Top-K Pairwise Ranking: Bridging the Gap Among Ranking-Based Measures for Multi-Label Classification

0
Sign in to get full access
Overview
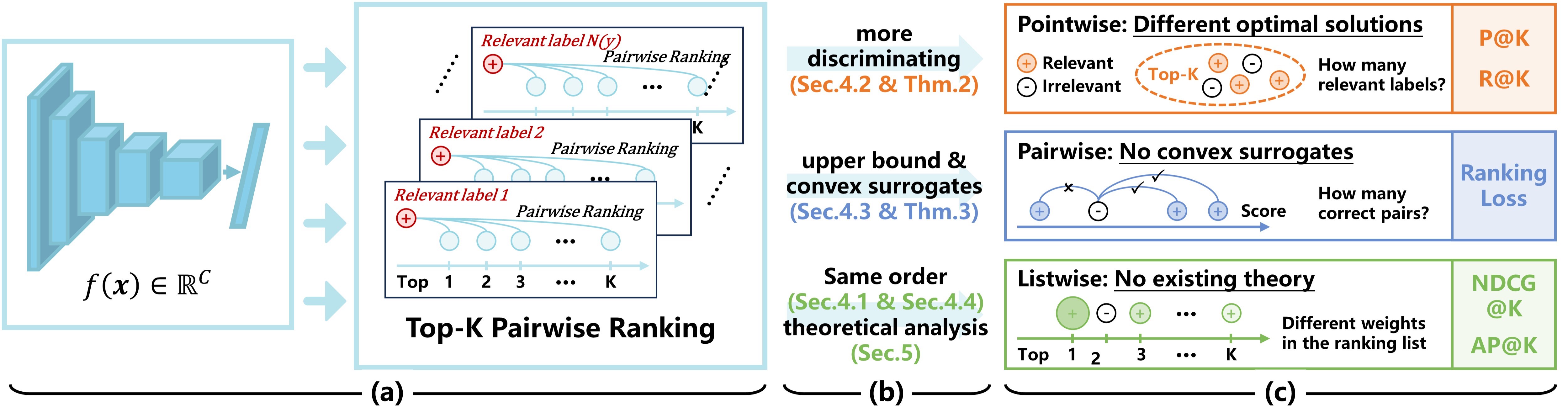
- This paper presents a novel ranking-based measure called Top-K Pairwise Ranking (TKPR) for multi-label classification tasks.
- TKPR aims to bridge the gap between existing ranking-based measures by considering both the relative ranking of relevant labels and the absolute ranking of irrelevant labels.
- The authors demonstrate the effectiveness of TKPR on several multi-label classification benchmarks, showing that it outperforms other popular ranking-based metrics.
Plain English Explanation
In machine learning, multi-label classification is a task where an input can be associated with multiple output labels. For example, an image could be labeled as containing both a "dog" and a "cat." Ranking-based metrics are commonly used to evaluate the performance of multi-label classifiers, as they capture the relative importance of the predicted labels.
The Top-K Pairwise Ranking (TKPR) metric proposed in this paper aims to bridge the gap between existing ranking-based measures. It considers both the relative ranking of the relevant labels and the absolute ranking of the irrelevant labels. This is important because a model that correctly ranks the relevant labels but places the irrelevant labels at the top may still perform poorly according to some traditional ranking-based metrics.
By incorporating both of these aspects, TKPR provides a more comprehensive evaluation of a multi-label classifier's performance. The authors show that TKPR outperforms other popular ranking-based metrics on several multi-label classification benchmarks, making it a valuable tool for researchers and practitioners in this field.
Technical Explanation
The paper introduces a new ranking-based metric called Top-K Pairwise Ranking (TKPR) for evaluating multi-label classification models. TKPR is designed to address the limitations of existing ranking-based measures, such as Ranking Loss and Normalized Discounted Cumulative Gain (NDCG).
The key idea behind TKPR is to consider both the relative ranking of relevant labels and the absolute ranking of irrelevant labels. Specifically, TKPR computes the pairwise ranking of all label pairs, where a pair is considered correctly ranked if the relevant label is ranked higher than the irrelevant label. The final TKPR score is the average of these pairwise rankings, up to the top-K ranked labels.
The authors conduct extensive experiments on several multi-label classification datasets, including PASCAL VOC, MS-COCO, and Mediamill. They compare the performance of TKPR against other ranking-based metrics, such as Ranking Loss, NDCG, and k-DPP, as well as traditional accuracy-based metrics. The results show that TKPR consistently outperforms these other measures, demonstrating its effectiveness in capturing the nuances of multi-label classification performance.
Critical Analysis
The authors acknowledge that TKPR, like other ranking-based metrics, can be sensitive to the choice of the top-K parameter. They provide guidelines for selecting an appropriate value of K based on the specific multi-label classification task and dataset. Additionally, the paper does not explore the impact of class imbalance, which is a common challenge in multi-label settings. Further research could investigate how TKPR behaves in the presence of highly skewed label distributions.
Another potential limitation is that TKPR, being a pairwise metric, may not fully capture the overall ranking of all labels for a given instance. Alternative approaches that consider the entire label ranking, such as Weighted KL Divergence, could be explored in future work to provide a more holistic evaluation of multi-label classification models.
Conclusion
This paper introduces a novel ranking-based metric called Top-K Pairwise Ranking (TKPR) for evaluating multi-label classification models. TKPR addresses the limitations of existing ranking-based measures by considering both the relative ranking of relevant labels and the absolute ranking of irrelevant labels. The authors demonstrate the effectiveness of TKPR on several multi-label classification benchmarks, where it outperforms other popular ranking-based metrics.
The TKPR metric provides a more comprehensive evaluation of multi-label classifiers, which is important for researchers and practitioners developing models in this domain. By bridging the gap among different ranking-based measures, TKPR can help drive the development of more accurate and robust multi-label classification systems, with potential applications in areas such as image recognition, text categorization, and recommendation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Top-K Pairwise Ranking: Bridging the Gap Among Ranking-Based Measures for Multi-Label Classification
Zitai Wang, Qianqian Xu, Zhiyong Yang, Peisong Wen, Yuan He, Xiaochun Cao, Qingming Huang
Multi-label ranking, which returns multiple top-ranked labels for each instance, has a wide range of applications for visual tasks. Due to its complicated setting, prior arts have proposed various measures to evaluate model performances. However, both theoretical analysis and empirical observations show that a model might perform inconsistently on different measures. To bridge this gap, this paper proposes a novel measure named Top-K Pairwise Ranking (TKPR), and a series of analyses show that TKPR is compatible with existing ranking-based measures. In light of this, we further establish an empirical surrogate risk minimization framework for TKPR. On one hand, the proposed framework enjoys convex surrogate losses with the theoretical support of Fisher consistency. On the other hand, we establish a sharp generalization bound for the proposed framework based on a novel technique named data-dependent contraction. Finally, empirical results on benchmark datasets validate the effectiveness of the proposed framework.
Read more7/10/2024

0
Rate-Optimal Rank Aggregation with Private Pairwise Rankings
Shirong Xu, Will Wei Sun, Guang Cheng
In various real-world scenarios, such as recommender systems and political surveys, pairwise rankings are commonly collected and utilized for rank aggregation to obtain an overall ranking of items. However, preference rankings can reveal individuals' personal preferences, underscoring the need to protect them from being released for downstream analysis. In this paper, we address the challenge of preserving privacy while ensuring the utility of rank aggregation based on pairwise rankings generated from a general comparison model. Using the randomized response mechanism to perturb raw pairwise rankings is a common privacy protection strategy used in practice. However, a critical challenge arises because the privatized rankings no longer adhere to the original model, resulting in significant bias in downstream rank aggregation tasks. Motivated by this, we propose to adaptively debiasing the rankings from the randomized response mechanism, ensuring consistent estimation of true preferences and enhancing the utility of downstream rank aggregation. Theoretically, we offer insights into the relationship between overall privacy guarantees and estimation errors from private ranking data, and establish minimax rates for estimation errors. This enables the determination of optimal privacy guarantees that balance consistency in rank aggregation with privacy protection. We also investigate convergence rates of expected ranking errors for partial and full ranking recovery, quantifying how privacy protection influences the specification of top-$K$ item sets and complete rankings. Our findings are validated through extensive simulations and a real application.
Read more8/12/2024

0
Pairwise Ranking Loss for Multi-Task Learning in Recommender Systems
Furkan Durmus, Hasan Saribas, Said Aldemir, Junyan Yang, Hakan Cevikalp
Multi-Task Learning (MTL) plays a crucial role in real-world advertising applications such as recommender systems, aiming to achieve robust representations while minimizing resource consumption. MTL endeavors to simultaneously optimize multiple tasks to construct a unified model serving diverse objectives. In online advertising systems, tasks like Click-Through Rate (CTR) and Conversion Rate (CVR) are often treated as MTL problems concurrently. However, it has been overlooked that a conversion ($y_{cvr}=1$) necessitates a preceding click ($y_{ctr}=1$). In other words, while certain CTR tasks are associated with corresponding conversions, others lack such associations. Moreover, the likelihood of noise is significantly higher in CTR tasks where conversions do not occur compared to those where they do, and existing methods lack the ability to differentiate between these two scenarios. In this study, exposure labels corresponding to conversions are regarded as definitive indicators, and a novel task-specific loss is introduced by calculating a textbf{p}airtextbf{wise} textbf{r}anking (PWiseR) loss between model predictions, manifesting as pairwise ranking loss, to encourage the model to rely more on them. To demonstrate the effect of the proposed loss function, experiments were conducted on different MTL and Single-Task Learning (STL) models using four distinct public MTL datasets, namely Alibaba FR, NL, US, and CCP, along with a proprietary industrial dataset. The results indicate that our proposed loss function outperforms the BCE loss function in most cases in terms of the AUC metric.
Read more6/6/2024
💬
0
Prediction-Powered Ranking of Large Language Models
Ivi Chatzi, Eleni Straitouri, Suhas Thejaswi, Manuel Gomez Rodriguez
Large language models are often ranked according to their level of alignment with human preferences -- a model is better than other models if its outputs are more frequently preferred by humans. One of the popular ways to elicit human preferences utilizes pairwise comparisons between the outputs provided by different models to the same inputs. However, since gathering pairwise comparisons by humans is costly and time-consuming, it has become a common practice to gather pairwise comparisons by a strong large language model -- a model strongly aligned with human preferences. Surprisingly, practitioners cannot currently measure the uncertainty that any mismatch between human and model preferences may introduce in the constructed rankings. In this work, we develop a statistical framework to bridge this gap. Given a (small) set of pairwise comparisons by humans and a large set of pairwise comparisons by a model, our framework provides a rank-set -- a set of possible ranking positions -- for each of the models under comparison. Moreover, it guarantees that, with a probability greater than or equal to a user-specified value, the rank-sets cover the true ranking consistent with the distribution of human pairwise preferences asymptotically. Using pairwise comparisons made by humans in the LMSYS Chatbot Arena platform and pairwise comparisons made by three strong large language models, we empirically demonstrate the effectivity of our framework and show that the rank-sets constructed using only pairwise comparisons by the strong large language models are often inconsistent with (the distribution of) human pairwise preferences.
Read more5/24/2024