Policy Adaptation via Language Optimization: Decomposing Tasks for Few-Shot Imitation

0

Sign in to get full access
Overview
- This paper proposes a method for few-shot policy adaptation using language optimization.
- The key idea is to decompose complex tasks into simpler subtasks that can be learned more efficiently.
- The method uses language models to guide the policy learning process and enable rapid adaptation to new tasks.
Plain English Explanation
The paper describes a way to help AI systems quickly learn new tasks by breaking them down into smaller, simpler parts. The researchers used language models - AI systems trained on a lot of text data - to help guide the learning process.
The main idea is that complex tasks can be difficult for AI systems to learn from just a few examples. By breaking the task down into smaller, more manageable subtasks, the AI can learn each piece more efficiently. The language model helps the AI system understand the overall goal and how the subtasks fit together.
This allows the AI to adapt to new tasks much faster, using just a small number of examples. Instead of having to learn the entire task from scratch, the AI can focus on learning the key components. The language model provides a "high-level" understanding to help the AI put the pieces together.
The researchers tested this approach on several different tasks, and found that it allowed the AI to perform well even when only given a few demonstrations of the task. This could be useful for real-world applications where we want AI systems to be able to learn new skills quickly, without requiring a large amount of training data.
Technical Explanation
The paper presents a method for few-shot policy adaptation using language optimization. The key idea is to decompose complex tasks into simpler subtasks that can be learned more efficiently.
The method uses large language models to guide the policy learning process and enable rapid adaptation to new tasks. The language model provides a high-level understanding of the task structure and how the subtasks fit together.
The policy is learned via a plan-sequence learning approach, where the AI system first learns to decompose the task into subtasks, and then learns the policies for each subtask. The language model is used to provide task-specific instructions and constraints to help the AI system understand the overall goal.
The researchers evaluate the method on several language-guided manipulation tasks, and show that it allows for effective few-shot adaptation to new tasks.
Critical Analysis
The paper presents a novel and promising approach for enabling few-shot policy adaptation. The key strength is the use of language models to provide high-level task understanding and guide the decomposition of complex tasks into simpler subtasks.
One potential limitation is that the method may be sensitive to the quality and coverage of the language model. If the language model has biases or gaps in its knowledge, this could lead to suboptimal task decompositions or policy learning. Further research is needed to understand the robustness of the approach to different language models and task domains.
Additionally, the paper does not deeply explore the cognitive plausibility of the task decomposition process. It would be interesting to see how this relates to how humans learn and adapt to new tasks through language and high-level reasoning.
Overall, the paper makes an important contribution to the field of few-shot learning and policy adaptation, and the proposed approach holds promise for enabling more flexible and efficient skill acquisition in AI systems.
Conclusion
This paper presents a method for few-shot policy adaptation that uses language optimization to decompose complex tasks into simpler subtasks. By leveraging large language models to provide high-level task understanding, the approach enables AI systems to learn new skills rapidly, using just a small number of examples.
The key innovation is the integration of language-guided task decomposition and plan-sequence learning, which allows the AI to focus on learning the critical components of a task rather than having to learn the entire task from scratch. This could have significant implications for real-world applications where we want AI systems to be able to quickly adapt to new situations and requirements.
While the paper highlights the potential of this approach, further research is needed to fully understand its strengths, limitations, and cognitive plausibility. Nonetheless, this work represents an important step forward in the quest to develop AI systems that can learn and adapt with human-like flexibility.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Policy Adaptation via Language Optimization: Decomposing Tasks for Few-Shot Imitation
Vivek Myers, Bill Chunyuan Zheng, Oier Mees, Sergey Levine, Kuan Fang
Learned language-conditioned robot policies often struggle to effectively adapt to new real-world tasks even when pre-trained across a diverse set of instructions. We propose a novel approach for few-shot adaptation to unseen tasks that exploits the semantic understanding of task decomposition provided by vision-language models (VLMs). Our method, Policy Adaptation via Language Optimization (PALO), combines a handful of demonstrations of a task with proposed language decompositions sampled from a VLM to quickly enable rapid nonparametric adaptation, avoiding the need for a larger fine-tuning dataset. We evaluate PALO on extensive real-world experiments consisting of challenging unseen, long-horizon robot manipulation tasks. We find that PALO is able of consistently complete long-horizon, multi-tier tasks in the real world, outperforming state of the art pre-trained generalist policies, and methods that have access to the same demonstrations.
Read more8/30/2024
💬
0
Large Language Models as Generalizable Policies for Embodied Tasks
Andrew Szot, Max Schwarzer, Harsh Agrawal, Bogdan Mazoure, Walter Talbott, Katherine Metcalf, Natalie Mackraz, Devon Hjelm, Alexander Toshev
We show that large language models (LLMs) can be adapted to be generalizable policies for embodied visual tasks. Our approach, called Large LAnguage model Reinforcement Learning Policy (LLaRP), adapts a pre-trained frozen LLM to take as input text instructions and visual egocentric observations and output actions directly in the environment. Using reinforcement learning, we train LLaRP to see and act solely through environmental interactions. We show that LLaRP is robust to complex paraphrasings of task instructions and can generalize to new tasks that require novel optimal behavior. In particular, on 1,000 unseen tasks it achieves 42% success rate, 1.7x the success rate of other common learned baselines or zero-shot applications of LLMs. Finally, to aid the community in studying language conditioned, massively multi-task, embodied AI problems we release a novel benchmark, Language Rearrangement, consisting of 150,000 training and 1,000 testing tasks for language-conditioned rearrangement. Video examples of LLaRP in unseen Language Rearrangement instructions are at https://llm-rl.github.io.
Read more4/17/2024
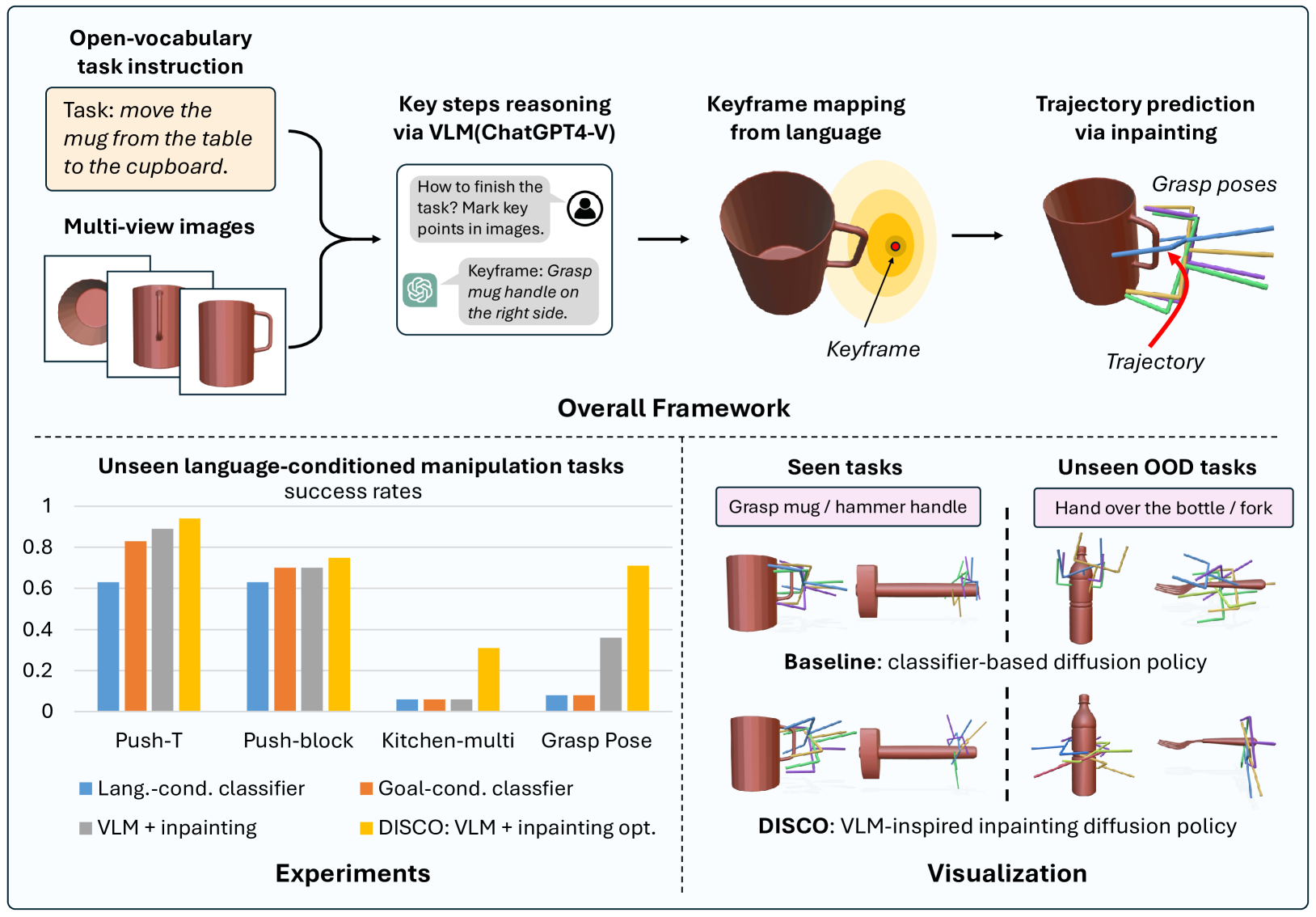
0
Language-Guided Manipulation with Diffusion Policies and Constrained Inpainting
Ce Hao, Kelvin Lin, Siyuan Luo, Harold Soh
Diffusion policies have demonstrated robust performance in generative modeling, prompting their application in robotic manipulation controlled via language descriptions. In this paper, we introduce a zero-shot, open-vocabulary diffusion policy method for robot manipulation. Using Vision-Language Models (VLMs), our method transforms linguistic task descriptions into actionable keyframes in 3D space. These keyframes serve to guide the diffusion process via inpainting. However, naively enforcing the diffusion process to adhere to the generated keyframes is problematic: the keyframes from the VLMs may be incorrect and lead to out-of-distribution (OOD) action sequences where the diffusion model performs poorly. To address these challenges, we develop an inpainting optimization strategy that balances adherence to the keyframes v.s. the training data distribution. Experimental evaluations demonstrate that our approach surpasses the performance of traditional fine-tuned language-conditioned methods in both simulated and real-world settings.
Read more6/17/2024

0
Low-Rank Few-Shot Adaptation of Vision-Language Models
Maxime Zanella, Ismail Ben Ayed
Recent progress in the few-shot adaptation of Vision-Language Models (VLMs) has further pushed their generalization capabilities, at the expense of just a few labeled samples within the target downstream task. However, this promising, already quite abundant few-shot literature has focused principally on prompt learning and, to a lesser extent, on adapters, overlooking the recent advances in Parameter-Efficient Fine-Tuning (PEFT). Furthermore, existing few-shot learning methods for VLMs often rely on heavy training procedures and/or carefully chosen, task-specific hyper-parameters, which might impede their applicability. In response, we introduce Low-Rank Adaptation (LoRA) in few-shot learning for VLMs, and show its potential on 11 datasets, in comparison to current state-of-the-art prompt- and adapter-based approaches. Surprisingly, our simple CLIP-LoRA method exhibits substantial improvements, while reducing the training times and keeping the same hyper-parameters in all the target tasks, i.e., across all the datasets and numbers of shots. Certainly, our surprising results do not dismiss the potential of prompt-learning and adapter-based research. However, we believe that our strong baseline could be used to evaluate progress in these emergent subjects in few-shot VLMs.
Read more6/4/2024