Progressive Distillation Based on Masked Generation Feature Method for Knowledge Graph Completion

0

Sign in to get full access
Overview
- This paper introduces a new method called "Progressive Distillation Based on Masked Generation Feature" for improving knowledge graph completion.
- Knowledge graph completion is the task of predicting missing relationships in a knowledge graph, which is a structured database of facts.
- The proposed method uses a progressive distillation approach, where a series of student models are trained to mimic the behavior of a more complex teacher model.
- The student models are trained to predict the missing relationships in the knowledge graph by leveraging masked generation features, which capture contextual information.
Plain English Explanation
Knowledge graphs are like databases that store facts about the world, represented as connections between different concepts. However, these knowledge graphs often have missing information - there are relationships between concepts that are not recorded. Exploring Graph-Based Knowledge Multi-Level Feature and Multi-Task Multi-Scale Contrastive Knowledge Distillation have explored ways to infer these missing connections.
The researchers in this paper propose a new method called "Progressive Distillation Based on Masked Generation Feature" to tackle this knowledge graph completion problem. The key idea is to train a series of simpler "student" models to mimic the behavior of a more complex "teacher" model. These student models are trained to predict the missing relationships by looking at the surrounding context, using a technique called "masked generation features".
The progressive distillation approach means that the student models start simple and gradually become more complex, learning from the previous student models. This allows the models to learn the task of knowledge graph completion in a step-by-step manner, rather than trying to learn it all at once. Robust Knowledge Distillation Based on Feature Variance Against and PLAD: Preference-based Large Language Model Distillation have explored similar knowledge distillation approaches.
By using this progressive distillation method and the masked generation features, the researchers were able to improve the performance of knowledge graph completion compared to previous methods. This could be useful for applications that rely on knowledge graphs, such as question-answering systems or recommendation engines.
Technical Explanation
The key components of the proposed method are:
-
Progressive Distillation: The researchers train a series of student models that progressively become more complex. Each student model is trained to mimic the behavior of the previous student model, as well as the original teacher model. This allows the student models to learn the task of knowledge graph completion in a step-by-step manner.
-
Masked Generation Features: The student models are trained to predict the missing relationships in the knowledge graph by looking at the surrounding context. Specifically, the model is given a partial input (with some relationships masked) and is tasked with generating the missing information.
-
Knowledge Graph Completion: The student models are evaluated on their ability to accurately predict the missing relationships in the knowledge graph. The researchers compare the performance of their method to other state-of-the-art approaches.
The researchers conducted experiments on several benchmark knowledge graph datasets and found that their Progressive Distillation Based on Masked Generation Feature method outperformed other methods in terms of knowledge graph completion accuracy. They attribute this to the effectiveness of the progressive distillation approach and the use of masked generation features, which allow the models to better capture the contextual information in the knowledge graph.
Critical Analysis
The researchers acknowledge several limitations of their work:
-
Computational Complexity: Training the series of student models can be computationally expensive, as each model needs to be trained separately.
-
Hyperparameter Tuning: The performance of the method is sensitive to the choice of hyperparameters, such as the number of student models and the degree of masking used in the generation features.
-
Generalization: The researchers only evaluated their method on a few benchmark datasets, and it's unclear how well it would generalize to other types of knowledge graphs or real-world applications.
Additionally, the paper does not address the potential privacy concerns with knowledge graph completion. Differentially Private Knowledge Distillation via Synthetic Text has explored methods for preserving privacy in knowledge distillation.
Overall, the proposed method represents an interesting advance in knowledge graph completion, but further research is needed to address the computational and generalization challenges, as well as the potential privacy implications.
Conclusion
This paper introduces a new method called "Progressive Distillation Based on Masked Generation Feature" for improving knowledge graph completion. The key ideas are to use a progressive distillation approach, where simpler student models are trained to mimic a more complex teacher model, and to leverage masked generation features to capture contextual information.
The researchers demonstrated that their method outperforms other state-of-the-art approaches on benchmark knowledge graph datasets. This could have important implications for applications that rely on knowledge graphs, such as question-answering systems and recommendation engines.
However, the method also has some limitations, such as computational complexity and the need for careful hyperparameter tuning. Further research is needed to address these challenges and explore the broader applicability of the approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Progressive Distillation Based on Masked Generation Feature Method for Knowledge Graph Completion
Cunhang Fan, Yujie Chen, Jun Xue, Yonghui Kong, Jianhua Tao, Zhao Lv
In recent years, knowledge graph completion (KGC) models based on pre-trained language model (PLM) have shown promising results. However, the large number of parameters and high computational cost of PLM models pose challenges for their application in downstream tasks. This paper proposes a progressive distillation method based on masked generation features for KGC task, aiming to significantly reduce the complexity of pre-trained models. Specifically, we perform pre-distillation on PLM to obtain high-quality teacher models, and compress the PLM network to obtain multi-grade student models. However, traditional feature distillation suffers from the limitation of having a single representation of information in teacher models. To solve this problem, we propose masked generation of teacher-student features, which contain richer representation information. Furthermore, there is a significant gap in representation ability between teacher and student. Therefore, we design a progressive distillation method to distill student models at each grade level, enabling efficient knowledge transfer from teachers to students. The experimental results demonstrate that the model in the pre-distillation stage surpasses the existing state-of-the-art methods. Furthermore, in the progressive distillation stage, the model significantly reduces the model parameters while maintaining a certain level of performance. Specifically, the model parameters of the lower-grade student model are reduced by 56.7% compared to the baseline.
Read more6/11/2024
0
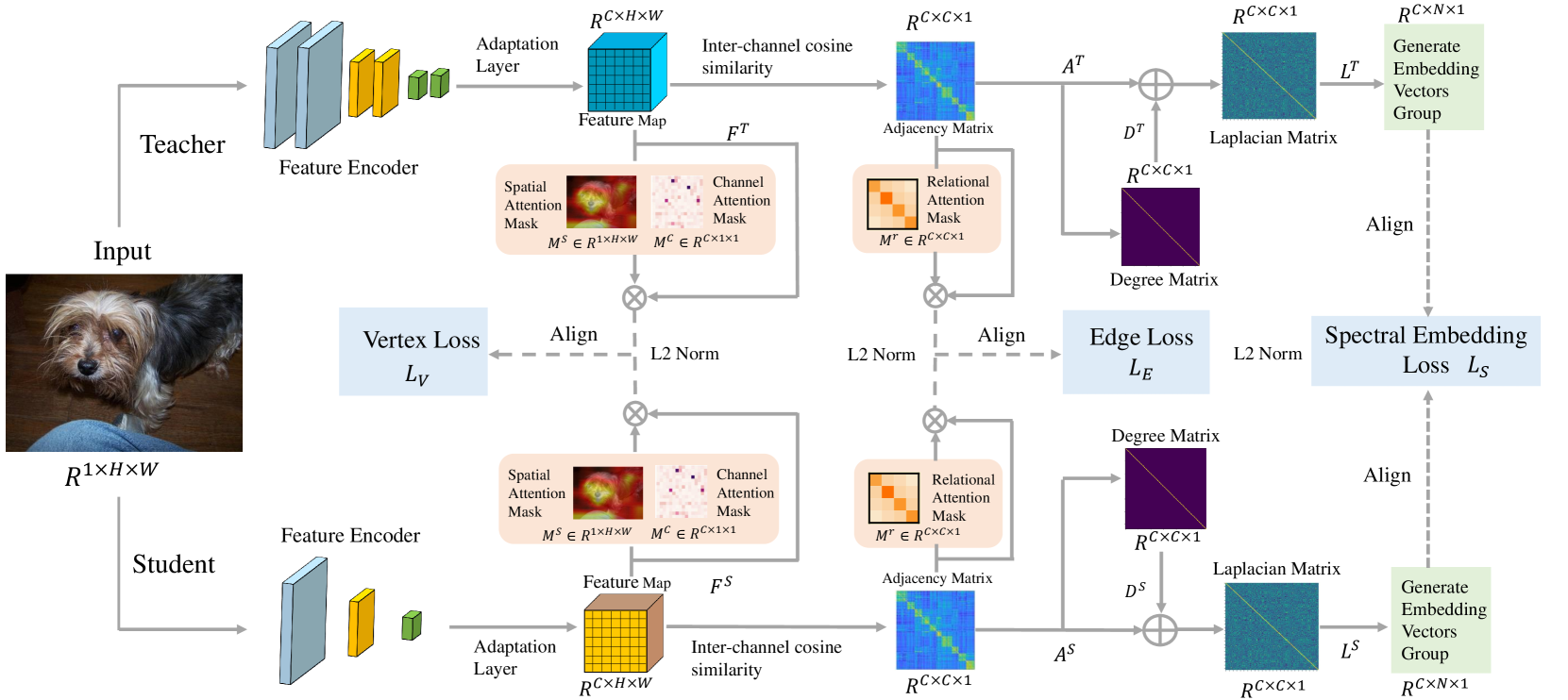
Exploring Graph-based Knowledge: Multi-Level Feature Distillation via Channels Relational Graph
Zhiwei Wang, Jun Huang, Longhua Ma, Chengyu Wu, Hongyu Ma
In visual tasks, large teacher models capture essential features and deep information, enhancing performance. However, distilling this information into smaller student models often leads to performance loss due to structural differences and capacity limitations. To tackle this, we propose a distillation framework based on graph knowledge, including a multi-level feature alignment strategy and an attention-guided mechanism to provide a targeted learning trajectory for the student model. We emphasize spectral embedding (SE) as a key technique in our distillation process, which merges the student's feature space with the relational knowledge and structural complexities similar to the teacher network. This method captures the teacher's understanding in a graph-based representation, enabling the student model to more accurately mimic the complex structural dependencies present in the teacher model. Compared to methods that focus only on specific distillation areas, our strategy not only considers key features within the teacher model but also endeavors to capture the relationships and interactions among feature sets, encoding these complex pieces of information into a graph structure to understand and utilize the dynamic relationships among these pieces of information from a global perspective. Experiments show that our method outperforms previous feature distillation methods on the CIFAR-100, MS-COCO, and Pascal VOC datasets, proving its efficiency and applicability.
Read more5/17/2024

0
Lightweight Model Pre-training via Language Guided Knowledge Distillation
Mingsheng Li, Lin Zhang, Mingzhen Zhu, Zilong Huang, Gang Yu, Jiayuan Fan, Tao Chen
This paper studies the problem of pre-training for small models, which is essential for many mobile devices. Current state-of-the-art methods on this problem transfer the representational knowledge of a large network (as a Teacher) into a smaller model (as a Student) using self-supervised distillation, improving the performance of the small model on downstream tasks. However, existing approaches are insufficient in extracting the crucial knowledge that is useful for discerning categories in downstream tasks during the distillation process. In this paper, for the first time, we introduce language guidance to the distillation process and propose a new method named Language-Guided Distillation (LGD) system, which uses category names of the target downstream task to help refine the knowledge transferred between the teacher and student. To this end, we utilize a pre-trained text encoder to extract semantic embeddings from language and construct a textual semantic space called Textual Semantics Bank (TSB). Furthermore, we design a Language-Guided Knowledge Aggregation (LGKA) module to construct the visual semantic space, also named Visual Semantics Bank (VSB). The task-related knowledge is transferred by driving a student encoder to mimic the similarity score distribution inferred by a teacher over TSB and VSB. Compared with other small models obtained by either ImageNet pre-training or self-supervised distillation, experiment results show that the distilled lightweight model using the proposed LGD method presents state-of-the-art performance and is validated on various downstream tasks, including classification, detection, and segmentation. We have made the code available at https://github.com/mZhenz/LGD.
Read more6/18/2024

0
GenDistiller: Distilling Pre-trained Language Models based on an Autoregressive Generative Model
Yingying Gao, Shilei Zhang, Chao Deng, Junlan Feng
Pre-trained speech language models such as HuBERT and WavLM leverage unlabeled speech data for self-supervised learning and offer powerful representations for numerous downstream tasks. Despite the success of these models, their high requirements for memory and computing resource hinder their application on resource restricted devices. Therefore, this paper introduces GenDistiller, a novel knowledge distillation framework which generates the hidden representations of the pre-trained teacher model directly by a much smaller student network. The proposed method takes the previous hidden layer as history and implements a layer-by-layer prediction of the teacher model autoregressively. Experiments on SUPERB reveal the advantage of GenDistiller over the baseline distilling method without an autoregressive framework, with 33% fewer parameters, similar time consumption and better performance on most of the SUPERB tasks. Ultimately, the proposed GenDistiller reduces the size of WavLM by 82%.
Read more6/24/2024