Pessimistic Value Iteration for Multi-Task Data Sharing in Offline Reinforcement Learning

0
📊
Sign in to get full access
Overview
- Offline Reinforcement Learning (RL) can learn task-specific policies from fixed datasets, but relies heavily on the coverage and quality of the dataset.
- When the dataset for a specific task is limited, a natural approach is to improve offline RL by using datasets from other tasks, known as Multi-Task Data Sharing (MTDS).
- However, directly sharing datasets from other tasks can exacerbate the distribution shift problem in offline RL.
- This paper proposes an uncertainty-based MTDS approach that shares the entire dataset without data selection, using ensemble-based uncertainty quantification and pessimistic value iteration.
Plain English Explanation
Reinforcement learning (RL) is a type of machine learning where an agent learns to perform a task by interacting with its environment and receiving rewards or penalties. Offline RL is a variant where the agent learns from a fixed dataset of past interactions, rather than learning through live interactions.
Offline RL has shown promise, but its success often depends on the quality and coverage of the dataset used. When the dataset for a specific task is limited, a natural approach is to use datasets from other related tasks to help the agent learn. This is called Multi-Task Data Sharing (MTDS).
However, directly sharing datasets from other tasks can cause problems. The data from the other tasks may have a different distribution, which can confuse the agent and lead to poor performance.
To address this, the researchers propose an "uncertainty-based MTDS" approach. This method uses ensemble-based uncertainty quantification to identify parts of the shared dataset that may be less reliable, and then performs "pessimistic value iteration" to learn a policy that is robust to this uncertainty.
The key idea is to use the entire shared dataset, rather than trying to carefully select which parts to use. This helps the agent learn from the broader set of experiences, while the uncertainty-based approach mitigates the issues caused by the distribution shift.
The researchers provide theoretical analysis showing that their method's performance depends only on the expected coverage of the shared dataset, not the distribution shift. They also release a new MTDS benchmark dataset and show their algorithm outperforms previous state-of-the-art methods on challenging MTDS problems.
Technical Explanation
The paper proposes an uncertainty-based Multi-Task Data Sharing (MTDS) approach for offline reinforcement learning (RL). The key elements are:
-
Uncertainty Quantification: The method uses ensemble-based uncertainty quantification to estimate the reliability of each datapoint in the shared offline dataset from multiple tasks. This provides a measure of the uncertainty associated with each observation.
-
Pessimistic Value Iteration: The algorithm then performs "pessimistic value iteration" on the shared dataset, where it considers the worst-case value for each state-action pair based on the estimated uncertainty. This helps the agent learn a policy that is robust to the distribution shift caused by merging datasets from different tasks.
-
Unified Framework: The proposed approach provides a unified framework for single-task and multi-task offline RL. By sharing the entire dataset without selective data sharing, it avoids the distribution shift issues that plague direct MTDS methods.
-
Theoretical Analysis: The paper provides a theoretical analysis showing that the optimality gap of the proposed method is only related to the expected data coverage of the shared dataset, not the distribution shift. This resolves a key challenge in MTDS.
-
Benchmark and Experiments: The researchers release a new MTDS benchmark dataset covering three challenging domains. The experimental results demonstrate that their algorithm outperforms previous state-of-the-art methods on these MTDS problems.
The key insight is that by quantifying the uncertainty in the shared dataset and using a pessimistic approach, the method can effectively leverage data from multiple tasks without suffering from distribution shift issues. This advances the state-of-the-art in offline RL, particularly for scenarios where the dataset for a specific task is limited.
Critical Analysis
The paper presents a novel and promising approach to addressing the distribution shift problem in Multi-Task Data Sharing for offline reinforcement learning. The theoretical analysis provides strong guarantees on the performance of the method, and the empirical results on the new MTDS benchmark are compelling.
One potential limitation is the reliance on ensemble-based uncertainty quantification, which may be computationally expensive or require careful hyperparameter tuning. It would be interesting to see if alternative uncertainty estimation techniques, such as those proposed in Diverse Randomized Value Functions: A Provably Pessimistic Approach to Offline RL or Distributionally Robust Reinforcement Learning for Interactive Data Collection, could be integrated into the MTDS framework.
Additionally, the paper focuses on the offline RL setting, but it would be valuable to explore how the uncertainty-based MTDS approach could be extended to off-policy reinforcement learning algorithms customized for multi-task settings or single-task continual offline reinforcement learning, where the agent must learn and adapt to new tasks over time.
Overall, this paper makes a significant contribution to the field of offline reinforcement learning by providing a novel and principled approach to leveraging multi-task data in a way that mitigates the distribution shift problem.
Conclusion
This paper presents an uncertainty-based Multi-Task Data Sharing (MTDS) approach for offline reinforcement learning. By quantifying the uncertainty in the shared dataset and using a pessimistic value iteration strategy, the method can effectively leverage data from multiple tasks without suffering from distribution shift issues.
The key contributions of this work include the theoretical analysis showing the optimality gap is only related to the expected data coverage, the release of a new MTDS benchmark dataset, and the empirical results demonstrating the superior performance of the proposed algorithm compared to previous state-of-the-art methods.
This research advances the field of offline RL, particularly in scenarios where the dataset for a specific task is limited. The uncertainty-based MTDS approach provides a unified framework for single-task and multi-task offline RL, and the insights from this work could inspire further developments in leveraging diverse datasets for robust and efficient reinforcement learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Pessimistic Value Iteration for Multi-Task Data Sharing in Offline Reinforcement Learning
Chenjia Bai, Lingxiao Wang, Jianye Hao, Zhuoran Yang, Bin Zhao, Zhen Wang, Xuelong Li
Offline Reinforcement Learning (RL) has shown promising results in learning a task-specific policy from a fixed dataset. However, successful offline RL often relies heavily on the coverage and quality of the given dataset. In scenarios where the dataset for a specific task is limited, a natural approach is to improve offline RL with datasets from other tasks, namely, to conduct Multi-Task Data Sharing (MTDS). Nevertheless, directly sharing datasets from other tasks exacerbates the distribution shift in offline RL. In this paper, we propose an uncertainty-based MTDS approach that shares the entire dataset without data selection. Given ensemble-based uncertainty quantification, we perform pessimistic value iteration on the shared offline dataset, which provides a unified framework for single- and multi-task offline RL. We further provide theoretical analysis, which shows that the optimality gap of our method is only related to the expected data coverage of the shared dataset, thus resolving the distribution shift issue in data sharing. Empirically, we release an MTDS benchmark and collect datasets from three challenging domains. The experimental results show our algorithm outperforms the previous state-of-the-art methods in challenging MTDS problems. See https://github.com/Baichenjia/UTDS for the datasets and code.
Read more5/1/2024
0
Urban-Focused Multi-Task Offline Reinforcement Learning with Contrastive Data Sharing
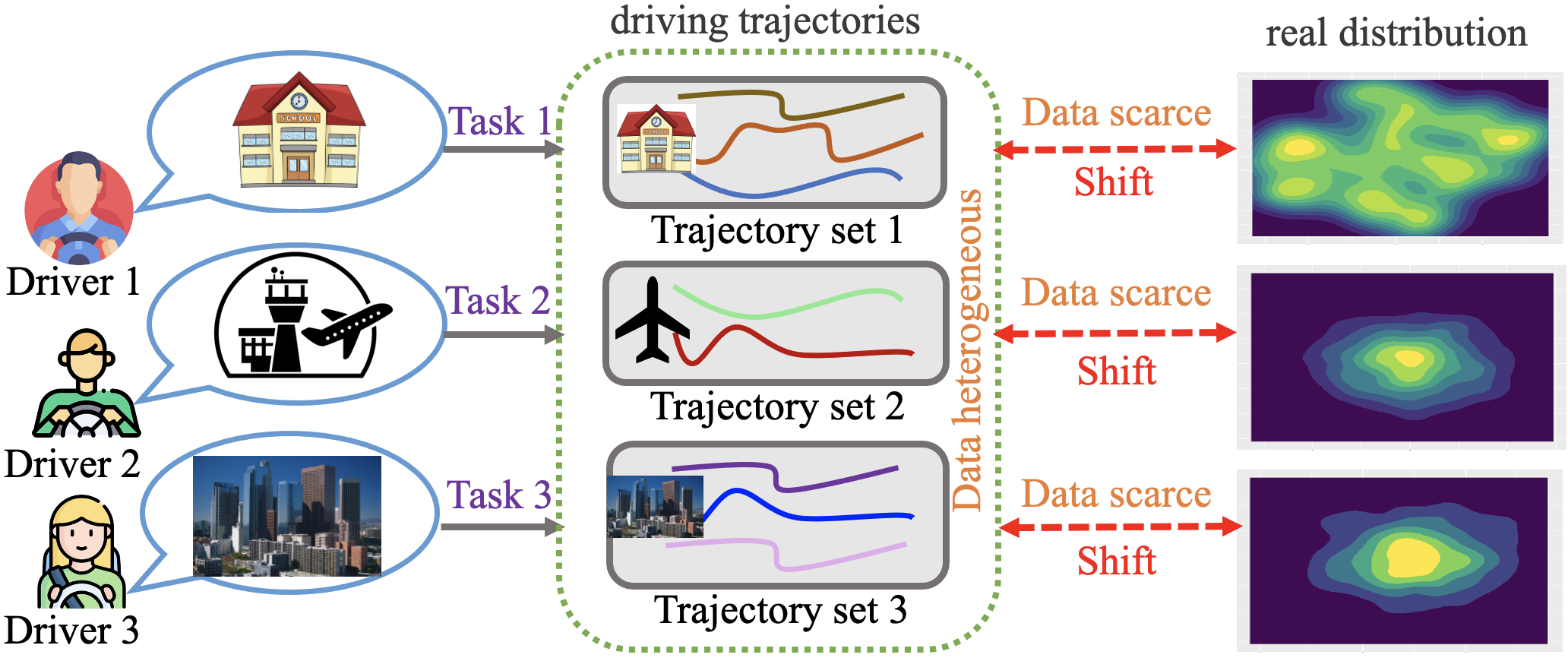
Xinbo Zhao, Yingxue Zhang, Xin Zhang, Yu Yang, Yiqun Xie, Yanhua Li, Jun Luo
Enhancing diverse human decision-making processes in an urban environment is a critical issue across various applications, including ride-sharing vehicle dispatching, public transportation management, and autonomous driving. Offline reinforcement learning (RL) is a promising approach to learn and optimize human urban strategies (or policies) from pre-collected human-generated spatial-temporal urban data. However, standard offline RL faces two significant challenges: (1) data scarcity and data heterogeneity, and (2) distributional shift. In this paper, we introduce MODA -- a Multi-Task Offline Reinforcement Learning with Contrastive Data Sharing approach. MODA addresses the challenges of data scarcity and heterogeneity in a multi-task urban setting through Contrastive Data Sharing among tasks. This technique involves extracting latent representations of human behaviors by contrasting positive and negative data pairs. It then shares data presenting similar representations with the target task, facilitating data augmentation for each task. Moreover, MODA develops a novel model-based multi-task offline RL algorithm. This algorithm constructs a robust Markov Decision Process (MDP) by integrating a dynamics model with a Generative Adversarial Network (GAN). Once the robust MDP is established, any online RL or planning algorithm can be applied. Extensive experiments conducted in a real-world multi-task urban setting validate the effectiveness of MODA. The results demonstrate that MODA exhibits significant improvements compared to state-of-the-art baselines, showcasing its capability in advancing urban decision-making processes. We also made our code available to the research community.
Read more6/21/2024

0
D5RL: Diverse Datasets for Data-Driven Deep Reinforcement Learning
Rafael Rafailov, Kyle Hatch, Anikait Singh, Laura Smith, Aviral Kumar, Ilya Kostrikov, Philippe Hansen-Estruch, Victor Kolev, Philip Ball, Jiajun Wu, Chelsea Finn, Sergey Levine
Offline reinforcement learning algorithms hold the promise of enabling data-driven RL methods that do not require costly or dangerous real-world exploration and benefit from large pre-collected datasets. This in turn can facilitate real-world applications, as well as a more standardized approach to RL research. Furthermore, offline RL methods can provide effective initializations for online finetuning to overcome challenges with exploration. However, evaluating progress on offline RL algorithms requires effective and challenging benchmarks that capture properties of real-world tasks, provide a range of task difficulties, and cover a range of challenges both in terms of the parameters of the domain (e.g., length of the horizon, sparsity of rewards) and the parameters of the data (e.g., narrow demonstration data or broad exploratory data). While considerable progress in offline RL in recent years has been enabled by simpler benchmark tasks, the most widely used datasets are increasingly saturating in performance and may fail to reflect properties of realistic tasks. We propose a new benchmark for offline RL that focuses on realistic simulations of robotic manipulation and locomotion environments, based on models of real-world robotic systems, and comprising a variety of data sources, including scripted data, play-style data collected by human teleoperators, and other data sources. Our proposed benchmark covers state-based and image-based domains, and supports both offline RL and online fine-tuning evaluation, with some of the tasks specifically designed to require both pre-training and fine-tuning. We hope that our proposed benchmark will facilitate further progress on both offline RL and fine-tuning algorithms. Website with code, examples, tasks, and data is available at url{https://sites.google.com/view/d5rl/}
Read more8/19/2024

0
Offline Policy Evaluation for Reinforcement Learning with Adaptively Collected Data
Sunil Madhow, Dan Qiao, Ming Yin, Yu-Xiang Wang
Developing theoretical guarantees on the sample complexity of offline RL methods is an important step towards making data-hungry RL algorithms practically viable. Currently, most results hinge on unrealistic assumptions about the data distribution -- namely that it comprises a set of i.i.d. trajectories collected by a single logging policy. We consider a more general setting where the dataset may have been gathered adaptively. We develop theory for the TMIS Offline Policy Evaluation (OPE) estimator in this generalized setting for tabular MDPs, deriving high-probability, instance-dependent bounds on its estimation error. We also recover minimax-optimal offline learning in the adaptive setting. Finally, we conduct simulations to empirically analyze the behavior of these estimators under adaptive and non-adaptive regimes.
Read more5/2/2024