Sun, Jing Xu, Guijin Wang, Hao Su
Manipulating unseen articulated objects through visual feedback is a critical but challenging task for real robots. Existing learning-based solutions mainly focus on visual affordance learning or other pre-trained visual models to guide manipulation policies, which face challenges for novel instances in real-world scenarios. In this paper, we propose a novel part-guided 3D RL framework, which can learn to manipulate articulated objects without demonstrations. We combine the strengths of 2D segmentation and 3D RL to improve the efficiency of RL policy training. To improve the stability of the policy on real robots, we design a Frame-consistent Uncertainty-aware Sampling (FUS) strategy to get a condensed and hierarchical 3D representation. In addition, a single versatile RL policy can be trained on multiple articulated object manipulation tasks simultaneously in simulation and shows great generalizability to novel categories and instances. Experimental results demonstrate the effectiveness of our framework in both simulation and real-world settings. Our code is available at https://github.com/THU-VCLab/Part-Guided-3D-RL-for-Sim2Real-Articulated-Object-Manipulation.
Read more4/29/2024