Prioritized Semantic Learning for Zero-shot Instance Navigation

0

Sign in to get full access
Overview
- This paper introduces a novel approach called Prioritized Semantic Learning (PSL) for zero-shot instance navigation, where the goal is to navigate to a specific object instance in a real-world environment without any prior experience with that instance.
- PSL leverages a hierarchical semantic representation of objects, allowing the model to generalize from known object categories to novel instances.
- The authors demonstrate the effectiveness of PSL on challenging real-world navigation tasks, outperforming existing methods for zero-shot object-goal navigation.
Plain English Explanation
The key challenge in zero-shot instance navigation is being able to navigate to a specific object, like a particular chair or table, without having seen that exact object before. Typical navigation models struggle with this because they rely on memorizing the visual appearance of known objects.
Prioritized Semantic Learning for Zero-shot Instance Navigation takes a different approach. Instead of trying to memorize object appearances, it builds a hierarchical understanding of object semantics - the underlying properties and relationships that define different object categories.
This allows the model to generalize its knowledge and navigate to novel object instances that share semantic similarities with objects it has seen before. For example, if the model has learned about chairs in general, it can apply that knowledge to navigate to a new chair it hasn't encountered.
The key innovation is the "prioritized" aspect - the model focuses its learning on the most relevant semantic properties for the navigation task at hand. This helps it quickly zero-in on the details that matter most for finding the target object.
The authors show this approach outperforms existing methods on challenging real-world navigation benchmarks, where the agent has to find specific object instances in complex environments. This suggests Prioritized Semantic Learning could be a promising direction for building more flexible, generalizable navigation capabilities.
Technical Explanation
Prioritized Semantic Learning for Zero-shot Instance Navigation introduces a novel architecture and training approach for zero-shot object-goal navigation. The core idea is to learn a hierarchical semantic representation of objects that can generalize to novel instances.
The model consists of several key components:
- A CNN-based visual encoder that extracts visual features from the environment.
- A language encoder that encodes natural language descriptions of the target object.
- A semantic concept learner that builds a hierarchical understanding of object semantics, modeling both general categories and instance-specific properties.
- A navigation policy that uses the learned semantic representations to plan a path to the target object.
The key innovation is the "prioritized" aspect of the semantic learning. Rather than learning a generic semantic model, the system focuses its learning on the most relevant semantic properties for the current navigation task. This allows it to quickly zero-in on the details that matter most for finding the target object.
The authors evaluate their approach on challenging real-world Object-Goal Navigation and Zero-Shot Instance Navigation benchmarks. Their results show significant improvements over prior methods, particularly in the zero-shot setting where the target object instance is novel.
Critical Analysis
The authors present a compelling approach to the challenging problem of zero-shot instance navigation. By learning a hierarchical semantic representation, the model is able to generalize its knowledge and navigate to novel object instances.
One potential limitation is that the approach relies on having detailed natural language descriptions of the target objects. In real-world scenarios, these descriptions may not always be available or easily generated. An interesting direction for future work could be to explore learning semantic representations directly from visual data, without requiring language input.
Additionally, the experiments are conducted in simulated environments, which may not fully capture the complexity of real-world navigation. Further evaluation on physical robot platforms would help validate the approach's practicality and robustness.
Aligning Knowledge Graph and Visual Perception for Object-Goal Navigation presents an alternative approach that integrates structured knowledge about objects with visual perception. Comparing the relative strengths and limitations of these different semantic reasoning approaches could yield valuable insights.
Overall, the Prioritized Semantic Learning framework represents an important step towards more flexible, generalizable navigation capabilities. Further research in this direction could have significant implications for applications like assistive robotics and autonomous vehicles.
Conclusion
Prioritized Semantic Learning for Zero-shot Instance Navigation introduces a novel approach for zero-shot object-goal navigation that learns a hierarchical semantic representation of objects. By focusing its learning on the most relevant semantic properties, the model is able to generalize its knowledge and navigate to novel object instances.
The authors demonstrate the effectiveness of this approach on challenging real-world benchmarks, outperforming previous methods. This suggests Prioritized Semantic Learning could be a promising direction for building more flexible and generalizable navigation capabilities, with potential applications in areas like assistive robotics and autonomous vehicles.
While the approach shows promise, further research is needed to address potential limitations, such as the reliance on natural language descriptions and the use of simulated environments. Exploring alternative ways of learning semantic representations and validating the approach on physical robot platforms could help unlock the full potential of this innovative framework.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Prioritized Semantic Learning for Zero-shot Instance Navigation
Xinyu Sun, Lizhao Liu, Hongyan Zhi, Ronghe Qiu, Junwei Liang
We study zero-shot instance navigation, in which the agent navigates to a specific object without using object annotations for training. Previous object navigation approaches apply the image-goal navigation (ImageNav) task (go to the location of an image) for pretraining, and transfer the agent to achieve object goals using a vision-language model. However, these approaches lead to issues of semantic neglect, where the model fails to learn meaningful semantic alignments. In this paper, we propose a Prioritized Semantic Learning (PSL) method to improve the semantic understanding ability of navigation agents. Specifically, a semantic-enhanced PSL agent is proposed and a prioritized semantic training strategy is introduced to select goal images that exhibit clear semantic supervision and relax the reward function from strict exact view matching. At inference time, a semantic expansion inference scheme is designed to preserve the same granularity level of the goal semantic as training. Furthermore, for the popular HM3D environment, we present an Instance Navigation (InstanceNav) task that requires going to a specific object instance with detailed descriptions, as opposed to the Object Navigation (ObjectNav) task where the goal is defined merely by the object category. Our PSL agent outperforms the previous state-of-the-art by 66% on zero-shot ObjectNav in terms of success rate and is also superior on the new InstanceNav task. Code will be released at https://github.com/XinyuSun/PSL-InstanceNav.
Read more7/18/2024

0
Object Instance Retrieval in Assistive Robotics: Leveraging Fine-Tuned SimSiam with Multi-View Images Based on 3D Semantic Map
Taichi Sakaguchi, Akira Taniguchi, Yoshinobu Hagiwara, Lotfi El Hafi, Shoichi Hasegawa, Tadahiro Taniguchi
Robots that assist humans in their daily lives should be able to locate specific instances of objects in an environment that match a user's desired objects. This task is known as instance-specific image goal navigation (InstanceImageNav), which requires a model that can distinguish different instances of an object within the same class. A significant challenge in robotics is that when a robot observes the same object from various 3D viewpoints, its appearance may differ significantly, making it difficult to recognize and locate accurately. In this paper, we introduce a method called SimView, which leverages multi-view images based on a 3D semantic map of an environment and self-supervised learning using SimSiam to train an instance-identification model on-site. The effectiveness of our approach was validated using a photorealistic simulator, Habitat Matterport 3D, created by scanning actual home environments. Our results demonstrate a 1.7-fold improvement in task accuracy compared with contrastive language-image pre-training (CLIP), a pre-trained multimodal contrastive learning method for object searching. This improvement highlights the benefits of our proposed fine-tuning method in enhancing the performance of assistive robots in InstanceImageNav tasks. The project website is https://emergentsystemlabstudent.github.io/MultiViewRetrieve/.
Read more9/16/2024
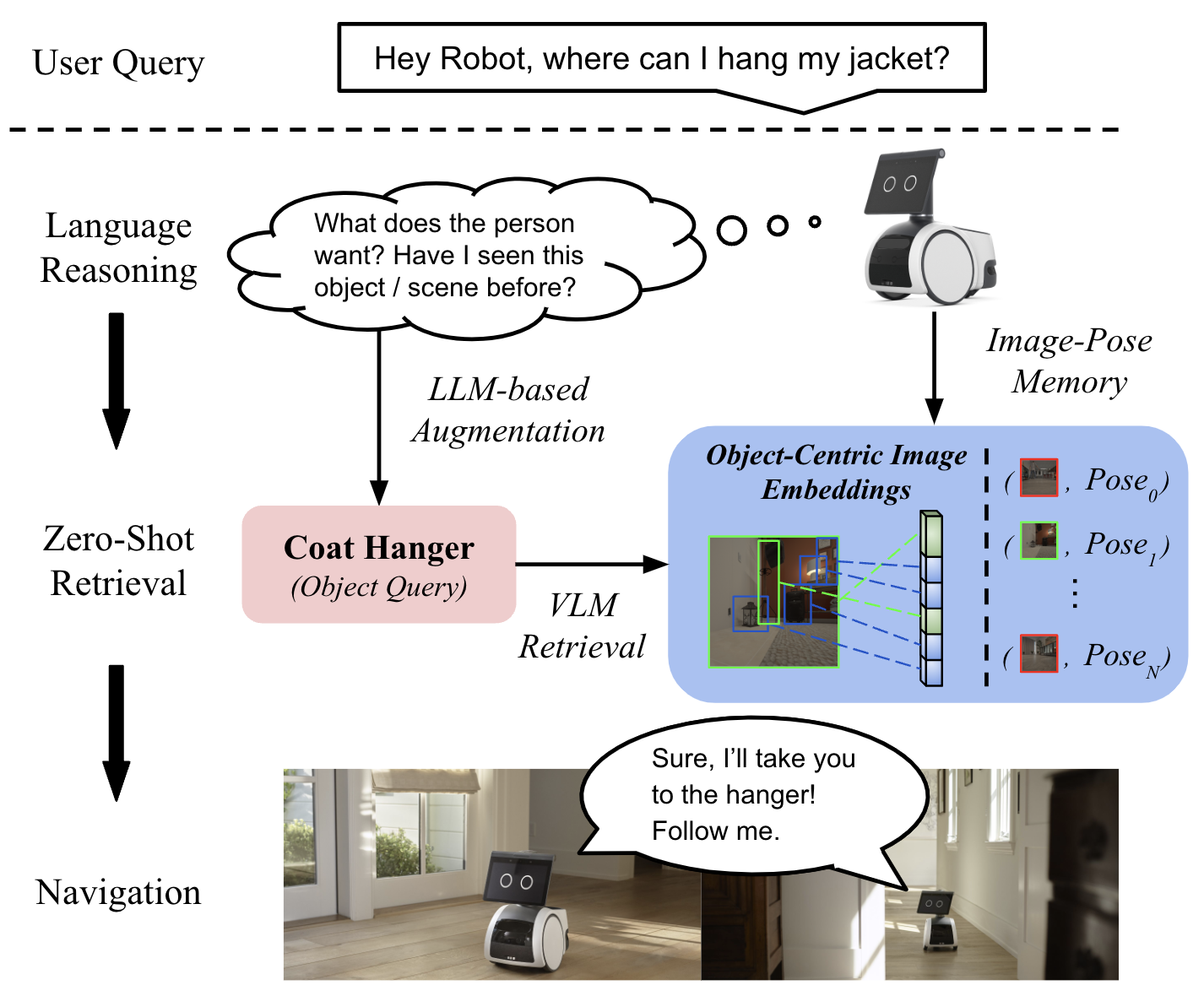
0
LOC-ZSON: Language-driven Object-Centric Zero-Shot Object Retrieval and Navigation
Tianrui Guan, Yurou Yang, Harry Cheng, Muyuan Lin, Richard Kim, Rajasimman Madhivanan, Arnie Sen, Dinesh Manocha
In this paper, we present LOC-ZSON, a novel Language-driven Object-Centric image representation for object navigation task within complex scenes. We propose an object-centric image representation and corresponding losses for visual-language model (VLM) fine-tuning, which can handle complex object-level queries. In addition, we design a novel LLM-based augmentation and prompt templates for stability during training and zero-shot inference. We implement our method on Astro robot and deploy it in both simulated and real-world environments for zero-shot object navigation. We show that our proposed method can achieve an improvement of 1.38 - 13.38% in terms of text-to-image recall on different benchmark settings for the retrieval task. For object navigation, we show the benefit of our approach in simulation and real world, showing 5% and 16.67% improvement in terms of navigation success rate, respectively.
Read more5/10/2024

0
Real-world Instance-specific Image Goal Navigation for Service Robots: Bridging the Domain Gap with Contrastive Learning
Taichi Sakaguchi, Akira Taniguchi, Yoshinobu Hagiwara, Lotfi El Hafi, Shoichi Hasegawa, Tadahiro Taniguchi
Improving instance-specific image goal navigation (InstanceImageNav), which locates the identical object in a real-world environment from a query image, is essential for robotic systems to assist users in finding desired objects. The challenge lies in the domain gap between low-quality images observed by the moving robot, characterized by motion blur and low-resolution, and high-quality query images provided by the user. Such domain gaps could significantly reduce the task success rate but have not been the focus of previous work. To address this, we propose a novel method called Few-shot Cross-quality Instance-aware Adaptation (CrossIA), which employs contrastive learning with an instance classifier to align features between massive low- and few high-quality images. This approach effectively reduces the domain gap by bringing the latent representations of cross-quality images closer on an instance basis. Additionally, the system integrates an object image collection with a pre-trained deblurring model to enhance the observed image quality. Our method fine-tunes the SimSiam model, pre-trained on ImageNet, using CrossIA. We evaluated our method's effectiveness through an InstanceImageNav task with 20 different types of instances, where the robot identifies the same instance in a real-world environment as a high-quality query image. Our experiments showed that our method improves the task success rate by up to three times compared to the baseline, a conventional approach based on SuperGlue. These findings highlight the potential of leveraging contrastive learning and image enhancement techniques to bridge the domain gap and improve object localization in robotic applications. The project website is https://emergentsystemlabstudent.github.io/DomainBridgingNav/.
Read more4/16/2024