On the Rashomon ratio of infinite hypothesis sets

0

Sign in to get full access
Overview
- Examines the Rashomon ratio, a metric that quantifies the number of good models in an infinite hypothesis set.
- Proposes a new approach to estimate the Rashomon ratio for certain types of models.
- Demonstrates the technique on simulated and real-world datasets, showing that the Rashomon ratio can be much higher than previously thought.
Plain English Explanation
The paper explores a concept called the Rashomon ratio, which is a way to measure how many good models can be found in a very large set of possible models. This is an important question in machine learning, because often there are many different models that can fit the data well, but we want to know how many truly good ones there are.
The authors propose a new method to estimate the Rashomon ratio, which works for certain types of models. They show through experiments on simulated data and real-world datasets that the Rashomon ratio can actually be much higher than previously thought. This suggests that there may be many more good models out there than we realize, which has implications for robustly estimating heterogeneity in factorial data using Rashomon, how many good models we need for imbalanced classification, and the importance of the distribution when getting rid of unstable single point estimates.
Technical Explanation
The paper introduces a new approach to estimate the Rashomon ratio, which quantifies the number of good models in an infinite hypothesis set. The Rashomon ratio was previously studied in the context of performance is not enough: The story told by distribution and multiply robust causal change attribution.
The authors focus on a specific class of models where the loss function decomposes into a sum of local losses. They show that for this class, the Rashomon ratio can be estimated by bounding the volume of the set of good models. The key insight is that this volume can be approximated using importance sampling.
The authors validate their approach through experiments on simulated data as well as real-world datasets, including census, housing, and airline passenger data. They find that the Rashomon ratio can be much higher than previously thought, suggesting the existence of many good models in large hypothesis sets.
Critical Analysis
The paper makes a valuable contribution by proposing a new method to estimate the Rashomon ratio for a certain class of models. This is an important problem, as the Rashomon ratio can have significant implications for model selection, uncertainty quantification, and robustness.
One potential limitation of the work is that it focuses on a specific class of models where the loss function decomposes into a sum of local losses. While this class encompasses many commonly used models, it would be interesting to see if the approach can be generalized to other model families.
Additionally, the paper does not provide a detailed analysis of the computational complexity of the proposed estimation method. As the authors note, the method involves importance sampling, which can be challenging to implement efficiently, especially for high-dimensional problems.
Finally, the paper does not fully address the question of how to interpret and use the estimated Rashomon ratio in practice. While the authors discuss some potential implications, further research may be needed to understand how the Rashomon ratio can be leveraged to improve machine learning model selection and deployment.
Conclusion
This paper presents a novel approach to estimating the Rashomon ratio, a metric that quantifies the number of good models in an infinite hypothesis set. The authors show that for a certain class of models, the Rashomon ratio can be much higher than previously thought, suggesting the existence of many good models in large hypothesis spaces.
This finding has important implications for machine learning, as it challenges the common assumption that there is a single "best" model and highlights the need to consider model uncertainty and robustness. The authors' approach to estimating the Rashomon ratio provides a valuable tool for researchers and practitioners to better understand the complexity of model selection and the potential for multiple good solutions in their problems of interest.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
On the Rashomon ratio of infinite hypothesis sets
Evzenie Coupkova, Mireille Boutin
Given a classification problem and a family of classifiers, the Rashomon ratio measures the proportion of classifiers that yield less than a given loss. Previous work has explored the advantage of a large Rashomon ratio in the case of a finite family of classifiers. Here we consider the more general case of an infinite family. We show that a large Rashomon ratio guarantees that choosing the classifier with the best empirical accuracy among a random subset of the family, which is likely to improve generalizability, will not increase the empirical loss too much. We quantify the Rashomon ratio in two examples involving infinite classifier families in order to illustrate situations in which it is large. In the first example, we estimate the Rashomon ratio of the classification of normally distributed classes using an affine classifier. In the second, we obtain a lower bound for the Rashomon ratio of a classification problem with a modified Gram matrix when the classifier family consists of two-layer ReLU neural networks. In general, we show that the Rashomon ratio can be estimated using a training dataset along with random samples from the classifier family and we provide guarantees that such an estimation is close to the true value of the Rashomon ratio.
Read more4/30/2024

0
Amazing Things Come From Having Many Good Models
Cynthia Rudin, Chudi Zhong, Lesia Semenova, Margo Seltzer, Ronald Parr, Jiachang Liu, Srikar Katta, Jon Donnelly, Harry Chen, Zachery Boner
The Rashomon Effect, coined by Leo Breiman, describes the phenomenon that there exist many equally good predictive models for the same dataset. This phenomenon happens for many real datasets and when it does, it sparks both magic and consternation, but mostly magic. In light of the Rashomon Effect, this perspective piece proposes reshaping the way we think about machine learning, particularly for tabular data problems in the nondeterministic (noisy) setting. We address how the Rashomon Effect impacts (1) the existence of simple-yet-accurate models, (2) flexibility to address user preferences, such as fairness and monotonicity, without losing performance, (3) uncertainty in predictions, fairness, and explanations, (4) reliable variable importance, (5) algorithm choice, specifically, providing advanced knowledge of which algorithms might be suitable for a given problem, and (6) public policy. We also discuss a theory of when the Rashomon Effect occurs and why. Our goal is to illustrate how the Rashomon Effect can have a massive impact on the use of machine learning for complex problems in society.
Read more7/11/2024
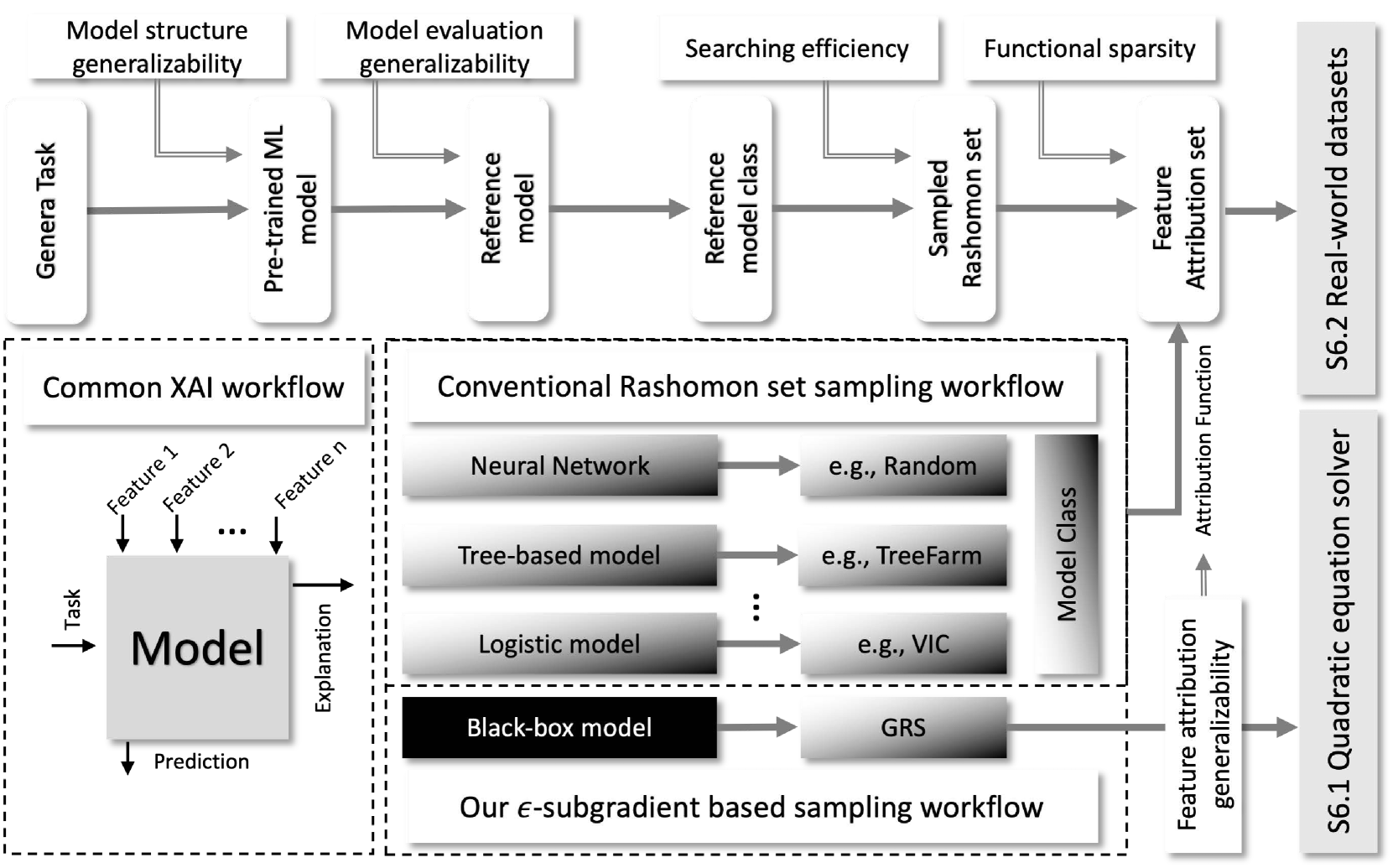
0
Practical Attribution Guidance for Rashomon Sets
Sichao Li, Amanda S. Barnard, Quanling Deng
Different prediction models might perform equally well (Rashomon set) in the same task, but offer conflicting interpretations and conclusions about the data. The Rashomon effect in the context of Explainable AI (XAI) has been recognized as a critical factor. Although the Rashomon set has been introduced and studied in various contexts, its practical application is at its infancy stage and lacks adequate guidance and evaluation. We study the problem of the Rashomon set sampling from a practical viewpoint and identify two fundamental axioms - generalizability and implementation sparsity that exploring methods ought to satisfy in practical usage. These two axioms are not satisfied by most known attribution methods, which we consider to be a fundamental weakness. We use the norms to guide the design of an $epsilon$-subgradient-based sampling method. We apply this method to a fundamental mathematical problem as a proof of concept and to a set of practical datasets to demonstrate its ability compared with existing sampling methods.
Read more7/29/2024

0
Efficient Exploration of the Rashomon Set of Rule Set Models
Martino Ciaperoni, Han Xiao, Aristides Gionis
Today, as increasingly complex predictive models are developed, simple rule sets remain a crucial tool to obtain interpretable predictions and drive high-stakes decision making. However, a single rule set provides a partial representation of a learning task. An emerging paradigm in interpretable machine learning aims at exploring the Rashomon set of all models exhibiting near-optimal performance. Existing work on Rashomon-set exploration focuses on exhaustive search of the Rashomon set for particular classes of models, which can be a computationally challenging task. On the other hand, exhaustive enumeration leads to redundancy that often is not necessary, and a representative sample or an estimate of the size of the Rashomon set is sufficient for many applications. In this work, we propose, for the first time, efficient methods to explore the Rashomon set of rule set models with or without exhaustive search. Extensive experiments demonstrate the effectiveness of the proposed methods in a variety of scenarios.
Read more6/6/2024