PicoAudio: Enabling Precise Timestamp and Frequency Controllability of Audio Events in Text-to-audio Generation

0

Sign in to get full access
Overview
- Presents PicoAudio, a system that enables precise control over the timestamp and frequency of audio events in text-to-audio generation
- Introduces a temporal controllable model that allows for fine-grained manipulation of when and at what pitch audio events occur
- Demonstrates how PicoAudio can be used to create more expressive and dynamic text-to-audio outputs compared to existing approaches
Plain English Explanation
PicoAudio is a new system that gives creators more control over the timing and pitch of sounds in text-to-audio generation. Traditionally, converting text to audio has been a challenge because it's difficult to precisely specify when different sounds should occur and at what frequencies. PicoAudio solves this by introducing a "temporal controllable model" that allows users to fine-tune the timing and pitch of audio events.
For example, with PicoAudio, you could generate audio of someone speaking a sentence and have specific sound effects, like a door slamming or a bird chirping, occur at exact moments and at specific pitches. This level of precision and control is not possible with existing text-to-audio systems, which tend to produce more generic and less dynamic audio outputs.
By enabling this kind of granular control, PicoAudio can create more expressive and compelling text-to-audio experiences. This could be useful for applications like audio storytelling, interactive voice assistants, or sound design for video games and movies, where precise timing and pitch of audio events is important.
Technical Explanation
The core of PicoAudio is its temporal controllable model, which builds on recent advancements in joint audio-symbolic conditioning and latent diffusion models for audio synthesis. The model takes text input and learns to generate corresponding audio waveforms, while also allowing users to precisely control the timing and frequency of individual audio events.
This is achieved through the use of specialized input representations that encode temporal and pitch information, along with architectural modifications to existing text-to-audio models. The system is trained on a dataset of audio clips with aligned textual descriptions, enabling it to learn the mapping between language and the corresponding audio characteristics.
During inference, the model can then generate audio outputs where the timing and frequency of different sound events are closely aligned with the input text, thanks to the fine-grained control mechanisms built into the architecture. This level of temporal and pitch controllability is a significant advancement over prior text-to-speech and text-to-audio systems.
Critical Analysis
The PicoAudio system represents an important step forward in text-to-audio generation, providing creators with unprecedented control over the temporal and frequency characteristics of the generated audio. However, the paper also acknowledges several limitations and areas for future work.
One key challenge is the need for a large, high-quality dataset of audio clips with detailed textual annotations, which can be labor-intensive to produce. The authors note that the performance of the system is heavily dependent on the quality and breadth of the training data.
Additionally, while PicoAudio demonstrates impressive results in terms of timing and pitch control, there may be tradeoffs in terms of other aspects of audio quality, such as naturalness or coherence. Further research is needed to understand the balance between controllability and other desirable properties of the generated audio.
Finally, the paper does not deeply explore the potential social and ethical implications of this technology, such as how it could be used for audio manipulation or the creation of synthetic media. As this field continues to advance, it will be important for researchers to consider these broader societal impacts.
Conclusion
Overall, the PicoAudio system represents a significant advancement in text-to-audio generation, enabling creators to have precise control over the timing and pitch of audio events. By providing this level of granular control, PicoAudio opens up new possibilities for applications that require dynamic and expressive audio, such as audio storytelling, interactive voice interfaces, and sound design. As the field of text-to-audio generation continues to evolve, systems like PicoAudio will play an increasingly important role in shaping the future of how we interact with and experience audio-based content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PicoAudio: Enabling Precise Timestamp and Frequency Controllability of Audio Events in Text-to-audio Generation
Zeyu Xie, Xuenan Xu, Zhizheng Wu, Mengyue Wu
Recently, audio generation tasks have attracted considerable research interests. Precise temporal controllability is essential to integrate audio generation with real applications. In this work, we propose a temporal controlled audio generation framework, PicoAudio. PicoAudio integrates temporal information to guide audio generation through tailored model design. It leverages data crawling, segmentation, filtering, and simulation of fine-grained temporally-aligned audio-text data. Both subjective and objective evaluations demonstrate that PicoAudio dramantically surpasses current state-of-the-art generation models in terms of timestamp and occurrence frequency controllability. The generated samples are available on the demo website https://zeyuxie29.github.io/PicoAudio.github.io.
Read more7/18/2024

0
AudioTime: A Temporally-aligned Audio-text Benchmark Dataset
Zeyu Xie, Xuenan Xu, Zhizheng Wu, Mengyue Wu
Recent advancements in audio generation have enabled the creation of high-fidelity audio clips from free-form textual descriptions. However, temporal relationships, a critical feature for audio content, are currently underrepresented in mainstream models, resulting in an imprecise temporal controllability. Specifically, users cannot accurately control the timestamps of sound events using free-form text. We acknowledge that a significant factor is the absence of high-quality, temporally-aligned audio-text datasets, which are essential for training models with temporal control. The more temporally-aligned the annotations, the better the models can understand the precise relationship between audio outputs and temporal textual prompts. Therefore, we present a strongly aligned audio-text dataset, AudioTime. It provides text annotations rich in temporal information such as timestamps, duration, frequency, and ordering, covering almost all aspects of temporal control. Additionally, we offer a comprehensive test set and evaluation metric to assess the temporal control performance of various models. Examples are available on the https://zeyuxie29.github.io/AudioTime/
Read more7/4/2024
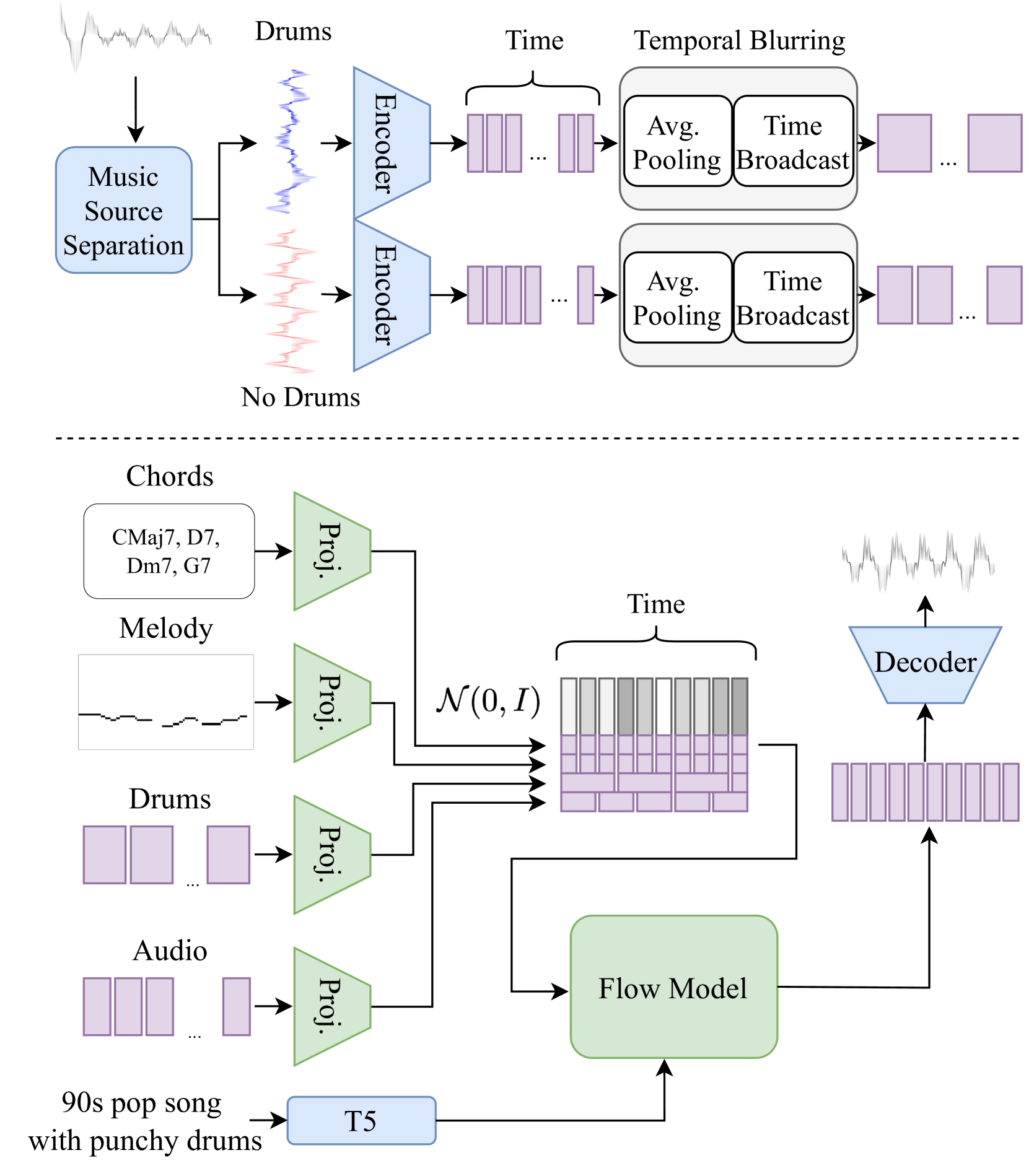
1
Joint Audio and Symbolic Conditioning for Temporally Controlled Text-to-Music Generation
Or Tal, Alon Ziv, Itai Gat, Felix Kreuk, Yossi Adi
We present JASCO, a temporally controlled text-to-music generation model utilizing both symbolic and audio-based conditions. JASCO can generate high-quality music samples conditioned on global text descriptions along with fine-grained local controls. JASCO is based on the Flow Matching modeling paradigm together with a novel conditioning method. This allows music generation controlled both locally (e.g., chords) and globally (text description). Specifically, we apply information bottleneck layers in conjunction with temporal blurring to extract relevant information with respect to specific controls. This allows the incorporation of both symbolic and audio-based conditions in the same text-to-music model. We experiment with various symbolic control signals (e.g., chords, melody), as well as with audio representations (e.g., separated drum tracks, full-mix). We evaluate JASCO considering both generation quality and condition adherence, using both objective metrics and human studies. Results suggest that JASCO is comparable to the evaluated baselines considering generation quality while allowing significantly better and more versatile controls over the generated music. Samples are available on our demo page https://pages.cs.huji.ac.il/adiyoss-lab/JASCO.
Read more6/18/2024

0
Dissecting Temporal Understanding in Text-to-Audio Retrieval
Andreea-Maria Oncescu, Jo~ao F. Henriques, A. Sophia Koepke
Recent advancements in machine learning have fueled research on multimodal tasks, such as for instance text-to-video and text-to-audio retrieval. These tasks require models to understand the semantic content of video and audio data, including objects, and characters. The models also need to learn spatial arrangements and temporal relationships. In this work, we analyse the temporal ordering of sounds, which is an understudied problem in the context of text-to-audio retrieval. In particular, we dissect the temporal understanding capabilities of a state-of-the-art model for text-to-audio retrieval on the AudioCaps and Clotho datasets. Additionally, we introduce a synthetic text-audio dataset that provides a controlled setting for evaluating temporal capabilities of recent models. Lastly, we present a loss function that encourages text-audio models to focus on the temporal ordering of events. Code and data are available at https://www.robots.ox.ac.uk/~vgg/research/audio-retrieval/dtu/.
Read more9/4/2024