Prompt Selection Matters: Enhancing Text Annotations for Social Sciences with Large Language Models

0

Sign in to get full access
Overview
- This paper explores how the choice of prompts, or instructions, used with large language models (LLMs) can significantly impact the quality of text annotations for social science research.
- The researchers investigate how different prompts affect the performance of LLMs on tasks like topic labeling, sentiment analysis, and entity extraction.
- They find that carefully designing prompts is crucial for effectively leveraging LLMs in computational social science research, and provide guidance on how to select appropriate prompts.
Plain English Explanation
In the field of computational social science, researchers often need to analyze large amounts of text data, such as social media posts, news articles, or survey responses. To make sense of this data, they need to label or categorize the text in various ways, like identifying the topic, sentiment, or key entities.
Prompt Selection Matters: Enhancing Text Annotations for Social Sciences with Large Language Models explores how the specific instructions, or "prompts," given to large language models (LLMs) can greatly influence the quality of these text annotations. LLMs are powerful AI systems that can generate human-like text, and they are increasingly being used in social science research to automate and scale up text analysis.
The researchers found that the choice of prompt can make a big difference in how well the LLM performs on tasks like topic labeling, sentiment analysis, and entity extraction. Poorly designed prompts can lead to inaccurate or biased results, which could undermine the validity of social science research.
To address this, the paper provides guidance on how to carefully select and design prompts to get the most out of LLMs for text annotation tasks. By paying close attention to the prompt, researchers can unlock the full potential of these powerful AI models and enhance the quality and reliability of their computational social science research.
Technical Explanation
Prompt Selection Matters: Enhancing Text Annotations for Social Sciences with Large Language Models investigates how the choice of prompts, or instructions, given to large language models (LLMs) can significantly impact their performance on various text annotation tasks relevant to computational social science research.
The researchers conducted a series of experiments to evaluate the effects of prompt selection on the accuracy and reliability of LLM-generated annotations for tasks like topic labeling, sentiment analysis, and entity extraction. They compared the performance of LLMs on these tasks using a variety of prompts, including both manually curated and automatically generated prompts.
The results showed that the choice of prompt can have a significant impact on the quality of the text annotations produced by the LLMs. Poorly designed prompts led to more inaccurate, biased, or unreliable annotations, while carefully crafted prompts enabled the LLMs to perform much better on the given tasks.
The researchers also explored approaches for automatically selecting and optimizing prompts to improve the performance of LLMs on text annotation tasks. By leveraging techniques like simulation-based optimization, they were able to identify prompts that consistently produced higher-quality annotations across a range of social science datasets and tasks.
Critical Analysis
The paper provides valuable insights into the importance of prompt selection when using large language models (LLMs) for text annotation tasks in computational social science research. The researchers have clearly demonstrated that the choice of prompt can have a substantial impact on the accuracy and reliability of the annotations produced by LLMs.
One potential limitation of the study is the scope of the tasks and datasets used. While the researchers examined a range of common text annotation tasks, such as topic labeling, sentiment analysis, and entity extraction, there may be other types of tasks or domains where the impact of prompt selection could be different. Additionally, the researchers focused primarily on English-language datasets, and the findings may not generalize as well to other languages or cultural contexts.
Another area for further research could be the evaluation of social biases in the LLM-generated annotations. The paper briefly mentions the potential for prompts to introduce biases, but a more in-depth analysis of this issue could provide valuable insights for researchers looking to use LLMs in a responsible and ethical manner.
Overall, this paper makes a strong case for the importance of careful prompt selection when leveraging LLMs for computational social science tasks. By providing practical guidance and insights, the researchers have made a significant contribution to the field and have laid the groundwork for future studies exploring the nuances of prompt design and LLM-powered text annotation.
Conclusion
Prompt Selection Matters: Enhancing Text Annotations for Social Sciences with Large Language Models highlights the critical role that prompt selection plays in the performance of large language models (LLMs) on text annotation tasks relevant to computational social science research.
The researchers have demonstrated that the choice of prompt can have a substantial impact on the accuracy, reliability, and potential biases of the annotations produced by LLMs. By providing guidelines and approaches for designing effective prompts, the paper equips social science researchers with the knowledge and tools to unlock the full potential of LLMs in their work.
As LLMs continue to advance and become more widely adopted in the social sciences, this research serves as an important reminder that the technology is not a panacea. Careful attention to prompt design and the potential pitfalls of LLM-generated annotations will be crucial for ensuring the validity and integrity of computational social science research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Prompt Selection Matters: Enhancing Text Annotations for Social Sciences with Large Language Models
Louis Abraham, Charles Arnal, Antoine Marie
Large Language Models have recently been applied to text annotation tasks from social sciences, equalling or surpassing the performance of human workers at a fraction of the cost. However, no inquiry has yet been made on the impact of prompt selection on labelling accuracy. In this study, we show that performance greatly varies between prompts, and we apply the method of automatic prompt optimization to systematically craft high quality prompts. We also provide the community with a simple, browser-based implementation of the method at https://prompt-ultra.github.io/ .
Read more7/16/2024
0
Prompt Design Matters for Computational Social Science Tasks but in Unpredictable Ways
Shubham Atreja, Joshua Ashkinaze, Lingyao Li, Julia Mendelsohn, Libby Hemphill
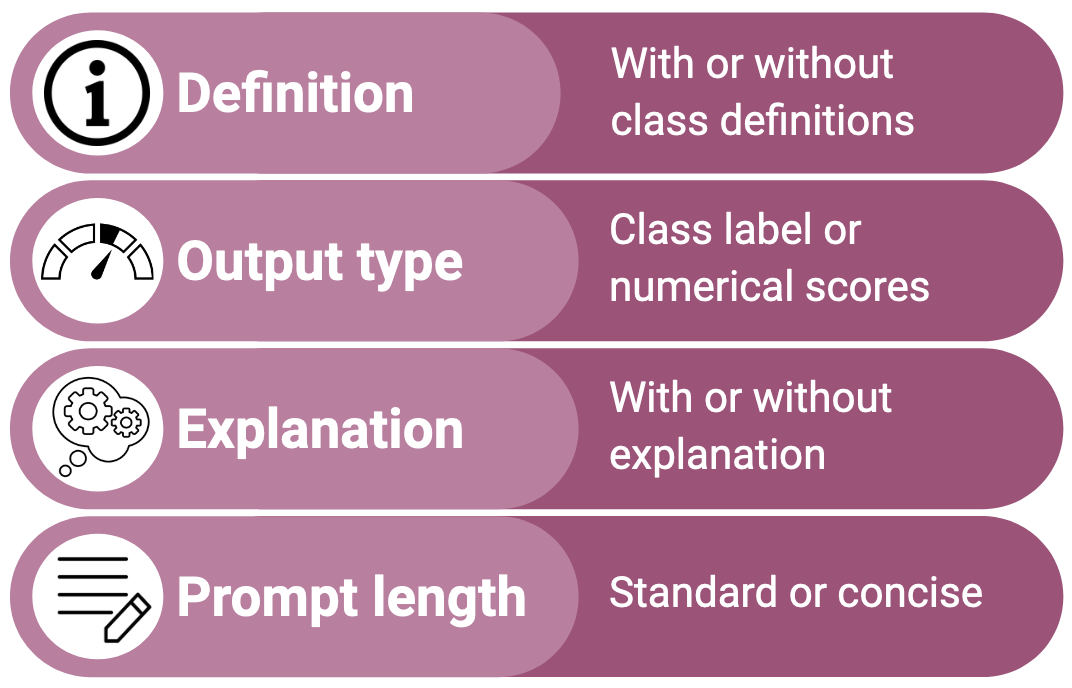
Manually annotating data for computational social science tasks can be costly, time-consuming, and emotionally draining. While recent work suggests that LLMs can perform such annotation tasks in zero-shot settings, little is known about how prompt design impacts LLMs' compliance and accuracy. We conduct a large-scale multi-prompt experiment to test how model selection (ChatGPT, PaLM2, and Falcon7b) and prompt design features (definition inclusion, output type, explanation, and prompt length) impact the compliance and accuracy of LLM-generated annotations on four CSS tasks (toxicity, sentiment, rumor stance, and news frames). Our results show that LLM compliance and accuracy are highly prompt-dependent. For instance, prompting for numerical scores instead of labels reduces all LLMs' compliance and accuracy. The overall best prompting setup is task-dependent, and minor prompt changes can cause large changes in the distribution of generated labels. By showing that prompt design significantly impacts the quality and distribution of LLM-generated annotations, this work serves as both a warning and practical guide for researchers and practitioners.
Read more6/19/2024
0
Zero-shot prompt-based classification: topic labeling in times of foundation models in German Tweets
Simon Munker, Kai Kugler, Achim Rettinger
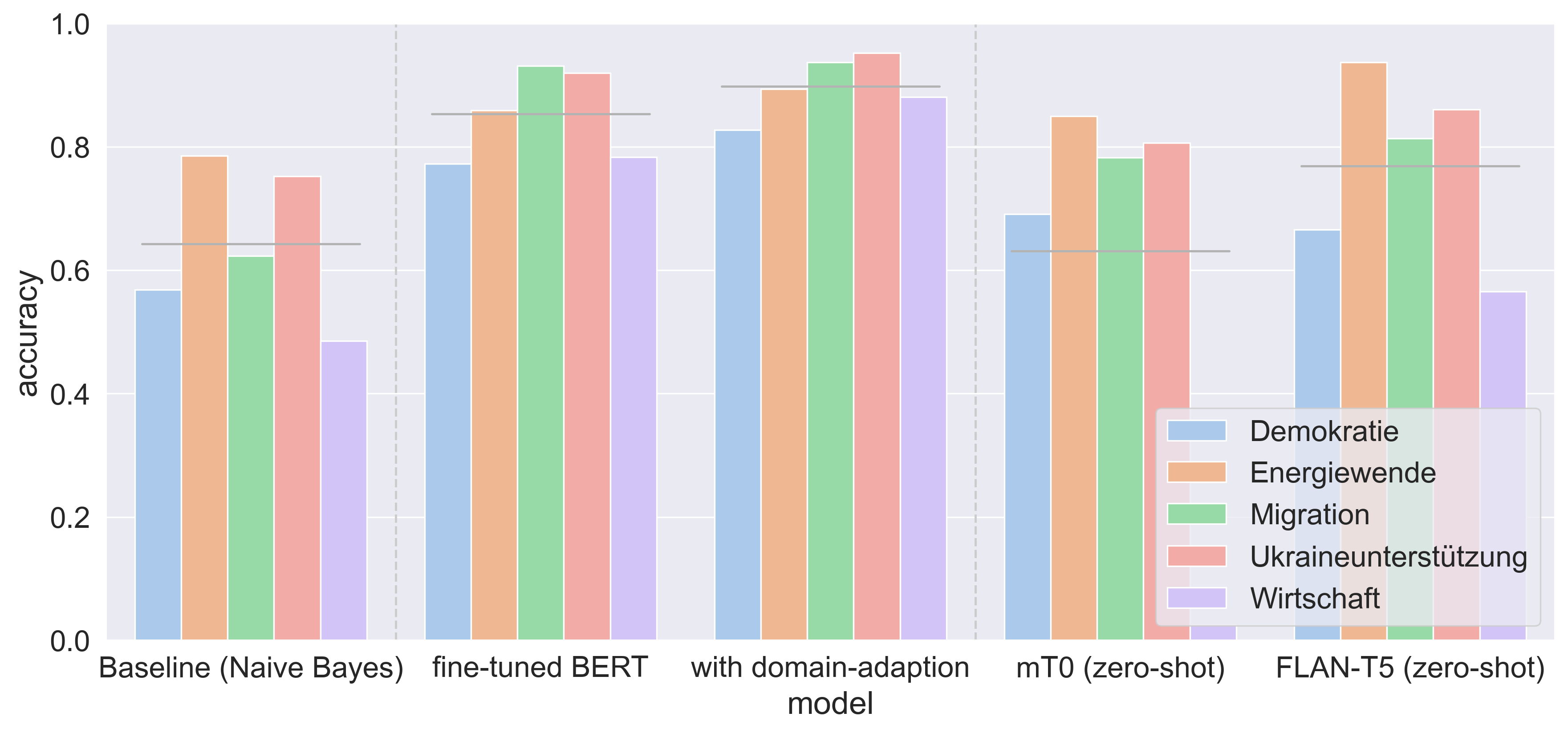
Filtering and annotating textual data are routine tasks in many areas, like social media or news analytics. Automating these tasks allows to scale the analyses wrt. speed and breadth of content covered and decreases the manual effort required. Due to technical advancements in Natural Language Processing, specifically the success of large foundation models, a new tool for automating such annotation processes by using a text-to-text interface given written guidelines without providing training samples has become available. In this work, we assess these advancements in-the-wild by empirically testing them in an annotation task on German Twitter data about social and political European crises. We compare the prompt-based results with our human annotation and preceding classification approaches, including Naive Bayes and a BERT-based fine-tuning/domain adaptation pipeline. Our results show that the prompt-based approach - despite being limited by local computation resources during the model selection - is comparable with the fine-tuned BERT but without any annotated training data. Our findings emphasize the ongoing paradigm shift in the NLP landscape, i.e., the unification of downstream tasks and elimination of the need for pre-labeled training data.
Read more6/27/2024
0
Language Model Prompt Selection via Simulation Optimization
Haoting Zhang, Jinghai He, Rhonda Righter, Zeyu Zheng
With the advancement in generative language models, the selection of prompts has gained significant attention in recent years. A prompt is an instruction or description provided by the user, serving as a guide for the generative language model in content generation. Despite existing methods for prompt selection that are based on human labor, we consider facilitating this selection through simulation optimization, aiming to maximize a pre-defined score for the selected prompt. Specifically, we propose a two-stage framework. In the first stage, we determine a feasible set of prompts in sufficient numbers, where each prompt is represented by a moderate-dimensional vector. In the subsequent stage for evaluation and selection, we construct a surrogate model of the score regarding the moderate-dimensional vectors that represent the prompts. We propose sequentially selecting the prompt for evaluation based on this constructed surrogate model. We prove the consistency of the sequential evaluation procedure in our framework. We also conduct numerical experiments to demonstrate the efficacy of our proposed framework, providing practical instructions for implementation.
Read more5/21/2024