Reactive Model Correction: Mitigating Harm to Task-Relevant Features via Conditional Bias Suppression

0

Sign in to get full access
Overview
- This paper proposes a novel framework called "Reactive Model Correction" (RMC) to mitigate the harm caused by biases in machine learning models.
- The key idea is to use a separate "correction model" that can detect and suppress task-irrelevant biases, while preserving the model's performance on the target task.
- The authors demonstrate the effectiveness of RMC on several benchmark datasets, showing that it can substantially reduce biases without significantly compromising model accuracy.
Plain English Explanation
Machine learning models can sometimes pick up on unintended biases in the data they are trained on, leading to unfair or harmful decisions. Minimizing Chebyshev Prototype Risk Magically Mitigates Perils and Are Bias Mitigation Techniques in Deep Learning Effective? have explored this problem in depth.
The authors of this paper propose a new approach called "Reactive Model Correction" (RMC) to address this issue. The key idea is to train a separate "correction model" that can identify and suppress task-irrelevant biases, while still allowing the main model to perform well on the target task.
Imagine you have a machine learning model that's supposed to predict someone's income based on their resume. But the model might accidentally learn to also use the person's gender or race as a factor, leading to biased and unfair predictions. RMC would try to detect and remove this unintended bias, while still allowing the model to accurately predict income based on relevant resume information.
The authors show that RMC can be effective at reducing biases across several different benchmark datasets, without significantly compromising the model's overall accuracy. This suggests RMC could be a useful tool for building more fair and ethical AI systems, as discussed in Enhancing Fairness and Performance of Machine Learning Models in Multi-objective Settings.
Technical Explanation
The Reactive Model Correction (RMC) framework consists of two main components: a "primary model" that is trained to perform the target task, and a separate "correction model" that is trained to detect and suppress task-irrelevant biases.
The primary model is trained in the usual way on the task data. The correction model is trained in parallel, using the primary model's outputs and the true labels as inputs. The correction model learns to predict a "bias score" that indicates how much each input example deviates from the target task.
During inference, the primary model's outputs are passed through the correction model, which adjusts the outputs to suppress the predicted bias. This "corrected" output is then used as the final prediction.
The authors evaluate RMC on several benchmark datasets, including Robust Data Pruning: Uncovering and Overcoming Implicit Bias and RadeEdit: Stress Testing Biomedical Vision Models via Radiology Edits. They show that RMC can significantly reduce various bias metrics, such as demographic parity and equal opportunity, without substantially impacting the primary model's accuracy.
Critical Analysis
The authors acknowledge several limitations of their work. First, RMC relies on the assumption that task-irrelevant biases can be accurately detected by the correction model. If the correction model fails to identify relevant biases, it may inadvertently suppress important task-relevant features.
Additionally, the authors only evaluate RMC on a limited set of benchmark datasets. It's unclear how well the approach would generalize to more complex, real-world applications with richer sources of potential bias.
Another concern is the added computational cost of training and running the separate correction model. This may limit the practical deployment of RMC, especially in resource-constrained settings.
Overall, the Reactive Model Correction framework represents an interesting and promising approach to mitigating harmful biases in machine learning. However, further research is needed to fully understand its strengths, weaknesses, and practical applicability across a wider range of domains.
Conclusion
This paper introduces Reactive Model Correction (RMC), a novel framework for mitigating the harm caused by biases in machine learning models. RMC uses a separate "correction model" to detect and suppress task-irrelevant biases, while preserving the primary model's performance on the target task.
The authors demonstrate the effectiveness of RMC on several benchmark datasets, showing that it can substantially reduce biases without significantly compromising model accuracy. This suggests RMC could be a valuable tool for building more fair and ethical AI systems, as discussed in Enhancing Fairness and Performance of Machine Learning Models in Multi-objective Settings.
While RMC has promising potential, the authors acknowledge several limitations, such as the reliance on accurate bias detection by the correction model and the added computational cost. Further research is needed to fully understand the strengths, weaknesses, and practical applicability of this approach across a wider range of real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Reactive Model Correction: Mitigating Harm to Task-Relevant Features via Conditional Bias Suppression
Dilyara Bareeva, Maximilian Dreyer, Frederik Pahde, Wojciech Samek, Sebastian Lapuschkin
Deep Neural Networks are prone to learning and relying on spurious correlations in the training data, which, for high-risk applications, can have fatal consequences. Various approaches to suppress model reliance on harmful features have been proposed that can be applied post-hoc without additional training. Whereas those methods can be applied with efficiency, they also tend to harm model performance by globally shifting the distribution of latent features. To mitigate unintended overcorrection of model behavior, we propose a reactive approach conditioned on model-derived knowledge and eXplainable Artificial Intelligence (XAI) insights. While the reactive approach can be applied to many post-hoc methods, we demonstrate the incorporation of reactivity in particular for P-ClArC (Projective Class Artifact Compensation), introducing a new method called R-ClArC (Reactive Class Artifact Compensation). Through rigorous experiments in controlled settings (FunnyBirds) and with a real-world dataset (ISIC2019), we show that introducing reactivity can minimize the detrimental effect of the applied correction while simultaneously ensuring low reliance on spurious features.
Read more4/16/2024
📊
0
Nuisances via Negativa: Adjusting for Spurious Correlations via Data Augmentation
Aahlad Puli, Nitish Joshi, Yoav Wald, He He, Rajesh Ranganath
In prediction tasks, there exist features that are related to the label in the same way across different settings for that task; these are semantic features or semantics. Features with varying relationships to the label are nuisances. For example, in detecting cows from natural images, the shape of the head is semantic but because images of cows often have grass backgrounds but not always, the background is a nuisance. Models that exploit nuisance-label relationships face performance degradation when these relationships change. Building models robust to such changes requires additional knowledge beyond samples of the features and labels. For example, existing work uses annotations of nuisances or assumes ERM-trained models depend on nuisances. Approaches to integrate new kinds of additional knowledge enlarge the settings where robust models can be built. We develop an approach to use knowledge about the semantics by corrupting them in data, and then using the corrupted data to produce models which identify correlations between nuisances and the label. Once these correlations are identified, they can be used to adjust for where nuisances drive predictions. We study semantic corruptions in powering different spurious-correlation avoiding methods on multiple out-of-distribution (OOD) tasks like classifying waterbirds, natural language inference (NLI), and detecting cardiomegaly in chest X-rays.
Read more7/4/2024
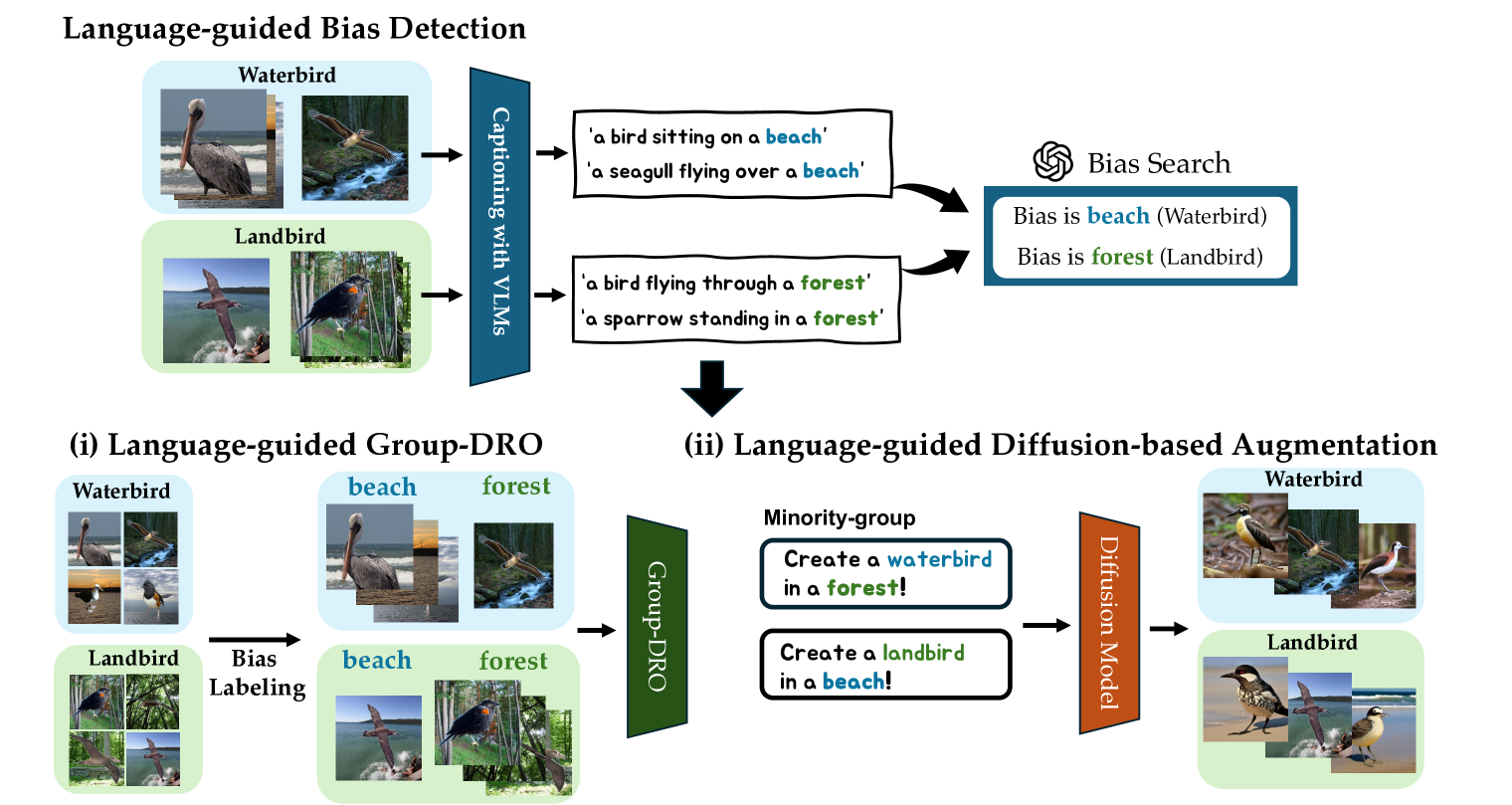
0
Language-guided Detection and Mitigation of Unknown Dataset Bias
Zaiying Zhao, Soichiro Kumano, Toshihiko Yamasaki
Dataset bias is a significant problem in training fair classifiers. When attributes unrelated to classification exhibit strong biases towards certain classes, classifiers trained on such dataset may overfit to these bias attributes, substantially reducing the accuracy for minority groups. Mitigation techniques can be categorized according to the availability of bias information (ie, prior knowledge). Although scenarios with unknown biases are better suited for real-world settings, previous work in this field often suffers from a lack of interpretability regarding biases and lower performance. In this study, we propose a framework to identify potential biases as keywords without prior knowledge based on the partial occurrence in the captions. We further propose two debiasing methods: (a) handing over to an existing debiasing approach which requires prior knowledge by assigning pseudo-labels, and (b) employing data augmentation via text-to-image generative models, using acquired bias keywords as prompts. Despite its simplicity, experimental results show that our framework not only outperforms existing methods without prior knowledge, but also is even comparable with a method that assumes prior knowledge.
Read more6/6/2024
🌐
0
Towards objective and systematic evaluation of bias in artificial intelligence for medical imaging
Emma A. M. Stanley, Raissa Souza, Anthony Winder, Vedant Gulve, Kimberly Amador, Matthias Wilms, Nils D. Forkert
Artificial intelligence (AI) models trained using medical images for clinical tasks often exhibit bias in the form of disparities in performance between subgroups. Since not all sources of biases in real-world medical imaging data are easily identifiable, it is challenging to comprehensively assess how those biases are encoded in models, and how capable bias mitigation methods are at ameliorating performance disparities. In this article, we introduce a novel analysis framework for systematically and objectively investigating the impact of biases in medical images on AI models. We developed and tested this framework for conducting controlled in silico trials to assess bias in medical imaging AI using a tool for generating synthetic magnetic resonance images with known disease effects and sources of bias. The feasibility is showcased by using three counterfactual bias scenarios to measure the impact of simulated bias effects on a convolutional neural network (CNN) classifier and the efficacy of three bias mitigation strategies. The analysis revealed that the simulated biases resulted in expected subgroup performance disparities when the CNN was trained on the synthetic datasets. Moreover, reweighing was identified as the most successful bias mitigation strategy for this setup, and we demonstrated how explainable AI methods can aid in investigating the manifestation of bias in the model using this framework. Developing fair AI models is a considerable challenge given that many and often unknown sources of biases can be present in medical imaging datasets. In this work, we present a novel methodology to objectively study the impact of biases and mitigation strategies on deep learning pipelines, which can support the development of clinical AI that is robust and responsible.
Read more7/2/2024