SatCLIP: Global, General-Purpose Location Embeddings with Satellite Imagery
2311.17179
0
0
Abstract
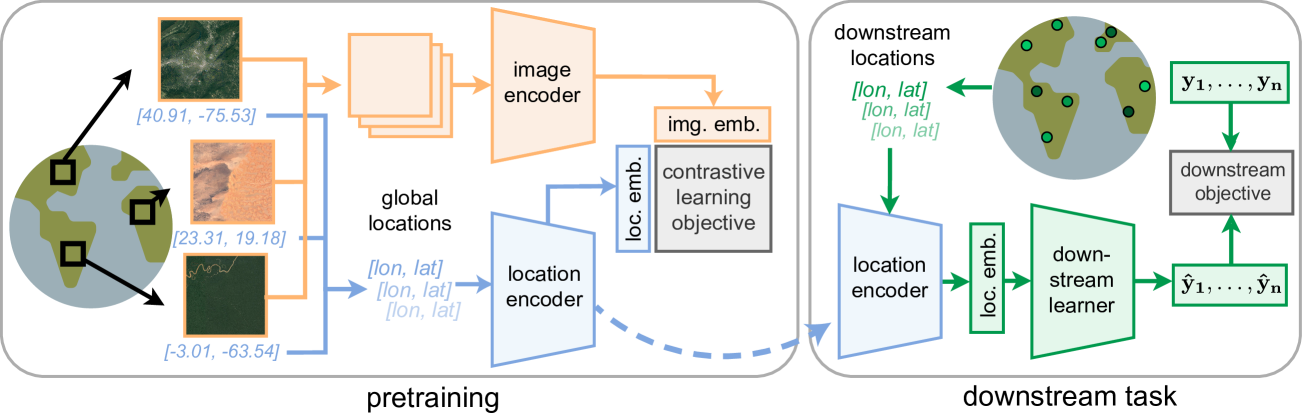
Geographic information is essential for modeling tasks in fields ranging from ecology to epidemiology. However, extracting relevant location characteristics for a given task can be challenging, often requiring expensive data fusion or distillation from massive global imagery datasets. To address this challenge, we introduce Satellite Contrastive Location-Image Pretraining (SatCLIP). This global, general-purpose geographic location encoder learns an implicit representation of locations by matching CNN and ViT inferred visual patterns of openly available satellite imagery with their geographic coordinates. The resulting SatCLIP location encoder efficiently summarizes the characteristics of any given location for convenient use in downstream tasks. In our experiments, we use SatCLIP embeddings to improve prediction performance on nine diverse location-dependent tasks including temperature prediction, animal recognition, and population density estimation. Across tasks, SatCLIP consistently outperforms alternative location encoders and improves geographic generalization by encoding visual similarities of spatially distant environments. These results demonstrate the potential of vision-location models to learn meaningful representations of our planet from the vast, varied, and largely untapped modalities of geospatial data.
Create account to get full access
Overview
- A new approach called SatCLIP that generates global, general-purpose location embeddings using satellite imagery
- The embeddings capture spatial context and can be used for a variety of location-based tasks
- Trained on a large-scale dataset of satellite images and associated geospatial metadata
- Outperforms existing methods on tasks like geolocalization, location-based retrieval, and location clustering
Plain English Explanation
SatCLIP is a new method that can extract useful information from satellite images to help with a variety of location-based tasks. The key idea is to train a machine learning model on a large dataset of satellite images and their associated geographic locations. This allows the model to learn patterns and features in the satellite imagery that are informative about the specific location.
The resulting location embeddings - numerical representations of the spatial context - can then be used for applications like geolocalization, where you want to predict the geographic location of an image, or location-based retrieval, where you want to find images or text corresponding to a particular place. The embeddings can also be useful for clustering locations based on their visual similarity.
Importantly, the SatCLIP embeddings are "general-purpose" - they can be applied to a wide range of location-based tasks, rather than being specialized for a single application. This makes them a powerful and flexible tool for working with geographic data and spatial contexts.
Technical Explanation
The core of the SatCLIP approach is to leverage the CLIP model, a powerful machine learning system that can connect visual and textual information. The researchers train CLIP on a large dataset of satellite imagery and associated geospatial metadata, including latitude, longitude, and other location-specific attributes.
Through this training process, the model learns to extract visual features from the satellite images that are highly correlated with the geographic locations. The resulting location embeddings capture rich spatial context, reflecting factors like terrain, land cover, infrastructure, and more.
The researchers demonstrate that the SatCLIP embeddings outperform existing location representation methods on a variety of benchmarks, including geolocalization, location-based retrieval, and location clustering. This highlights the value of the general-purpose, visually-grounded location representations learned by the model.
Critical Analysis
One potential limitation of the SatCLIP approach is the reliance on a centralized, curated dataset of satellite imagery and geospatial metadata. While this allows for comprehensive training, it may not capture the full diversity of locations and spatial contexts encountered in the real world. Exploring ways to leverage crowdsourced or other decentralized sources of location data could help address this issue.
Additionally, while the researchers demonstrate the versatility of the SatCLIP embeddings, further research is needed to fully understand their limitations and failure modes. For example, it's unclear how the model would perform in regions with significant changes over time, or how robust the embeddings are to factors like cloud cover or low image quality.
Overall, the SatCLIP approach represents an exciting advance in the field of location representation learning. By combining the power of large-scale satellite imagery and the flexibility of the CLIP framework, the researchers have developed a powerful tool for working with geographic data and spatial contexts. As the research continues to evolve, it will be interesting to see how these location embeddings are applied to an even broader range of real-world problems.
Conclusion
The SatCLIP method introduces a novel approach to generating global, general-purpose location embeddings using satellite imagery. These visually-grounded representations capture rich spatial context and can be effectively applied to a variety of location-based tasks, outperforming existing techniques.
While the current implementation has some limitations, the underlying concept of leveraging large-scale satellite data and versatile vision-language models holds great promise for advancing the field of spatial reasoning and geographic information systems. As the research continues, the SatCLIP embeddings could become a valuable tool for developers, researchers, and practitioners working with location-based applications and services.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

ProGEO: Generating Prompts through Image-Text Contrastive Learning for Visual Geo-localization
Chen Mao, Jingqi Hu
0
0
Visual Geo-localization (VG) refers to the process to identify the location described in query images, which is widely applied in robotics field and computer vision tasks, such as autonomous driving, metaverse, augmented reality, and SLAM. In fine-grained images lacking specific text descriptions, directly applying pure visual methods to represent neighborhood features often leads to the model focusing on overly fine-grained features, unable to fully mine the semantic information in the images. Therefore, we propose a two-stage training method to enhance visual performance and use contrastive learning to mine challenging samples. We first leverage the multi-modal description capability of CLIP (Contrastive Language-Image Pretraining) to create a set of learnable text prompts for each geographic image feature to form vague descriptions. Then, by utilizing dynamic text prompts to assist the training of the image encoder, we enable the image encoder to learn better and more generalizable visual features. This strategy of applying text to purely visual tasks addresses the challenge of using multi-modal models for geographic images, which often suffer from a lack of precise descriptions, making them difficult to utilize widely. We validate the effectiveness of the proposed strategy on several large-scale visual geo-localization datasets, and our method achieves competitive results on multiple visual geo-localization datasets. Our code and model are available at https://github.com/Chain-Mao/ProGEO.
6/5/2024
🔍
Sat2Cap: Mapping Fine-Grained Textual Descriptions from Satellite Images
Aayush Dhakal, Adeel Ahmad, Subash Khanal, Srikumar Sastry, Hannah Kerner, Nathan Jacobs
0
0
We propose a weakly supervised approach for creating maps using free-form textual descriptions. We refer to this work of creating textual maps as zero-shot mapping. Prior works have approached mapping tasks by developing models that predict a fixed set of attributes using overhead imagery. However, these models are very restrictive as they can only solve highly specific tasks for which they were trained. Mapping text, on the other hand, allows us to solve a large variety of mapping problems with minimal restrictions. To achieve this, we train a contrastive learning framework called Sat2Cap on a new large-scale dataset with 6.1M pairs of overhead and ground-level images. For a given location and overhead image, our model predicts the expected CLIP embeddings of the ground-level scenery. The predicted CLIP embeddings are then used to learn about the textual space associated with that location. Sat2Cap is also conditioned on date-time information, allowing it to model temporally varying concepts over a location. Our experimental results demonstrate that our models successfully capture ground-level concepts and allow large-scale mapping of fine-grained textual queries. Our approach does not require any text-labeled data, making the training easily scalable. The code, dataset, and models will be made publicly available.
4/15/2024
RemoteCLIP: A Vision Language Foundation Model for Remote Sensing
Fan Liu, Delong Chen, Zhangqingyun Guan, Xiaocong Zhou, Jiale Zhu, Qiaolin Ye, Liyong Fu, Jun Zhou
0
0
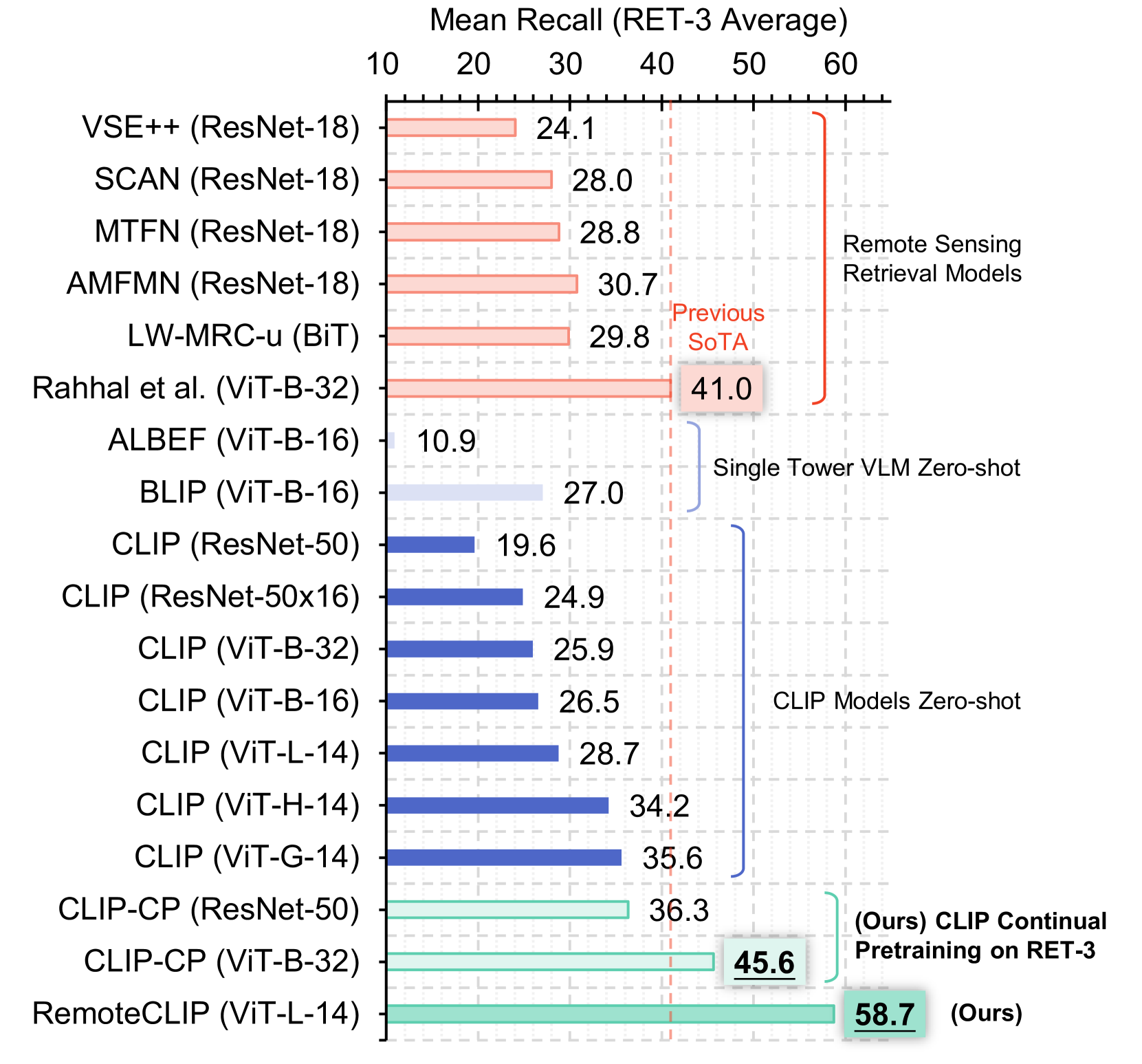
General-purpose foundation models have led to recent breakthroughs in artificial intelligence. In remote sensing, self-supervised learning (SSL) and Masked Image Modeling (MIM) have been adopted to build foundation models. However, these models primarily learn low-level features and require annotated data for fine-tuning. Moreover, they are inapplicable for retrieval and zero-shot applications due to the lack of language understanding. To address these limitations, we propose RemoteCLIP, the first vision-language foundation model for remote sensing that aims to learn robust visual features with rich semantics and aligned text embeddings for seamless downstream application. To address the scarcity of pre-training data, we leverage data scaling which converts heterogeneous annotations into a unified image-caption data format based on Box-to-Caption (B2C) and Mask-to-Box (M2B) conversion. By further incorporating UAV imagery, we produce a 12 $times$ larger pretraining dataset than the combination of all available datasets. RemoteCLIP can be applied to a variety of downstream tasks, including zero-shot image classification, linear probing, $textit{k}$-NN classification, few-shot classification, image-text retrieval, and object counting in remote sensing images. Evaluation on 16 datasets, including a newly introduced RemoteCount benchmark to test the object counting ability, shows that RemoteCLIP consistently outperforms baseline foundation models across different model scales. Impressively, RemoteCLIP beats the state-of-the-art method by 9.14% mean recall on the RSITMD dataset and 8.92% on the RSICD dataset. For zero-shot classification, our RemoteCLIP outperforms the CLIP baseline by up to 6.39% average accuracy on 12 downstream datasets. Project website: https://github.com/ChenDelong1999/RemoteCLIP
4/17/2024
Modeling Caption Diversity in Contrastive Vision-Language Pretraining
Samuel Lavoie, Polina Kirichenko, Mark Ibrahim, Mahmoud Assran, Andrew Gordon Wilson, Aaron Courville, Nicolas Ballas
0
0
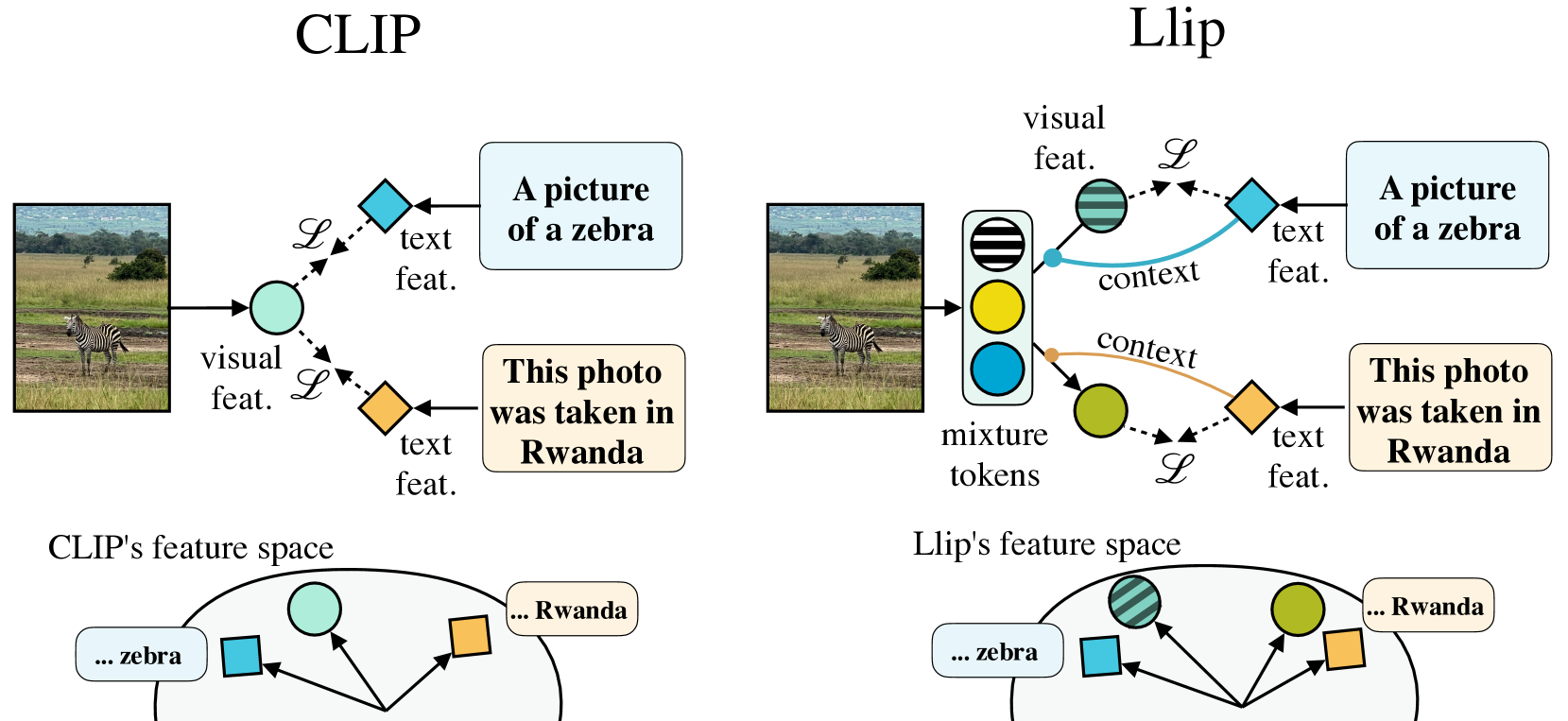
There are a thousand ways to caption an image. Contrastive Language Pretraining (CLIP) on the other hand, works by mapping an image and its caption to a single vector -- limiting how well CLIP-like models can represent the diverse ways to describe an image. In this work, we introduce Llip, Latent Language Image Pretraining, which models the diversity of captions that could match an image. Llip's vision encoder outputs a set of visual features that are mixed into a final representation by conditioning on information derived from the text. We show that Llip outperforms non-contextualized baselines like CLIP and SigLIP on a variety of tasks even with large-scale encoders. Llip improves zero-shot classification by an average of 2.9% zero-shot classification benchmarks with a ViT-G/14 encoder. Specifically, Llip attains a zero-shot top-1 accuracy of 83.5% on ImageNet outperforming a similarly sized CLIP by 1.4%. We also demonstrate improvement on zero-shot retrieval on MS-COCO by 6.0%. We provide a comprehensive analysis of the components introduced by the method and demonstrate that Llip leads to richer visual representations.
5/15/2024