Raccoon: Prompt Extraction Benchmark of LLM-Integrated Applications

1

Sign in to get full access
Overview
• This paper introduces Raccoon, a benchmark for evaluating the ability of large language models (LLMs) to resist prompt extraction attacks, where an attacker attempts to extract the original prompt used to generate a given output.
• Prompt extraction attacks are a critical security concern for LLM-integrated applications, as they could allow attackers to reverse-engineer sensitive prompts and gain unauthorized access to restricted functionalities.
• The Raccoon benchmark provides a standardized set of test cases and evaluation metrics to assess an LLM's robustness against such attacks, with the goal of driving progress in this important area of research.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. These models are increasingly being integrated into various applications, from chatbots to content generation tools. However, there is a growing concern about the security of these LLM-integrated applications.
One key security threat is the risk of prompt extraction attacks. In these attacks, a malicious user tries to figure out the original prompt (or instructions) that was used to generate a particular output from the LLM. If successful, the attacker could potentially reverse-engineer sensitive prompts and gain unauthorized access to restricted functionalities within the application.
To address this issue, the researchers have developed a new benchmark called Raccoon. Raccoon provides a standardized way to evaluate how well an LLM can resist prompt extraction attacks. It includes a set of test cases and evaluation metrics that can be used to assess an LLM's security in this regard.
By using Raccoon, researchers and developers can better understand the vulnerabilities of their LLM-integrated applications and work on improving the models' robustness against these types of attacks. This is an important step in ensuring the security and trustworthiness of AI systems as they become more ubiquitous in our daily lives.
Technical Explanation
The Raccoon benchmark is designed to assess an LLM's ability to resist prompt extraction attacks, where an attacker attempts to determine the original prompt used to generate a given output. The benchmark includes a set of test cases that cover different types of prompts, ranging from simple instructions to more complex, multi-step tasks.
For each test case, the benchmark evaluates the LLM's performance on two key metrics:
- Prompt Reconstruction Accuracy: This measures how well the attacker can reconstruct the original prompt from the generated output.
- Output Fidelity: This assesses how closely the LLM's output matches the expected result, even in the face of prompt extraction attempts.
The researchers have also developed a dataset of diverse prompts and their corresponding outputs to serve as the benchmark's test cases. This dataset covers a wide range of domains, including text generation, translation, and question-answering.
By using the Raccoon benchmark, researchers and developers can identify vulnerabilities in their LLM-integrated applications and work on improving the models' robustness against prompt extraction attacks. This is a crucial step in ensuring the security and trustworthiness of AI systems as they become more prevalent in our daily lives.
Critical Analysis
The Raccoon benchmark is a valuable contribution to the field of LLM security research, as it provides a standardized way to evaluate the resilience of these models against a critical attack vector. However, it's important to note that the benchmark has some limitations and potential areas for further research.
One key limitation is that the Raccoon dataset may not fully capture the diversity and complexity of real-world prompts used in LLM-integrated applications. While the researchers have made an effort to include a wide range of prompt types, there may be additional scenarios that are not yet represented in the benchmark.
Additionally, the Raccoon benchmark focuses solely on the security aspect of prompt extraction attacks, without considering other potential security risks or broader implications of LLM integration. For example, the benchmark does not address issues related to data privacy, model bias, or the potential for LLMs to be used for malicious purposes, such as disinformation campaigns.
Further research could explore ways to expand the Raccoon benchmark to address these broader security and ethical concerns, as well as investigate potential defenses against prompt extraction attacks, such as those discussed in Formalizing and Benchmarking Prompt Injection Attacks and Defenses and Wolf in Sheep's Clothing: Generalized Nested Jailbreak Prompts.
Conclusion
The Raccoon benchmark is a valuable tool for researchers and developers working on the security of LLM-integrated applications. By providing a standardized way to evaluate an LLM's resilience against prompt extraction attacks, Raccoon can help drive progress in this critical area of AI security research.
As LLMs become increasingly ubiquitous, it is essential to ensure that these powerful models are secure and trustworthy. The Raccoon benchmark is an important step in this direction, but continued effort and innovation will be needed to address the broader security and ethical challenges posed by the integration of LLMs into real-world applications, as discussed in Do Anything Now: Characterizing and Evaluating Emergent "Jailbreak" Capabilities in Large Language Models and Robust Prompt Optimization: Defending Language Models Against Prompt Attacks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
Raccoon: Prompt Extraction Benchmark of LLM-Integrated Applications
Junlin Wang, Tianyi Yang, Roy Xie, Bhuwan Dhingra
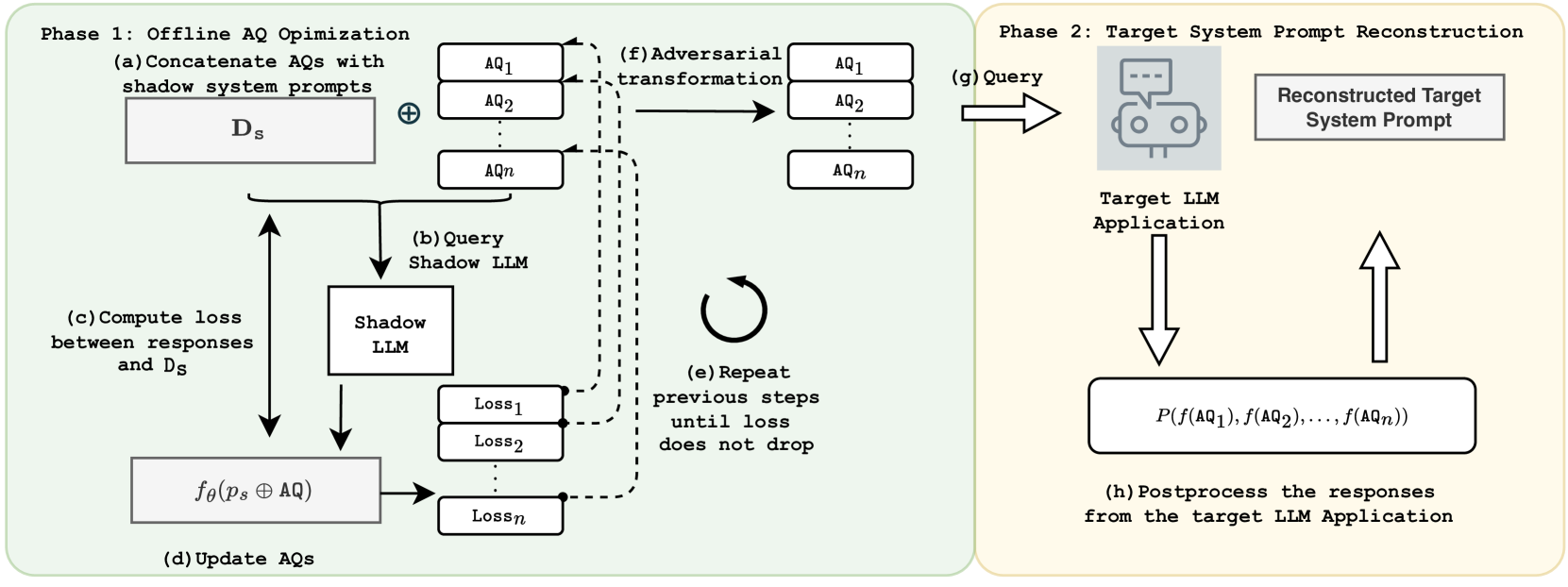
With the proliferation of LLM-integrated applications such as GPT-s, millions are deployed, offering valuable services through proprietary instruction prompts. These systems, however, are prone to prompt extraction attacks through meticulously designed queries. To help mitigate this problem, we introduce the Raccoon benchmark which comprehensively evaluates a model's susceptibility to prompt extraction attacks. Our novel evaluation method assesses models under both defenseless and defended scenarios, employing a dual approach to evaluate the effectiveness of existing defenses and the resilience of the models. The benchmark encompasses 14 categories of prompt extraction attacks, with additional compounded attacks that closely mimic the strategies of potential attackers, alongside a diverse collection of defense templates. This array is, to our knowledge, the most extensive compilation of prompt theft attacks and defense mechanisms to date. Our findings highlight universal susceptibility to prompt theft in the absence of defenses, with OpenAI models demonstrating notable resilience when protected. This paper aims to establish a more systematic benchmark for assessing LLM robustness against prompt extraction attacks, offering insights into their causes and potential countermeasures. Resources of Raccoon are publicly available at https://github.com/M0gician/RaccoonBench.
Read more6/12/2024
0
PLeak: Prompt Leaking Attacks against Large Language Model Applications
Bo Hui, Haolin Yuan, Neil Gong, Philippe Burlina, Yinzhi Cao
Large Language Models (LLMs) enable a new ecosystem with many downstream applications, called LLM applications, with different natural language processing tasks. The functionality and performance of an LLM application highly depend on its system prompt, which instructs the backend LLM on what task to perform. Therefore, an LLM application developer often keeps a system prompt confidential to protect its intellectual property. As a result, a natural attack, called prompt leaking, is to steal the system prompt from an LLM application, which compromises the developer's intellectual property. Existing prompt leaking attacks primarily rely on manually crafted queries, and thus achieve limited effectiveness. In this paper, we design a novel, closed-box prompt leaking attack framework, called PLeak, to optimize an adversarial query such that when the attacker sends it to a target LLM application, its response reveals its own system prompt. We formulate finding such an adversarial query as an optimization problem and solve it with a gradient-based method approximately. Our key idea is to break down the optimization goal by optimizing adversary queries for system prompts incrementally, i.e., starting from the first few tokens of each system prompt step by step until the entire length of the system prompt. We evaluate PLeak in both offline settings and for real-world LLM applications, e.g., those on Poe, a popular platform hosting such applications. Our results show that PLeak can effectively leak system prompts and significantly outperforms not only baselines that manually curate queries but also baselines with optimized queries that are modified and adapted from existing jailbreaking attacks. We responsibly reported the issues to Poe and are still waiting for their response. Our implementation is available at this repository: https://github.com/BHui97/PLeak.
Read more5/15/2024
✨
0
Formalizing and Benchmarking Prompt Injection Attacks and Defenses
Yupei Liu, Yuqi Jia, Runpeng Geng, Jinyuan Jia, Neil Zhenqiang Gong
A prompt injection attack aims to inject malicious instruction/data into the input of an LLM-Integrated Application such that it produces results as an attacker desires. Existing works are limited to case studies. As a result, the literature lacks a systematic understanding of prompt injection attacks and their defenses. We aim to bridge the gap in this work. In particular, we propose a framework to formalize prompt injection attacks. Existing attacks are special cases in our framework. Moreover, based on our framework, we design a new attack by combining existing ones. Using our framework, we conduct a systematic evaluation on 5 prompt injection attacks and 10 defenses with 10 LLMs and 7 tasks. Our work provides a common benchmark for quantitatively evaluating future prompt injection attacks and defenses. To facilitate research on this topic, we make our platform public at https://github.com/liu00222/Open-Prompt-Injection.
Read more6/4/2024
💬
0
A Wolf in Sheep's Clothing: Generalized Nested Jailbreak Prompts can Fool Large Language Models Easily
Peng Ding, Jun Kuang, Dan Ma, Xuezhi Cao, Yunsen Xian, Jiajun Chen, Shujian Huang
Large Language Models (LLMs), such as ChatGPT and GPT-4, are designed to provide useful and safe responses. However, adversarial prompts known as 'jailbreaks' can circumvent safeguards, leading LLMs to generate potentially harmful content. Exploring jailbreak prompts can help to better reveal the weaknesses of LLMs and further steer us to secure them. Unfortunately, existing jailbreak methods either suffer from intricate manual design or require optimization on other white-box models, which compromises either generalization or efficiency. In this paper, we generalize jailbreak prompt attacks into two aspects: (1) Prompt Rewriting and (2) Scenario Nesting. Based on this, we propose ReNeLLM, an automatic framework that leverages LLMs themselves to generate effective jailbreak prompts. Extensive experiments demonstrate that ReNeLLM significantly improves the attack success rate while greatly reducing the time cost compared to existing baselines. Our study also reveals the inadequacy of current defense methods in safeguarding LLMs. Finally, we analyze the failure of LLMs defense from the perspective of prompt execution priority, and propose corresponding defense strategies. We hope that our research can catalyze both the academic community and LLMs developers towards the provision of safer and more regulated LLMs. The code is available at https://github.com/NJUNLP/ReNeLLM.
Read more4/9/2024