PhenDiff: Revealing Subtle Phenotypes with Diffusion Models in Real Images

0

Sign in to get full access
Overview
- The paper introduces PhenDiff, a conditional diffusion model for revealing invisible phenotypes in medical images.
- PhenDiff can generate realistic images that reveal hidden features not visible in the original input, enabling improved diagnosis and disease understanding.
- The model is trained on paired images representing visible and invisible phenotypes, and can then be used to generate new images that highlight the unseen characteristics.
Plain English Explanation
PhenDiff is a new machine learning model that can uncover hidden details in medical images. Often, important information about a person's health condition may not be visible just by looking at an x-ray or other scan. PhenDiff is trained to recognize these "invisible phenotypes" - subtle signs of disease that are hard for the human eye to detect.
Once trained, PhenDiff can take a medical image as input and generate a new image that highlights the invisible features. This could help doctors better understand a patient's condition and make more accurate diagnoses. For example, PhenDiff might be able to reveal early signs of cancer or other diseases that are difficult to spot initially.
The key innovation is PhenDiff's use of a "conditional diffusion model" - a type of AI that can gradually transform an input image into a new one with added detail. By training on paired examples of visible and invisible phenotypes, PhenDiff learns to generate the hidden information that's missing from the original image.
Technical Explanation
The paper introduces PhenDiff: Revealing Invisible Phenotypes with Conditional Diffusion Models, a novel conditional diffusion model for uncovering invisible phenotypes in medical images. Diffusion models are a type of generative AI that can transform an input into a new, realistic-looking output.
PhenDiff is trained on paired datasets of medical images, where each input image is matched with a corresponding "ground truth" image that reveals the invisible phenotypes. Using this training data, PhenDiff learns to gradually transform the input image into one that highlights the hidden characteristics.
The model architecture combines a U-Net-style encoder-decoder with a diffusion process that progressively adds noise to the input and then reverses this process to generate the final output. Experiments on chest X-ray and brain MRI datasets show that PhenDiff can generate realistic images that uncover invisible features related to disease markers and anatomical abnormalities.
Compared to other image-to-image translation approaches like RE-DiffINet and FitDiff, PhenDiff demonstrates improved performance in revealing hidden phenotypes. The authors also show how PhenDiff can be combined with conditional GANs, as in Distilling Diffusion Models, to further enhance the generated image quality.
Critical Analysis
The paper presents a compelling approach for uncovering invisible phenotypes in medical imaging data. By leveraging the power of diffusion models, PhenDiff is able to generate realistic images that highlight hidden disease markers and anatomical features that are difficult for humans to detect.
One potential limitation is the reliance on paired training data, where each input image must be matched with a corresponding "ground truth" image revealing the invisible phenotypes. Collecting such paired datasets can be challenging, especially for rare or hard-to-detect conditions. The authors acknowledge this issue and suggest exploring self-supervised or weakly-supervised learning approaches as future work.
Another consideration is the interpretability of the generated images. While PhenDiff can produce visually striking outputs, it's important to ensure that the highlighted features are clinically meaningful and can be reliably interpreted by medical professionals. Further research may be needed to validate the clinical utility of PhenDiff's outputs.
Overall, the PhenDiff approach represents an exciting development in the field of medical image analysis, with the potential to greatly improve disease diagnosis and understanding. As the authors note, combining PhenDiff with other AI techniques like HiDiff could lead to even more powerful and versatile tools for revealing invisible phenotypes.
Conclusion
The PhenDiff paper presents a novel conditional diffusion model for uncovering invisible phenotypes in medical images. By leveraging paired datasets of visible and hidden characteristics, PhenDiff can generate realistic images that highlight important disease markers and anatomical features that are often overlooked.
This technology has the potential to significantly improve disease diagnosis and understanding, as it can reveal crucial information that is typically invisible to the human eye. While the reliance on paired training data and the interpretability of the generated images present some challenges, the overall approach represents an exciting step forward in the field of medical image analysis.
As AI models like PhenDiff continue to advance, we may see significant advancements in our ability to detect and treat a wide range of medical conditions, ultimately leading to better health outcomes for patients.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PhenDiff: Revealing Subtle Phenotypes with Diffusion Models in Real Images
Anis Bourou, Thomas Boyer, K'evin Daupin, V'eronique Dubreuil, Aur'elie De Thonel, Val'erie Mezger, Auguste Genovesio
For the past few years, deep generative models have increasingly been used in biological research for a variety of tasks. Recently, they have proven to be valuable for uncovering subtle cell phenotypic differences that are not directly discernible to the human eye. However, current methods employed to achieve this goal mainly rely on Generative Adversarial Networks (GANs). While effective, GANs encompass issues such as training instability and mode collapse, and they do not accurately map images back to the model's latent space, which is necessary to synthesize, manipulate, and thus interpret outputs based on real images. In this work, we introduce PhenDiff: a multi-class conditional method leveraging Diffusion Models (DMs) designed to identify shifts in cellular phenotypes by translating a real image from one condition to another. We qualitatively and quantitatively validate this method on cases where the phenotypic changes are visible or invisible, such as in low concentrations of drug treatments. Overall, PhenDiff represents a valuable tool for identifying cellular variations in real microscopy images. We anticipate that it could facilitate the understanding of diseases and advance drug discovery through the identification of novel biomarkers.
Read more7/11/2024
0
Image Neural Field Diffusion Models
Yinbo Chen, Oliver Wang, Richard Zhang, Eli Shechtman, Xiaolong Wang, Michael Gharbi
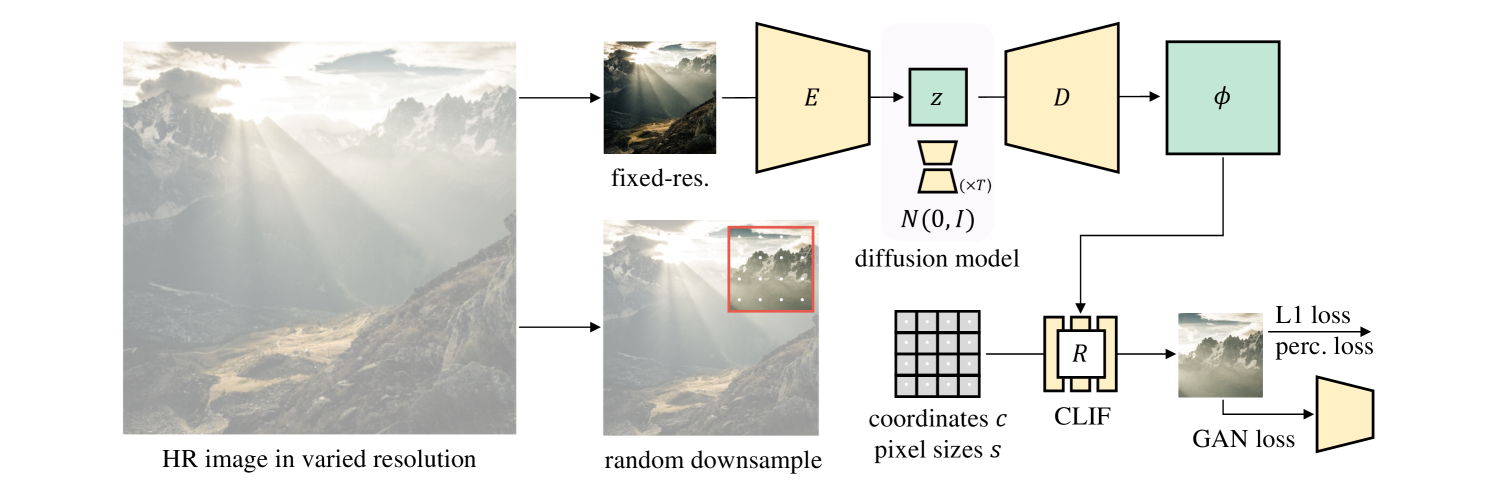
Diffusion models have shown an impressive ability to model complex data distributions, with several key advantages over GANs, such as stable training, better coverage of the training distribution's modes, and the ability to solve inverse problems without extra training. However, most diffusion models learn the distribution of fixed-resolution images. We propose to learn the distribution of continuous images by training diffusion models on image neural fields, which can be rendered at any resolution, and show its advantages over fixed-resolution models. To achieve this, a key challenge is to obtain a latent space that represents photorealistic image neural fields. We propose a simple and effective method, inspired by several recent techniques but with key changes to make the image neural fields photorealistic. Our method can be used to convert existing latent diffusion autoencoders into image neural field autoencoders. We show that image neural field diffusion models can be trained using mixed-resolution image datasets, outperform fixed-resolution diffusion models followed by super-resolution models, and can solve inverse problems with conditions applied at different scales efficiently.
Read more6/12/2024
📉
0
Re-DiffiNet: Modeling discrepancies in tumor segmentation using diffusion models
Tianyi Ren, Abhishek Sharma, Juampablo Heras Rivera, Harshitha Rebala, Ethan Honey, Agamdeep Chopra, Jacob Ruzevick, Mehmet Kurt
Identification of tumor margins is essential for surgical decision-making for glioblastoma patients and provides reliable assistance for neurosurgeons. Despite improvements in deep learning architectures for tumor segmentation over the years, creating a fully autonomous system suitable for clinical floors remains a formidable challenge because the model predictions have not yet reached the desired level of accuracy and generalizability for clinical applications. Generative modeling techniques have seen significant improvements in recent times. Specifically, Generative Adversarial Networks (GANs) and Denoising-diffusion-based models (DDPMs) have been used to generate higher-quality images with fewer artifacts and finer attributes. In this work, we introduce a framework called Re-Diffinet for modeling the discrepancy between the outputs of a segmentation model like U-Net and the ground truth, using DDPMs. By explicitly modeling the discrepancy, the results show an average improvement of 0.55% in the Dice score and 16.28% in HD95 from cross-validation over 5-folds, compared to the state-of-the-art U-Net segmentation model.
Read more4/11/2024

0
Diffusion Models as Data Mining Tools
Ioannis Siglidis, Aleksander Holynski, Alexei A. Efros, Mathieu Aubry, Shiry Ginosar
This paper demonstrates how to use generative models trained for image synthesis as tools for visual data mining. Our insight is that since contemporary generative models learn an accurate representation of their training data, we can use them to summarize the data by mining for visual patterns. Concretely, we show that after finetuning conditional diffusion models to synthesize images from a specific dataset, we can use these models to define a typicality measure on that dataset. This measure assesses how typical visual elements are for different data labels, such as geographic location, time stamps, semantic labels, or even the presence of a disease. This analysis-by-synthesis approach to data mining has two key advantages. First, it scales much better than traditional correspondence-based approaches since it does not require explicitly comparing all pairs of visual elements. Second, while most previous works on visual data mining focus on a single dataset, our approach works on diverse datasets in terms of content and scale, including a historical car dataset, a historical face dataset, a large worldwide street-view dataset, and an even larger scene dataset. Furthermore, our approach allows for translating visual elements across class labels and analyzing consistent changes.
Read more8/7/2024