Prospector Heads: Generalized Feature Attribution for Large Models & Data

0
✨
Sign in to get full access
Overview
- Feature attribution is a crucial capability for machine learning (ML) models in scientific and biomedical domains, allowing them to identify the most relevant regions of input data for classification.
- Current feature attribution methods that rely on explaining end-to-end classifier predictions suffer from imprecise localization and are inadequate for small datasets and high-dimensional data due to computational challenges.
- The paper introduces "prospector heads", an efficient and interpretable alternative to explanation-based attribution methods that can be applied to any encoder and any data modality.
Plain English Explanation
Prospector heads are a new technique that can help machine learning models explain which parts of the input data they are using to make their predictions. This is an important capability, especially in scientific and medical fields, where we want to understand why the model is making certain decisions.
Current methods for this type of "feature attribution" often struggle to precisely identify the relevant parts of the input data, especially when working with small datasets or high-dimensional data like images or graphs. This can make it hard to trust the model's decisions and understand what it is basing them on.
The prospector heads method provides an efficient and interpretable alternative. It can be used with any type of machine learning model, regardless of the input data format (text, images, graphs, etc.). The authors show that prospector heads outperform existing feature attribution techniques, helping the models better identify the key regions of the input that are driving their predictions.
This improved interpretability and transparency could help build trust in machine learning models and enable better discovery of patterns in complex datasets, which is crucial for advancing scientific and medical research.
Technical Explanation
The paper introduces "prospector heads", a novel feature attribution method that can be applied to any encoder model and any data modality (e.g., text, images, graphs).
Unlike existing explanation-based attribution methods that rely on the predictions of end-to-end classifiers, prospector heads use a separate module to efficiently and precisely localize the relevant regions of the input data. This module is trained in parallel with the main encoder model, but its objective is to directly maximize the localization performance rather than the classification accuracy.
The authors demonstrate the flexibility and generalizability of prospector heads through experiments on diverse datasets, including text, pathology images, and protein structure graphs. Prospector heads outperform baseline attribution methods by up to 26.3 points in mean localization AUPRC, a metric that measures how well the method can identify the most relevant input features.
The paper also shows how prospector heads can enable improved interpretation and discovery of class-specific patterns in the input data, which is crucial for building trust and transparency in machine learning models, especially in scientific and biomedical applications.
Critical Analysis
The paper provides a thorough evaluation of the prospector heads method, including comparisons to various baseline attribution techniques. However, the authors acknowledge that their approach does have some limitations:
- The prospector heads module adds an extra computational cost to the overall model, which may be a concern for certain real-time applications.
- The method relies on the assumption that the relevant input features are well-localized, which may not always be the case, especially for more complex, holistic patterns in the data.
Additionally, while the authors demonstrate the generalizability of prospector heads across modalities, it would be interesting to see further exploration of the method's performance on even more diverse datasets and tasks, such as topological interpretability or other specialized applications.
Overall, the prospector heads approach represents a promising step forward in developing transparent and interpretable machine learning models for scientific and biomedical domains. The strong empirical results and the conceptual simplicity of the method suggest that it could be a valuable tool for researchers and practitioners alike.
Conclusion
The paper introduces prospector heads, an efficient and interpretable feature attribution method that can be applied to any encoder model and any data modality. Prospector heads outperform existing attribution techniques, helping machine learning models better identify the relevant regions of the input data that drive their predictions.
This improved interpretability and transparency could be crucial for building trust in machine learning models and enabling better discovery of patterns in complex datasets, which is particularly important for advancing scientific and biomedical research. While the method has some limitations, the strong empirical results and the conceptual simplicity of prospector heads suggest that it is a valuable contribution to the field of explainable AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
0
Prospector Heads: Generalized Feature Attribution for Large Models & Data
Gautam Machiraju, Alexander Derry, Arjun Desai, Neel Guha, Amir-Hossein Karimi, James Zou, Russ Altman, Christopher R'e, Parag Mallick
Feature attribution, the ability to localize regions of the input data that are relevant for classification, is an important capability for ML models in scientific and biomedical domains. Current methods for feature attribution, which rely on explaining the predictions of end-to-end classifiers, suffer from imprecise feature localization and are inadequate for use with small sample sizes and high-dimensional datasets due to computational challenges. We introduce prospector heads, an efficient and interpretable alternative to explanation-based attribution methods that can be applied to any encoder and any data modality. Prospector heads generalize across modalities through experiments on sequences (text), images (pathology), and graphs (protein structures), outperforming baseline attribution methods by up to 26.3 points in mean localization AUPRC. We also demonstrate how prospector heads enable improved interpretation and discovery of class-specific patterns in input data. Through their high performance, flexibility, and generalizability, prospectors provide a framework for improving trust and transparency for ML models in complex domains.
Read more6/21/2024

0
Comprehensive Attribution: Inherently Explainable Vision Model with Feature Detector
Xianren Zhang, Dongwon Lee, Suhang Wang
As deep vision models' popularity rapidly increases, there is a growing emphasis on explanations for model predictions. The inherently explainable attribution method aims to enhance the understanding of model behavior by identifying the important regions in images that significantly contribute to predictions. It is achieved by cooperatively training a selector (generating an attribution map to identify important features) and a predictor (making predictions using the identified features). Despite many advancements, existing methods suffer from the incompleteness problem, where discriminative features are masked out, and the interlocking problem, where the non-optimized selector initially selects noise, causing the predictor to fit on this noise and perpetuate the cycle. To address these problems, we introduce a new objective that discourages the presence of discriminative features in the masked-out regions thus enhancing the comprehensiveness of feature selection. A pre-trained detector is introduced to detect discriminative features in the masked-out region. If the selector selects noise instead of discriminative features, the detector can observe and break the interlocking situation by penalizing the selector. Extensive experiments show that our model makes accurate predictions with higher accuracy than the regular black-box model, and produces attribution maps with high feature coverage, localization ability, fidelity and robustness. Our code will be available at href{https://github.com/Zood123/COMET}{https://github.com/Zood123/COMET}.
Read more8/7/2024
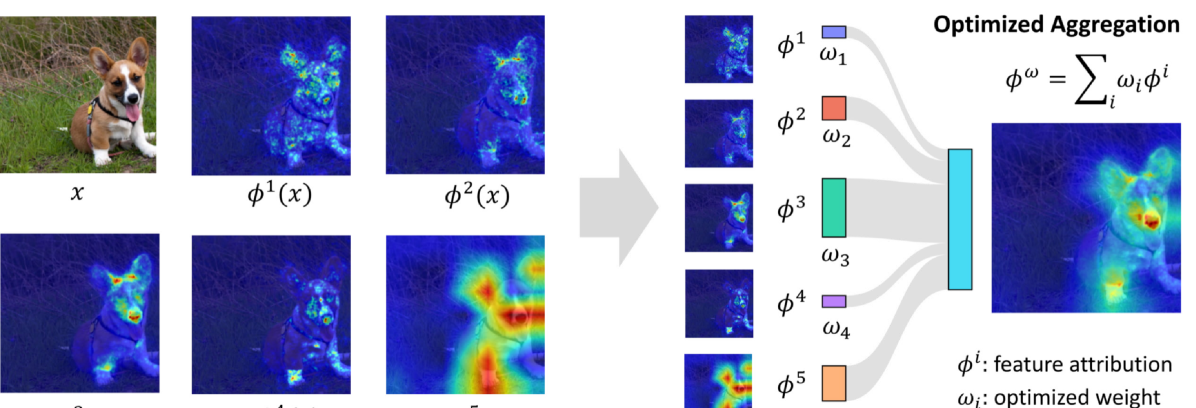
0
Provably Better Explanations with Optimized Aggregation of Feature Attributions
Thomas Decker, Ananta R. Bhattarai, Jindong Gu, Volker Tresp, Florian Buettner
Using feature attributions for post-hoc explanations is a common practice to understand and verify the predictions of opaque machine learning models. Despite the numerous techniques available, individual methods often produce inconsistent and unstable results, putting their overall reliability into question. In this work, we aim to systematically improve the quality of feature attributions by combining multiple explanations across distinct methods or their variations. For this purpose, we propose a novel approach to derive optimal convex combinations of feature attributions that yield provable improvements of desired quality criteria such as robustness or faithfulness to the model behavior. Through extensive experiments involving various model architectures and popular feature attribution techniques, we demonstrate that our combination strategy consistently outperforms individual methods and existing baselines.
Read more6/10/2024

0
Selective Explanations
Lucas Monteiro Paes, Dennis Wei, Flavio P. Calmon
Feature attribution methods explain black-box machine learning (ML) models by assigning importance scores to input features. These methods can be computationally expensive for large ML models. To address this challenge, there has been increasing efforts to develop amortized explainers, where a machine learning model is trained to predict feature attribution scores with only one inference. Despite their efficiency, amortized explainers can produce inaccurate predictions and misleading explanations. In this paper, we propose selective explanations, a novel feature attribution method that (i) detects when amortized explainers generate low-quality explanations and (ii) improves these explanations using a technique called explanations with initial guess. Our selective explanation method allows practitioners to specify the fraction of samples that receive explanations with initial guess, offering a principled way to bridge the gap between amortized explainers and their high-quality counterparts.
Read more5/31/2024