PowerInfer-2: Fast Large Language Model Inference on a Smartphone
2406.06282
43
0

Abstract
This paper introduces PowerInfer-2, a framework designed for high-speed inference of Large Language Models (LLMs) on smartphones, particularly effective for models whose sizes exceed the device's memory capacity. The key insight of PowerInfer-2 is to utilize the heterogeneous computation, memory, and I/O resources in smartphones by decomposing traditional matrix computations into fine-grained neuron cluster computations. Specifically, PowerInfer-2 features a polymorphic neuron engine that adapts computational strategies for various stages of LLM inference. Additionally, it introduces segmented neuron caching and fine-grained neuron-cluster-level pipelining, which effectively minimize and conceal the overhead caused by I/O operations. The implementation and evaluation of PowerInfer-2 demonstrate its capability to support a wide array of LLM models on two smartphones, achieving up to a 29.2x speed increase compared with state-of-the-art frameworks. Notably, PowerInfer-2 is the first system to serve the TurboSparse-Mixtral-47B model with a generation rate of 11.68 tokens per second on a smartphone. For models that fit entirely within the memory, PowerInfer-2 can achieve approximately a 40% reduction in memory usage while maintaining inference speeds comparable to llama.cpp and MLC-LLM. For more details, including a demonstration video, please visit the project site at www.powerinfer.ai/v2.
Create account to get full access
Overview
- Introduces a new approach called PowerInfer-2 for fast inference of large language models on smartphones
- Focuses on improving the efficiency and performance of running large language models on mobile devices
- Explores techniques to reduce the computational and memory requirements of inference, enabling real-time applications on smartphones
Plain English Explanation
PowerInfer-2 is a new method that allows large language models to run efficiently on smartphones. Large language models are powerful AI systems that can understand and generate human-like text, but they typically require a lot of computing power and memory to run. This can make it challenging to use them on mobile devices like phones, which have more limited resources.
The researchers behind PowerInfer-2 have developed techniques to reduce the computational and memory demands of running these large language models. This allows them to be used in real-time applications on smartphones, opening up new possibilities for mobile AI assistants, text generation, and other language-based tasks.
Some of the key ideas behind PowerInfer-2 include tokenwise influential training data retrieval to prioritize the most important parts of the model, and efficient intercept support to speed up the inference process. The researchers also explore techniques to enhance inference efficiency and build on prior work in transformer-based model compression and efficient inference of large language models.
Technical Explanation
The researchers introduce PowerInfer-2, a new approach for fast inference of large language models on smartphones. They focus on reducing the computational and memory requirements of running these models, which is crucial for enabling real-time applications on mobile devices.
One key technique used in PowerInfer-2 is tokenwise influential training data retrieval. This method identifies the most important parts of the language model and prioritizes them during inference, allowing for more efficient use of the limited resources available on smartphones.
The researchers also employ efficient intercept support, which accelerates the inference process by optimizing the way the model computes the final output. This builds on previous work in enhancing inference efficiency of large language models.
Additionally, PowerInfer-2 incorporates transformer-based model compression techniques to further reduce the memory and compute requirements, drawing on the broader research landscape of efficient inference for large language models.
Critical Analysis
The paper provides a comprehensive overview of the techniques used in PowerInfer-2 and presents experimental results demonstrating the method's efficiency and performance on smartphones. However, the authors acknowledge that there are still some limitations to address.
For instance, the researchers note that the current implementation of PowerInfer-2 may not be suitable for all types of language models or tasks. They suggest that further research is needed to explore the generalizability of the approach and its applicability to a wider range of models and use cases.
Additionally, the authors highlight the importance of considering the trade-offs between inference speed, model accuracy, and other relevant metrics when deploying large language models on mobile devices. They encourage readers to think critically about these factors and their potential implications for real-world applications.
Conclusion
PowerInfer-2 represents a significant advancement in the field of efficient inference for large language models on mobile devices. By incorporating techniques like tokenwise influential training data retrieval, efficient intercept support, and transformer-based model compression, the researchers have demonstrated a path forward for running powerful AI systems on smartphones in real-time.
The potential impact of this work is far-reaching, as it could enable a wide range of innovative applications that leverage the capabilities of large language models while overcoming the resource constraints of mobile platforms. As the field of efficient AI inference continues to evolve, PowerInfer-2 serves as an important contribution, highlighting the importance of optimizing model performance for deployment on resource-constrained devices.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Transformer-Lite: High-efficiency Deployment of Large Language Models on Mobile Phone GPUs
Luchang Li, Sheng Qian, Jie Lu, Lunxi Yuan, Rui Wang, Qin Xie
0
0
The Large Language Model (LLM) is widely employed for tasks such as intelligent assistants, text summarization, translation, and multi-modality on mobile phones. However, the current methods for on-device LLM deployment maintain slow inference speed, which causes poor user experience. To facilitate high-efficiency LLM deployment on device GPUs, we propose four optimization techniques: (a) a symbolic expression-based approach to support dynamic shape model inference; (b) operator optimizations and execution priority setting to enhance inference speed and reduce phone lagging; (c) an FP4 quantization method termed M0E4 to reduce dequantization overhead; (d) a sub-tensor-based technique to eliminate the need for copying KV cache after LLM inference. Furthermore, we implement these methods in our mobile inference engine, Transformer-Lite, which is compatible with both Qualcomm and MTK processors. We evaluated Transformer-Lite's performance using LLMs with varied architectures and parameters ranging from 2B to 14B. Specifically, we achieved prefill and decoding speeds of 121 token/s and 14 token/s for ChatGLM2 6B, and 330 token/s and 30 token/s for smaller Gemma 2B, respectively. Compared with CPU-based FastLLM and GPU-based MLC-LLM, our engine attains over 10x speedup for the prefill speed and 2~3x speedup for the decoding speed.
5/22/2024
LiveMind: Low-latency Large Language Models with Simultaneous Inference
Chuangtao Chen, Grace Li Zhang, Xunzhao Yin, Cheng Zhuo, Ulf Schlichtmann, Bing Li
0
0
In this paper, we introduce a novel low-latency inference framework for large language models (LLMs) inference which enables LLMs to perform inferences with incomplete prompts. By reallocating computational processes to prompt input phase, we achieve a substantial reduction in latency, thereby significantly enhancing the interactive experience for users of LLMs. The framework adeptly manages the visibility of the streaming prompt to the model, allowing it to infer from incomplete prompts or await additional prompts. Compared with traditional inference methods that utilize complete prompts, our approach demonstrates an average reduction of 59% in response latency on the MMLU-Pro dataset, while maintaining comparable accuracy. Additionally, our framework facilitates collaborative inference and output across different models. By employing an LLM for inference and a small language model (SLM) for output, we achieve an average 68% reduction in response latency, alongside a 5.5% improvement in accuracy on the MMLU-Pro dataset compared with the SLM baseline. For long prompts exceeding 20 sentences, the response latency can be reduced by up to 93%.
6/21/2024
🤯
Inference Acceleration for Large Language Models on CPUs
Ditto PS, Jithin VG, Adarsh MS
0
0
In recent years, large language models have demonstrated remarkable performance across various natural language processing (NLP) tasks. However, deploying these models for real-world applications often requires efficient inference solutions to handle the computational demands. In this paper, we explore the utilization of CPUs for accelerating the inference of large language models. Specifically, we introduce a parallelized approach to enhance throughput by 1) Exploiting the parallel processing capabilities of modern CPU architectures, 2) Batching the inference request. Our evaluation shows the accelerated inference engine gives an 18-22x improvement in the generated token per sec. The improvement is more with longer sequence and larger models. In addition to this, we can also run multiple workers in the same machine with NUMA node isolation to further improvement in tokens/s. Table 2, we have received 4x additional improvement with 4 workers. This would also make Gen-AI based products and companies environment friendly, our estimates shows that CPU usage for Inference could reduce the power consumption of LLMs by 48.9% while providing production ready throughput and latency.
6/13/2024
InferCept: Efficient Intercept Support for Augmented Large Language Model Inference
Reyna Abhyankar, Zijian He, Vikranth Srivatsa, Hao Zhang, Yiying Zhang
0
0
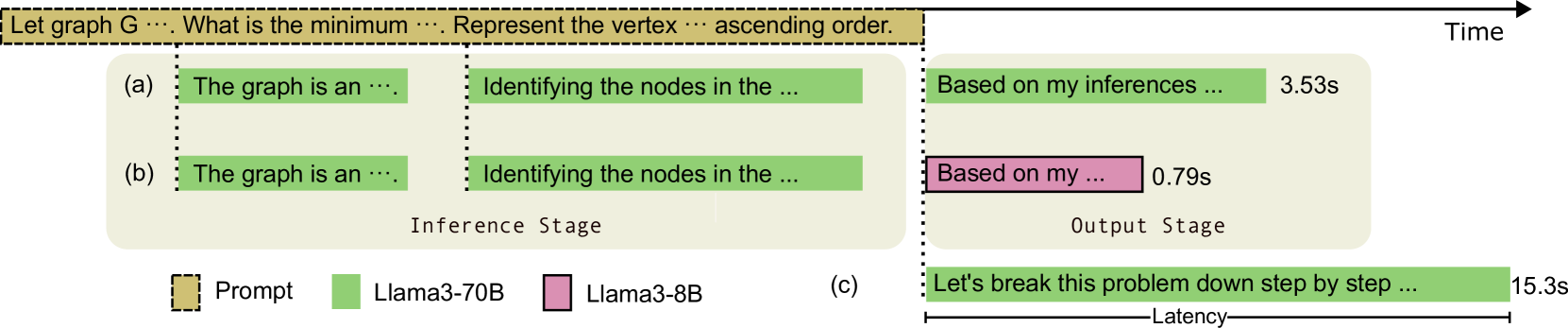
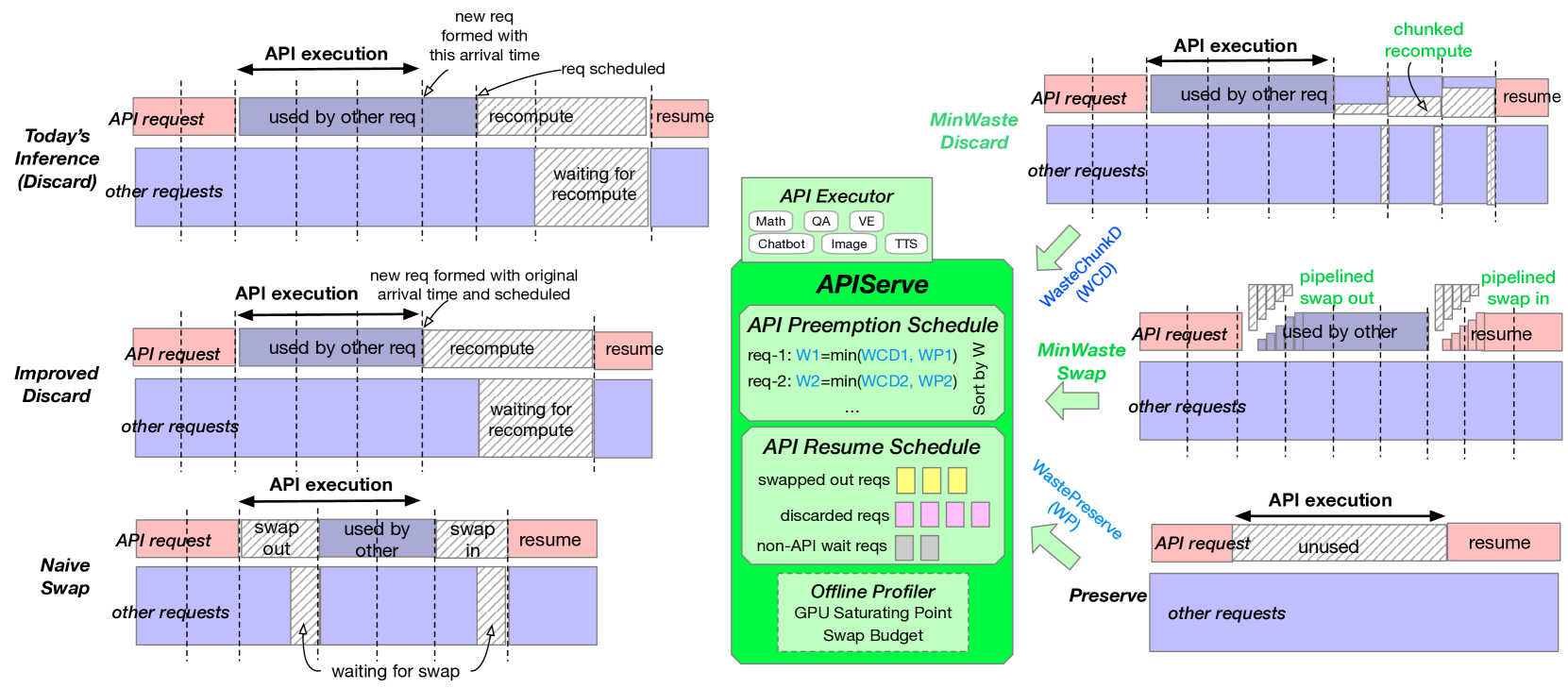
Large language models are increasingly integrated with external environments, tools, and agents like ChatGPT plugins to extend their capability beyond language-centric tasks. However, today's LLM inference systems are designed for standalone LLMs. They treat each external interaction as the end of LLM generation and form a new request when the interaction finishes, causing unnecessary recomputation of already computed contexts, which accounts for 37-40% of total model forwarding time. This paper presents InferCept, the first LLM inference framework targeting augmented LLMs and supporting the efficient interception of LLM generation. InferCept minimizes the GPU resource waste caused by LLM interceptions and dedicates saved memory for serving more requests. InferCept improves the overall serving throughput by 1.6x-2x and completes 2x more requests per second compared to the state-of-the-art LLM inference systems.
5/31/2024