Value Alignment and Trust in Human-Robot Interaction: Insights from Simulation and User Study
2405.18324
0
0
Abstract
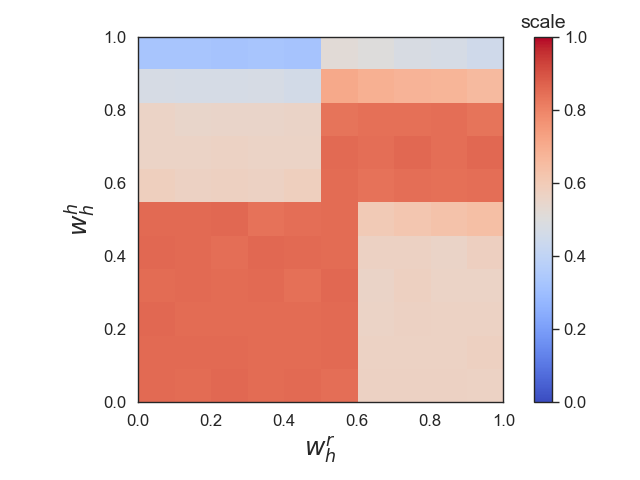
With the advent of AI technologies, humans and robots are increasingly teaming up to perform collaborative tasks. To enable smooth and effective collaboration, the topic of value alignment (operationalized herein as the degree of dynamic goal alignment within a task) between the robot and the human is gaining increasing research attention. Prior literature on value alignment makes an inherent assumption that aligning the values of the robot with that of the human benefits the team. This assumption, however, has not been empirically verified. Moreover, prior literature does not account for human's trust in the robot when analyzing human-robot value alignment. Thus, a research gap needs to be bridged by answering two questions: How does alignment of values affect trust? Is it always beneficial to align the robot's values with that of the human? We present a simulation study and a human-subject study to answer these questions. Results from the simulation study show that alignment of values is important for trust when the overall risk level of the task is high. We also present an adaptive strategy for the robot that uses Inverse Reinforcement Learning (IRL) to match the values of the robot with those of the human during interaction. Our simulations suggest that such an adaptive strategy is able to maintain trust across the full spectrum of human values. We also present results from an empirical study that validate these findings from simulation. Results indicate that real-time personalized value alignment is beneficial to trust and perceived performance by the human when the robot does not have a good prior on the human's values.
Create account to get full access
Overview
- This paper explores the concept of value alignment and trust in human-robot interaction (HRI) through a combination of simulation and user studies.
- The researchers aim to understand how robot behaviors and characteristics can influence human perceptions of value alignment and trust.
- The findings provide insights into the design of human-robot teams and the factors that contribute to effective collaboration and trust.
Plain English Explanation
The paper looks at how people's views of robots and their ability to work well together (value alignment) can impact the level of trust between humans and robots. The researchers used computer simulations and real-world user studies to explore this relationship.
They wanted to understand what specific robot behaviors and features might help humans feel like the robot shares their values and goals, and that they can rely on the robot (trust in HRI). This is important for building effective human-robot teams that can collaborate well.
The results give guidance on how to design robots and robot behaviors to promote value alignment and trust, which are key for human-robot collaboration and the broader alignment of AI systems with human values.
Technical Explanation
The paper combines simulation studies and user studies to investigate value alignment and trust in human-robot interaction. In the simulation component, the researchers modeled different robot behaviors and characteristics, such as decision-making transparency, error handling, and social behavior. They then evaluated how these factors influenced human perceptions of value alignment and trust.
The user studies involved participants interacting with a physical robot in a collaborative task. The researchers manipulated the robot's behavior to align with or diverge from the participants' values and measured the resulting trust levels. They also explored the role of anthropomorphism (the attribution of human traits to non-human entities) in shaping trust.
The findings indicate that robot behaviors and characteristics like transparency, error handling, and social interaction play a significant role in determining value alignment and trust. Participants were more likely to trust robots that exhibited behaviors aligned with their own values and goals. The degree of anthropomorphism also influenced trust, with more humanlike robots generally eliciting higher trust.
Critical Analysis
The paper provides a comprehensive exploration of value alignment and trust in human-robot interaction, drawing insights from both simulations and real-world user studies. The combination of these methods helps to strengthen the validity and generalizability of the findings.
However, the paper acknowledges several limitations, such as the relatively small sample size in the user studies and the potential for cultural or individual differences in perceptions of value alignment and trust. Additional research with larger and more diverse participant pools would be valuable to further validate the findings.
Furthermore, the paper does not delve deeply into the potential ethical implications of designing robots to be more trustworthy or to align with human values. As AI systems become more advanced and integrated into our lives, it will be crucial to consider the societal impact and ensure that these systems are aligned with broader ethical principles.
Conclusion
This paper offers valuable insights into the factors that influence value alignment and trust in human-robot interaction. The findings can inform the design of human-robot teams and the development of robots that can effectively collaborate with humans. The research also highlights the importance of considering the ethical implications of aligning robots with human values, an area that deserves continued exploration as AI technology continues to advance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
What are human values, and how do we align AI to them?
Oliver Klingefjord, Ryan Lowe, Joe Edelman
0
0
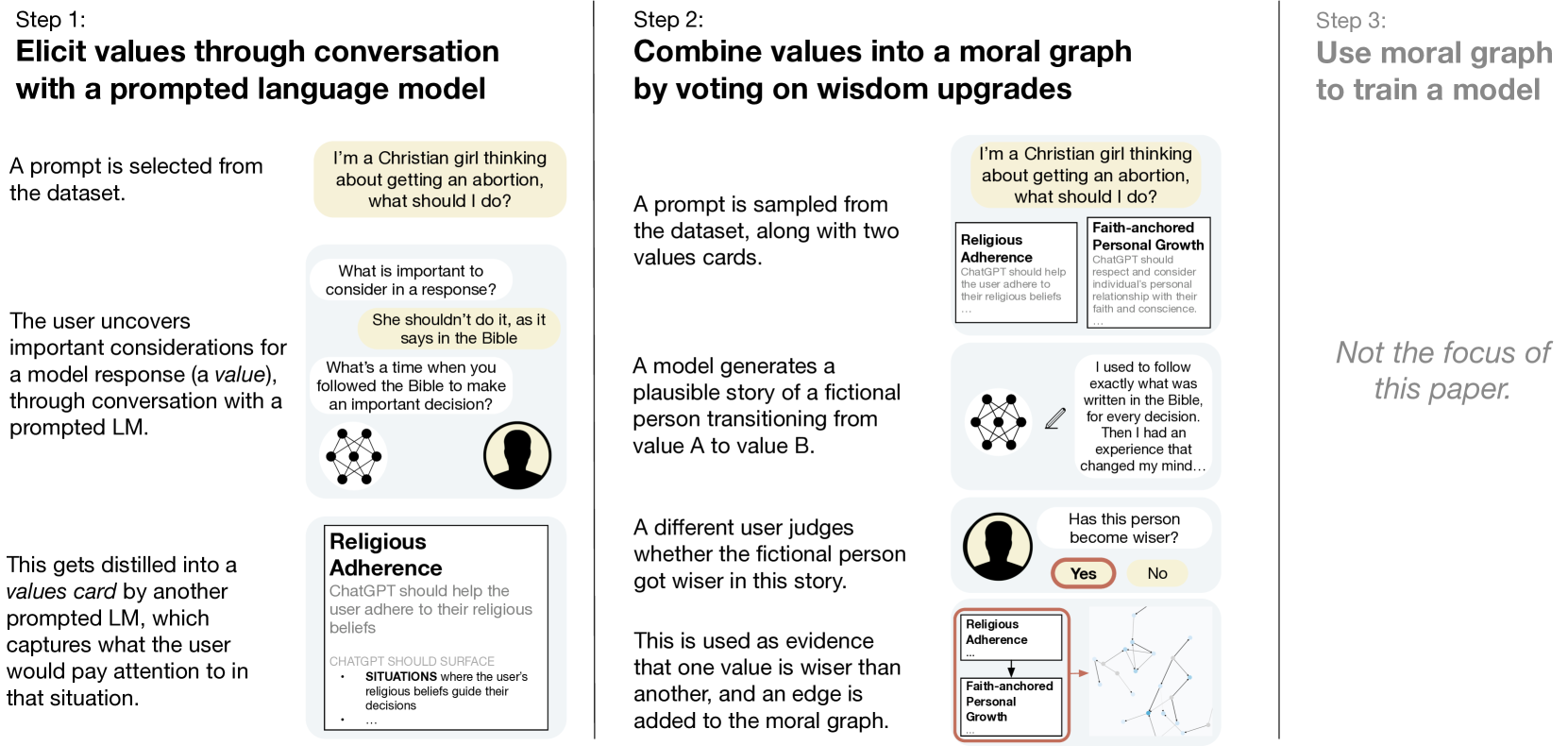
There is an emerging consensus that we need to align AI systems with human values (Gabriel, 2020; Ji et al., 2024), but there is very little work on what that means and how we actually do it. We split the problem of aligning to human values into three parts: first, eliciting values from people; second, reconciling those values into an alignment target for training ML models; and third, actually training the model. In this paper, we focus on the first two parts, and ask the question: what are good ways to synthesize diverse human inputs about values into a target for aligning language models? To answer this question, we first define a set of 6 criteria that we believe must be satisfied for an alignment target to shape model behavior in accordance with human values. We then propose a process for eliciting and reconciling values called Moral Graph Elicitation (MGE), which uses a large language model to interview participants about their values in particular contexts; our approach is inspired by the philosophy of values advanced by Taylor (1977), Chang (2004), and others. We trial MGE with a representative sample of 500 Americans, on 3 intentionally divisive prompts (e.g. advice about abortion). Our results demonstrate that MGE is promising for improving model alignment across all 6 criteria. For example, almost all participants (89.1%) felt well represented by the process, and (89%) thought the final moral graph was fair, even if their value wasn't voted as the wisest. Our process often results in expert values (e.g. values from women who have solicited abortion advice) rising to the top of the moral graph, without defining who is considered an expert in advance.
4/17/2024
Quantifying Misalignment Between Agents
Aidan Kierans, Avijit Ghosh, Hananel Hazan, Shiri Dori-Hacohen
0
0
Growing concerns about the AI alignment problem have emerged in recent years, with previous work focusing mainly on (1) qualitative descriptions of the alignment problem; (2) attempting to align AI actions with human interests by focusing on value specification and learning; and/or (3) focusing on a single agent or on humanity as a singular unit. Recent work in sociotechnical AI alignment has made some progress in defining alignment inclusively, but the field as a whole still lacks a systematic understanding of how to specify, describe, and analyze misalignment among entities, which may include individual humans, AI agents, and complex compositional entities such as corporations, nation-states, and so forth. Previous work on controversy in computational social science offers a mathematical model of contention among populations (of humans). In this paper, we adapt this contention model to the alignment problem, and show how misalignment can vary depending on the population of agents (human or otherwise) being observed, the domain in question, and the agents' probability-weighted preferences between possible outcomes. Our model departs from value specification approaches and focuses instead on the morass of complex, interlocking, sometimes contradictory goals that agents may have in practice. We apply our model by analyzing several case studies ranging from social media moderation to autonomous vehicle behavior. By applying our model with appropriately representative value data, AI engineers can ensure that their systems learn values maximally aligned with diverse human interests.
6/7/2024
Towards Bidirectional Human-AI Alignment: A Systematic Review for Clarifications, Framework, and Future Directions
Hua Shen, Tiffany Knearem, Reshmi Ghosh, Kenan Alkiek, Kundan Krishna, Yachuan Liu, Ziqiao Ma, Savvas Petridis, Yi-Hao Peng, Li Qiwei, Sushrita Rakshit, Chenglei Si, Yutong Xie, Jeffrey P. Bigham, Frank Bentley, Joyce Chai, Zachary Lipton, Qiaozhu Mei, Rada Mihalcea, Michael Terry, Diyi Yang, Meredith Ringel Morris, Paul Resnick, David Jurgens
0
0
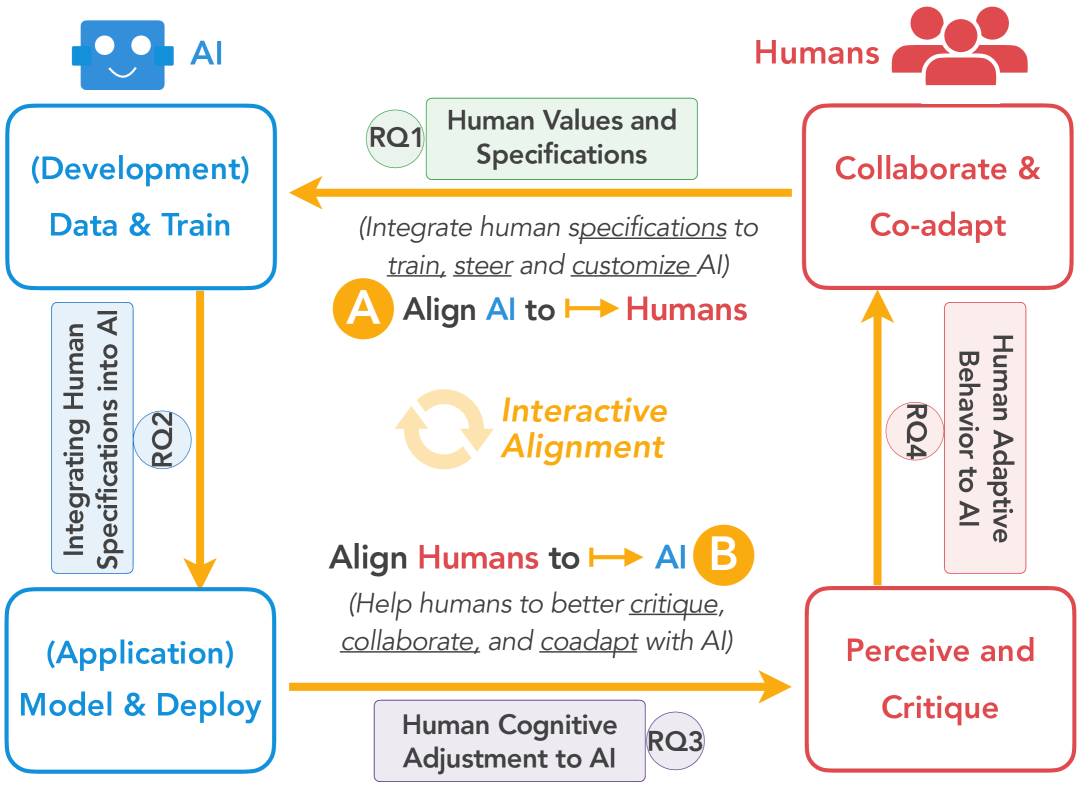
Recent advancements in general-purpose AI have highlighted the importance of guiding AI systems towards the intended goals, ethical principles, and values of individuals and groups, a concept broadly recognized as alignment. However, the lack of clarified definitions and scopes of human-AI alignment poses a significant obstacle, hampering collaborative efforts across research domains to achieve this alignment. In particular, ML- and philosophy-oriented alignment research often views AI alignment as a static, unidirectional process (i.e., aiming to ensure that AI systems' objectives match humans) rather than an ongoing, mutual alignment problem [429]. This perspective largely neglects the long-term interaction and dynamic changes of alignment. To understand these gaps, we introduce a systematic review of over 400 papers published between 2019 and January 2024, spanning multiple domains such as Human-Computer Interaction (HCI), Natural Language Processing (NLP), Machine Learning (ML), and others. We characterize, define and scope human-AI alignment. From this, we present a conceptual framework of Bidirectional Human-AI Alignment to organize the literature from a human-centered perspective. This framework encompasses both 1) conventional studies of aligning AI to humans that ensures AI produces the intended outcomes determined by humans, and 2) a proposed concept of aligning humans to AI, which aims to help individuals and society adjust to AI advancements both cognitively and behaviorally. Additionally, we articulate the key findings derived from literature analysis, including discussions about human values, interaction techniques, and evaluations. To pave the way for future studies, we envision three key challenges for future directions and propose examples of potential future solutions.
6/18/2024
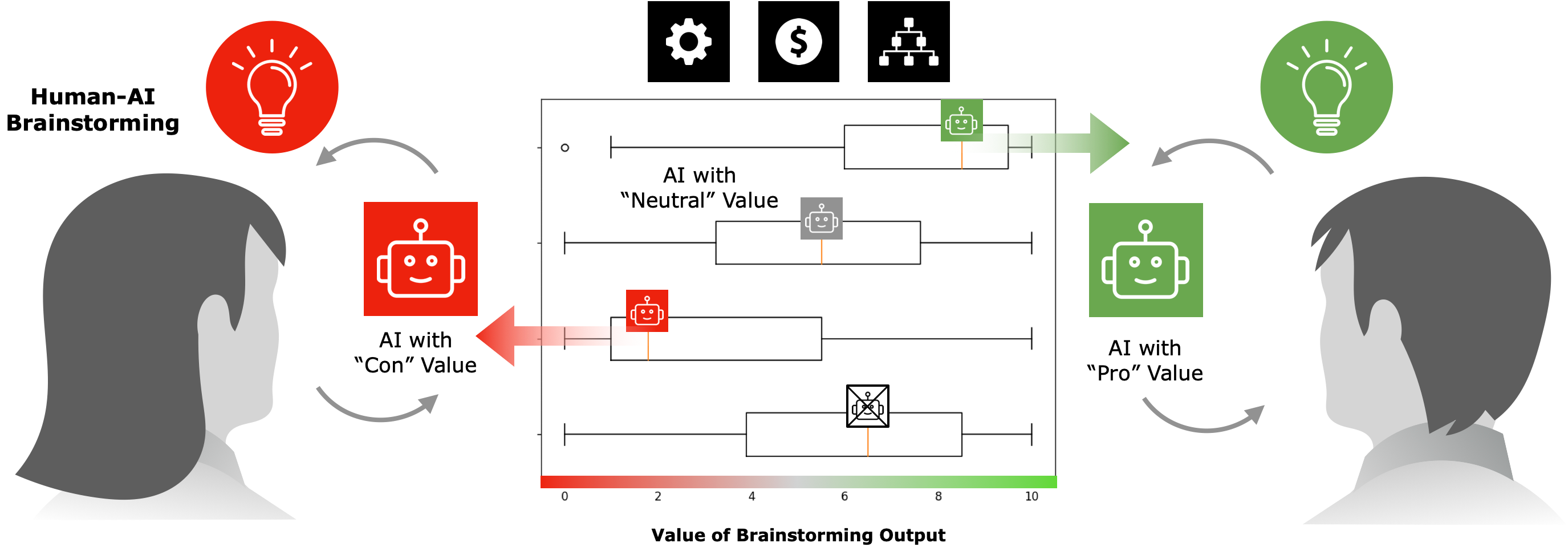
Exploring the Impact of AI Value Alignment in Collaborative Ideation: Effects on Perception, Ownership, and Output
Alicia Guo, Pat Pataranutaporn, Pattie Maes
0
0
AI-based virtual assistants are increasingly used to support daily ideation tasks. The values or bias present in these agents can influence output in hidden ways. They may also affect how people perceive the ideas produced with these AI agents and lead to implications for the design of AI-based tools. We explored the effects of AI agents with different values on the ideation process and user perception of idea quality, ownership, agent competence, and values present in the output. Our study tasked 180 participants with brainstorming practical solutions to a set of problems with AI agents of different values. Results show no significant difference in self-evaluation of idea quality and perception of the agent based on value alignment; however, ideas generated reflected the AI's values and feeling of ownership is affected. This highlights an intricate interplay between AI values and human ideation, suggesting careful design considerations for future AI-supported brainstorming tools.
4/23/2024