Reading Subtext: Evaluating Large Language Models on Short Story Summarization with Writers

0

Sign in to get full access
Overview
- This paper evaluates the performance of large language models on summarizing short stories, with a focus on capturing the subtext and underlying themes.
- The researchers used a dataset of short stories written by authors who provided content warnings about potentially disturbing or shocking details in their work.
- The paper compares the performance of different language models on summarizing these stories and discusses the models' ability to understand and convey the stories' deeper meaning.
Plain English Explanation
This research paper examines how well large language models can summarize short stories, particularly in capturing the underlying themes and meaning beyond the surface-level plot. The researchers used a dataset of short stories that came with content warnings about potentially upsetting or disturbing elements, to see how the language models would handle that type of nuanced, complex material.
The researchers compared different summarization methods to evaluate the language models' performance. They looked at factors like how well the summaries reflected the stories' deeper meaning and themes, not just the basic facts. This is an important capability, as being able to understand and convey subtext is a key part of summarizing creative writing effectively.
The results provide insights into the current limitations and strengths of large language models when dealing with more abstract, emotionally-charged content. It suggests areas where further research on text summarization could help improve models' ability to capture the full meaning and nuance of written works.
Technical Explanation
The paper evaluates the performance of large language models on the task of summarizing short stories, with a focus on their ability to capture the subtext and underlying themes. The researchers used a dataset of short stories that came with content warnings from the authors about potentially disturbing or shocking details in the work.
The experiment design involved comparing the summaries produced by different language models, including LLaMA, GPT-3, and T5, on this dataset of short stories. The researchers assessed the summaries based on how well they reflected the deeper meaning and thematic content of the stories, rather than just the surface-level plot points.
The paper provides insights into the current strengths and limitations of large language models when it comes to understanding and conveying the subtext and emotional nuance present in creative writing. The results suggest areas where further advancements in text summarization techniques could help improve models' ability to capture the full richness and complexity of written works.
Critical Analysis
The paper acknowledges some key limitations in its approach, such as the relatively small size of the short story dataset and the subjective nature of evaluating the quality of summaries for capturing subtext. The researchers also note that the content warnings provided by the authors may not fully capture the range of potentially disturbing elements in the stories.
Additionally, while the paper provides a valuable comparison of different language models' performance, it does not delve deeply into the specific architectural or training differences that may account for their varying abilities to handle this type of summarization task. Further research could explore these model-level factors in more detail.
Overall, the study represents an important step in understanding the capabilities and shortcomings of large language models when it comes to summarizing creative, emotionally-charged content. The findings suggest that while these models have made significant progress, there is still room for improvement in their ability to truly capture the subtext and nuanced meaning present in short stories and similar literary works.
Conclusion
This research paper examines the performance of large language models on the task of summarizing short stories, with a particular focus on their ability to convey the underlying themes and subtext present in the original works. The use of a dataset containing stories with content warnings highlights the models' strengths and limitations when dealing with more complex, emotionally-charged material.
The study's findings provide valuable insights into the current state of language model technology and suggest areas for future research to further improve summarization capabilities, especially when it comes to capturing the full richness and nuance of creative writing. As large language models continue to advance, this work underscores the importance of evaluating their performance on a diverse range of tasks and content types to ensure they can effectively support a wide range of applications and user needs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Reading Subtext: Evaluating Large Language Models on Short Story Summarization with Writers
Melanie Subbiah, Sean Zhang, Lydia B. Chilton, Kathleen McKeown
We evaluate recent Large Language Models (LLMs) on the challenging task of summarizing short stories, which can be lengthy, and include nuanced subtext or scrambled timelines. Importantly, we work directly with authors to ensure that the stories have not been shared online (and therefore are unseen by the models), and to obtain informed evaluations of summary quality using judgments from the authors themselves. Through quantitative and qualitative analysis grounded in narrative theory, we compare GPT-4, Claude-2.1, and LLama-2-70B. We find that all three models make faithfulness mistakes in over 50% of summaries and struggle with specificity and interpretation of difficult subtext. We additionally demonstrate that LLM ratings and other automatic metrics for summary quality do not correlate well with the quality ratings from the writers.
Read more7/15/2024
💬
0
Large Language Models as Evaluators for Scientific Synthesis
Julia Evans, Jennifer D'Souza, Soren Auer
Our study explores how well the state-of-the-art Large Language Models (LLMs), like GPT-4 and Mistral, can assess the quality of scientific summaries or, more fittingly, scientific syntheses, comparing their evaluations to those of human annotators. We used a dataset of 100 research questions and their syntheses made by GPT-4 from abstracts of five related papers, checked against human quality ratings. The study evaluates both the closed-source GPT-4 and the open-source Mistral model's ability to rate these summaries and provide reasons for their judgments. Preliminary results show that LLMs can offer logical explanations that somewhat match the quality ratings, yet a deeper statistical analysis shows a weak correlation between LLM and human ratings, suggesting the potential and current limitations of LLMs in scientific synthesis evaluation.
Read more7/4/2024

0
A Comparative Study of Quality Evaluation Methods for Text Summarization
Huyen Nguyen, Haihua Chen, Lavanya Pobbathi, Junhua Ding
Evaluating text summarization has been a challenging task in natural language processing (NLP). Automatic metrics which heavily rely on reference summaries are not suitable in many situations, while human evaluation is time-consuming and labor-intensive. To bridge this gap, this paper proposes a novel method based on large language models (LLMs) for evaluating text summarization. We also conducts a comparative study on eight automatic metrics, human evaluation, and our proposed LLM-based method. Seven different types of state-of-the-art (SOTA) summarization models were evaluated. We perform extensive experiments and analysis on datasets with patent documents. Our results show that LLMs evaluation aligns closely with human evaluation, while widely-used automatic metrics such as ROUGE-2, BERTScore, and SummaC do not and also lack consistency. Based on the empirical comparison, we propose a LLM-powered framework for automatically evaluating and improving text summarization, which is beneficial and could attract wide attention among the community.
Read more7/2/2024
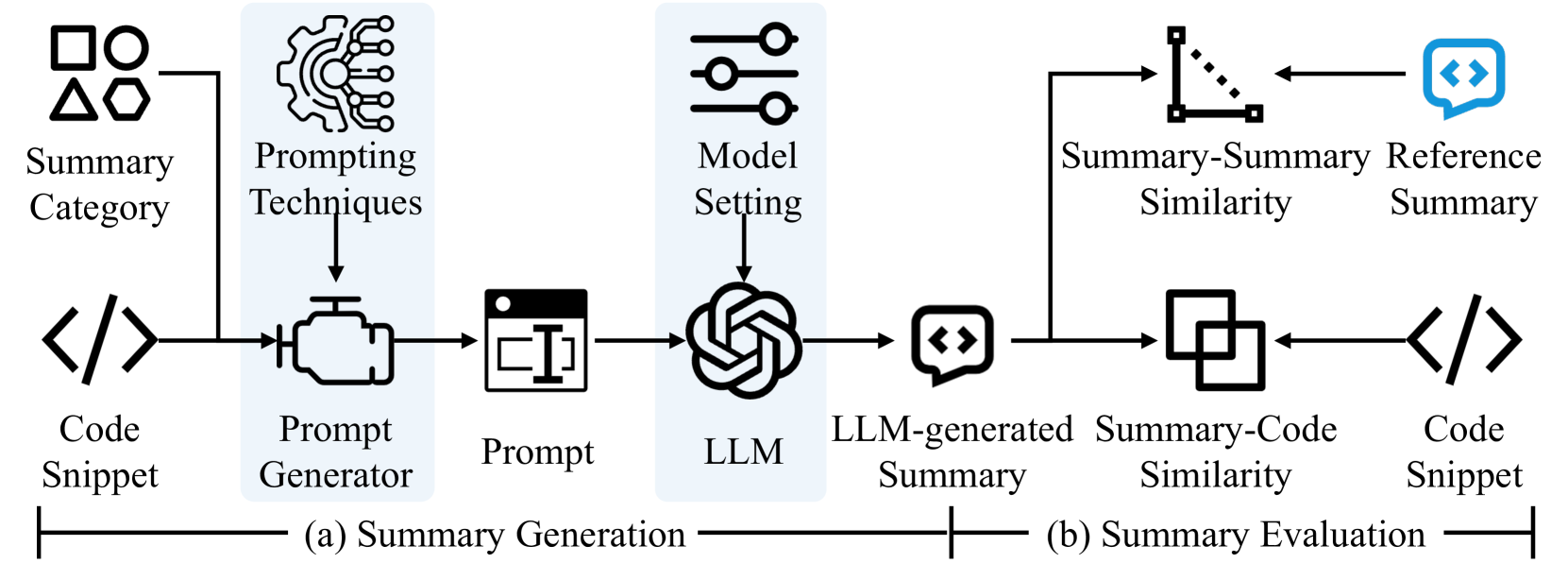
0
Source Code Summarization in the Era of Large Language Models
Weisong Sun, Yun Miao, Yuekang Li, Hongyu Zhang, Chunrong Fang, Yi Liu, Gelei Deng, Yang Liu, Zhenyu Chen
To support software developers in understanding and maintaining programs, various automatic (source) code summarization techniques have been proposed to generate a concise natural language summary (i.e., comment) for a given code snippet. Recently, the emergence of large language models (LLMs) has led to a great boost in the performance of code-related tasks. In this paper, we undertake a systematic and comprehensive study on code summarization in the era of LLMs, which covers multiple aspects involved in the workflow of LLM-based code summarization. Specifically, we begin by examining prevalent automated evaluation methods for assessing the quality of summaries generated by LLMs and find that the results of the GPT-4 evaluation method are most closely aligned with human evaluation. Then, we explore the effectiveness of five prompting techniques (zero-shot, few-shot, chain-of-thought, critique, and expert) in adapting LLMs to code summarization tasks. Contrary to expectations, advanced prompting techniques may not outperform simple zero-shot prompting. Next, we investigate the impact of LLMs' model settings (including top_p and temperature parameters) on the quality of generated summaries. We find the impact of the two parameters on summary quality varies by the base LLM and programming language, but their impacts are similar. Moreover, we canvass LLMs' abilities to summarize code snippets in distinct types of programming languages. The results reveal that LLMs perform suboptimally when summarizing code written in logic programming languages compared to other language types. Finally, we unexpectedly find that CodeLlama-Instruct with 7B parameters can outperform advanced GPT-4 in generating summaries describing code implementation details and asserting code properties. We hope that our findings can provide a comprehensive understanding of code summarization in the era of LLMs.
Read more7/12/2024