Rate-Optimal Rank Aggregation with Private Pairwise Rankings

0

Sign in to get full access
Overview
- This paper proposes a new method for rank aggregation that can achieve the optimal rate of convergence while preserving the privacy of pairwise rankings.
- The researchers develop a statistical framework and design an algorithm to solve this problem efficiently.
- The proposed approach outperforms existing methods in terms of both accuracy and privacy preservation.
Plain English Explanation
The paper tackles the problem of rank aggregation - the task of combining multiple ranked lists (e.g., search results from different engines) into a single, consolidated ranking. This is a common challenge in many applications, such as meta-search engines and recommendation systems.
A key aspect of this paper is the focus on preserving the privacy of the pairwise rankings (i.e., the comparisons between individual items) that are used as input. This is important because the pairwise rankings may contain sensitive information about user preferences or other private data.
The researchers develop a new statistical framework and algorithm that can achieve the optimal rate of convergence for rank aggregation while still protecting the privacy of the input data. This means the method can accurately combine the ranked lists into a final ranking, without compromising the confidentiality of the underlying pairwise comparisons.
The proposed approach outperforms existing rank aggregation techniques in terms of both accuracy and privacy preservation. This could have important implications for applications where both high-quality rankings and data privacy are crucial, such as in online platforms or large language models.
Technical Explanation
The paper presents a new statistical framework and algorithm for rate-optimal rank aggregation with private pairwise rankings. The key elements are:
-
Statistical Framework: The researchers develop a model for the pairwise rankings, which are assumed to be generated from an underlying true ranking through a noisy process. This allows them to analyze the statistical properties of the rank aggregation problem.
-
Algorithm Design: Based on the statistical framework, the authors design an algorithm that can optimally combine the pairwise rankings into a final ranking, while also preserving the privacy of the input data. The algorithm achieves the minimax optimal rate of convergence for this problem.
-
Theoretical Analysis: The paper provides a theoretical analysis of the proposed algorithm, proving its optimality and deriving sample complexity bounds. This ensures the method is both statistically and computationally efficient.
-
Empirical Evaluation: The researchers evaluate their approach on both synthetic and real-world datasets, comparing it to state-of-the-art rank aggregation methods. The results demonstrate the superior accuracy and privacy preservation of the proposed technique.
Critical Analysis
The paper makes a strong theoretical and empirical case for the proposed rank aggregation method. However, a few caveats and potential areas for further research are worth noting:
-
Assumptions and Limitations: The statistical framework assumes a specific generative model for the pairwise rankings, which may not always hold in practice. Further work is needed to relax these assumptions and extend the approach to more general settings.
-
Privacy Guarantees: While the paper provides strong privacy preservation guarantees, there may be practical concerns around the implementation and deployment of the algorithm in real-world systems. Investigating the robustness of the privacy protections would be an important next step.
-
Scalability: The paper focuses on the asymptotic behavior of the algorithm, but does not extensively explore its computational efficiency for large-scale problems. Evaluating the scalability of the approach would be a valuable direction for future research.
-
Applications and Impact: The potential applications of this work, such as in meta-search engines or recommendation systems, are not fully explored. Studying the real-world implications and impact of the proposed technique would be an interesting area for further investigation.
Conclusion
This paper presents a novel approach to the problem of rank aggregation that can achieve the optimal rate of convergence while preserving the privacy of the input pairwise rankings. The proposed statistical framework and algorithm demonstrate strong theoretical and empirical performance, making it a promising contribution to the field of data privacy and ranking optimization. Further research is needed to address the limitations and explore the broader implications of this work, but the authors have taken an important step forward in reconciling the competing goals of accuracy and privacy in rank aggregation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Rate-Optimal Rank Aggregation with Private Pairwise Rankings
Shirong Xu, Will Wei Sun, Guang Cheng
In various real-world scenarios, such as recommender systems and political surveys, pairwise rankings are commonly collected and utilized for rank aggregation to obtain an overall ranking of items. However, preference rankings can reveal individuals' personal preferences, underscoring the need to protect them from being released for downstream analysis. In this paper, we address the challenge of preserving privacy while ensuring the utility of rank aggregation based on pairwise rankings generated from a general comparison model. Using the randomized response mechanism to perturb raw pairwise rankings is a common privacy protection strategy used in practice. However, a critical challenge arises because the privatized rankings no longer adhere to the original model, resulting in significant bias in downstream rank aggregation tasks. Motivated by this, we propose to adaptively debiasing the rankings from the randomized response mechanism, ensuring consistent estimation of true preferences and enhancing the utility of downstream rank aggregation. Theoretically, we offer insights into the relationship between overall privacy guarantees and estimation errors from private ranking data, and establish minimax rates for estimation errors. This enables the determination of optimal privacy guarantees that balance consistency in rank aggregation with privacy protection. We also investigate convergence rates of expected ranking errors for partial and full ranking recovery, quantifying how privacy protection influences the specification of top-$K$ item sets and complete rankings. Our findings are validated through extensive simulations and a real application.
Read more8/12/2024

0
Fair Pairs: Fairness-Aware Ranking Recovery from Pairwise Comparisons
Georg Ahnert, Antonio Ferrara, Claudia Wagner
Pairwise comparisons based on human judgements are an effective method for determining rankings of items or individuals. However, as human biases perpetuate from pairwise comparisons to recovered rankings, they affect algorithmic decision making. In this paper, we introduce the problem of fairness-aware ranking recovery from pairwise comparisons. We propose a group-conditioned accuracy measure which quantifies fairness of rankings recovered from pairwise comparisons. We evaluate the impact of state-of-the-art ranking recovery algorithms and sampling approaches on accuracy and fairness of the recovered rankings, using synthetic and empirical data. Our results show that Fairness-Aware PageRank and GNNRank with FA*IR post-processing effectively mitigate existing biases in pairwise comparisons and improve the overall accuracy of recovered rankings. We highlight limitations and strengths of different approaches, and provide a Python package to facilitate replication and future work on fair ranking recovery from pairwise comparisons.
Read more8/26/2024
🏋️
0
Top-$K$ ranking with a monotone adversary
Yuepeng Yang, Antares Chen, Lorenzo Orecchia, Cong Ma
In this paper, we address the top-$K$ ranking problem with a monotone adversary. We consider the scenario where a comparison graph is randomly generated and the adversary is allowed to add arbitrary edges. The statistician's goal is then to accurately identify the top-$K$ preferred items based on pairwise comparisons derived from this semi-random comparison graph. The main contribution of this paper is to develop a weighted maximum likelihood estimator (MLE) that achieves near-optimal sample complexity, up to a $log^2(n)$ factor, where $n$ denotes the number of items under comparison. This is made possible through a combination of analytical and algorithmic innovations. On the analytical front, we provide a refined~$ell_infty$ error analysis of the weighted MLE that is more explicit and tighter than existing analyses. It relates the~$ell_infty$ error with the spectral properties of the weighted comparison graph. Motivated by this, our algorithmic innovation involves the development of an SDP-based approach to reweight the semi-random graph and meet specified spectral properties. Additionally, we propose a first-order method based on the Matrix Multiplicative Weight Update (MMWU) framework. This method efficiently solves the resulting SDP in nearly-linear time relative to the size of the semi-random comparison graph.
Read more6/21/2024
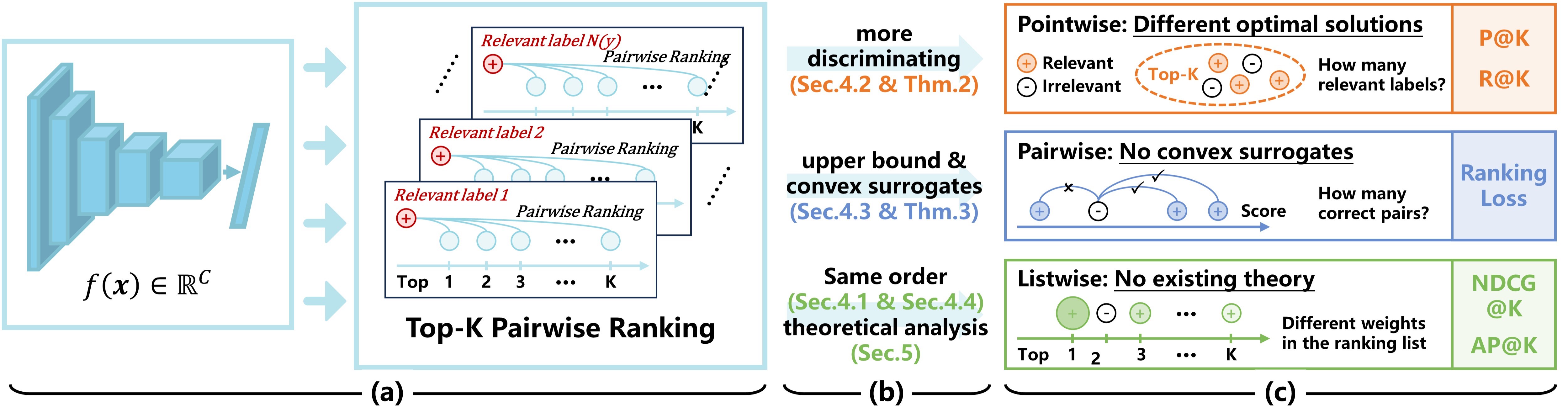
0
Top-K Pairwise Ranking: Bridging the Gap Among Ranking-Based Measures for Multi-Label Classification
Zitai Wang, Qianqian Xu, Zhiyong Yang, Peisong Wen, Yuan He, Xiaochun Cao, Qingming Huang
Multi-label ranking, which returns multiple top-ranked labels for each instance, has a wide range of applications for visual tasks. Due to its complicated setting, prior arts have proposed various measures to evaluate model performances. However, both theoretical analysis and empirical observations show that a model might perform inconsistently on different measures. To bridge this gap, this paper proposes a novel measure named Top-K Pairwise Ranking (TKPR), and a series of analyses show that TKPR is compatible with existing ranking-based measures. In light of this, we further establish an empirical surrogate risk minimization framework for TKPR. On one hand, the proposed framework enjoys convex surrogate losses with the theoretical support of Fisher consistency. On the other hand, we establish a sharp generalization bound for the proposed framework based on a novel technique named data-dependent contraction. Finally, empirical results on benchmark datasets validate the effectiveness of the proposed framework.
Read more7/10/2024