README: Bridging Medical Jargon and Lay Understanding for Patient Education through Data-Centric NLP
2312.15561
0
0
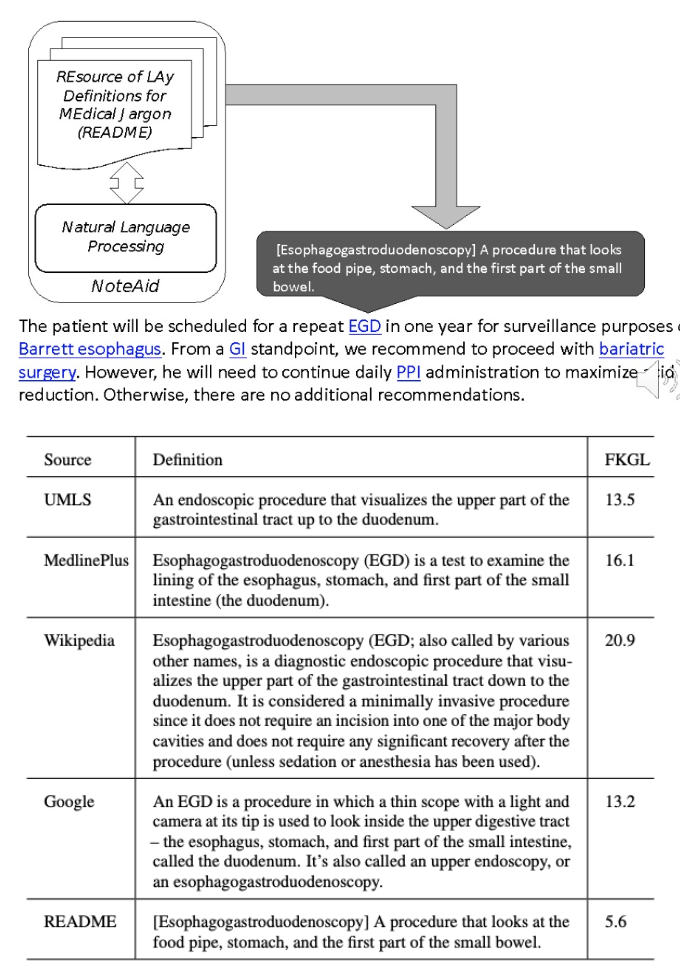
Abstract
The advancement in healthcare has shifted focus toward patient-centric approaches, particularly in self-care and patient education, facilitated by access to Electronic Health Records (EHR). However, medical jargon in EHRs poses significant challenges in patient comprehension. To address this, we introduce a new task of automatically generating lay definitions, aiming to simplify complex medical terms into patient-friendly lay language. We first created the README dataset, an extensive collection of over 50,000 unique (medical term, lay definition) pairs and 300,000 mentions, each offering context-aware lay definitions manually annotated by domain experts. We have also engineered a data-centric Human-AI pipeline that synergizes data filtering, augmentation, and selection to improve data quality. We then used README as the training data for models and leveraged a Retrieval-Augmented Generation method to reduce hallucinations and improve the quality of model outputs. Our extensive automatic and human evaluations demonstrate that open-source mobile-friendly models, when fine-tuned with high-quality data, are capable of matching or even surpassing the performance of state-of-the-art closed-source large language models like ChatGPT. This research represents a significant stride in closing the knowledge gap in patient education and advancing patient-centric healthcare solutions.
Create account to get full access
Introduction
This paper explores the challenge of bridging the gap between medical jargon and lay understanding to improve patient education. The authors recognize that the technical language used in healthcare can be difficult for the general public to comprehend, hindering effective communication and patient engagement. The goal of this research is to develop natural language processing (NLP) techniques that can translate complex medical concepts into more accessible, plain language.
Related Work
The paper situates this work within the broader context of efforts to enhance patient-provider communication and improve health literacy. It cites previous research on developing healthcare language model embedding spaces [1], using multimodal data like voice recordings to capture patient-provider interactions [2], and building generative models to retrieve relevant electronic health record (EHR) information [3]. The authors also highlight work on designing interpretable machine learning systems to foster trust [4] and studying clinical named entity recognition using large language models [5].
Problem Statement
The core challenge addressed in this paper is how to effectively bridge the divide between medical terminology and lay understanding to support patient education. Patients often struggle to comprehend the technical language used by healthcare providers, which can lead to confusion, non-adherence, and poorer health outcomes. The authors aim to develop NLP techniques that can automatically translate complex medical concepts into more accessible, plain language explanations.
Overview
- The paper focuses on bridging the gap between medical jargon and lay understanding to improve patient education.
- It explores the use of natural language processing (NLP) techniques to translate complex medical concepts into plain language.
- The research seeks to enhance patient-provider communication and health literacy.
Plain English Explanation
This research is about finding ways to make medical information easier for patients to understand. Doctors and nurses often use a lot of big, complicated words that can be confusing for regular people. This can make it hard for patients to know what's going on with their health and how to take care of themselves. The researchers in this paper are trying to develop special computer programs that can take the complex medical terms and translate them into simpler, everyday language.
The goal is to improve communication between healthcare providers and their patients. If patients can better understand their medical conditions and treatments, they are more likely to follow the advice of their doctors and nurses. This could lead to better health outcomes for patients. The researchers are building on previous work in areas like developing healthcare language model embedding spaces, using multimodal data like voice recordings to capture patient-provider interactions, and building generative models to retrieve relevant electronic health record (EHR) information. The researchers also look at work on designing interpretable machine learning systems to foster trust and studying clinical named entity recognition using large language models.
Technical Explanation
The paper presents a data-centric approach to bridging the gap between medical jargon and lay understanding for patient education. The authors develop NLP techniques that can automatically identify complex medical terms in text and generate plain language explanations.
The key elements of the research include:
-
Dataset Curation: The researchers curated a dataset of medical texts paired with corresponding plain language explanations. This involved collecting materials from reputable sources like patient education websites and manually annotating the complex medical terms and their lay definitions.
-
Model Architecture: The authors designed a neural network-based model that takes medical text as input and outputs plain language explanations. This architecture includes components for medical term recognition, concept modeling, and text generation.
-
Evaluation: The researchers evaluated their model's performance on held-out test data, assessing both the accuracy of the medical term identification and the quality of the generated plain language explanations. They also conducted user studies to assess the model's usefulness for patient comprehension.
The insights from this work demonstrate the potential of data-centric NLP approaches to bridge the gap between technical medical knowledge and lay understanding. By leveraging large datasets of expert-curated medical-lay term pairs, the model can learn to effectively translate complex concepts into more accessible language.
Critical Analysis
The paper provides a thorough and well-designed approach to the challenge of improving patient education through NLP techniques. The dataset curation efforts and the model architecture seem well-thought-out, and the evaluation methods are robust.
However, the paper does acknowledge some limitations and areas for further research. For example, the dataset may not capture the full breadth of medical terminology and lay explanations, and the model's performance may vary across different medical domains or patient demographics. Additionally, the authors note that generating truly contextual and personalized plain language explanations remains an open challenge.
Further research could explore ways to build more dynamic, patient-tailored language models, perhaps by incorporating additional data sources like patient-provider dialogues or individual health literacy assessments. Exploring multimodal approaches that leverage voice, images, or interactive visualizations could also enhance the accessibility and effectiveness of patient education materials.
Conclusion
This paper presents an important step towards bridging the divide between medical jargon and lay understanding to improve patient education. By developing NLP techniques that can automatically translate complex medical concepts into more accessible language, the researchers aim to empower patients with the knowledge and tools to better manage their health.
The insights and methods from this work have the potential to significantly enhance patient-provider communication, health literacy, and ultimately, patient outcomes. As healthcare systems increasingly focus on patient-centered care, this type of research will become increasingly crucial in ensuring that all patients can fully understand and engage with the information they need to make informed decisions about their health.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

New!EHRmonize: A Framework for Medical Concept Abstraction from Electronic Health Records using Large Language Models
Jo~ao Matos, Jack Gallifant, Jian Pei, A. Ian Wong
0
0
Electronic health records (EHRs) contain vast amounts of complex data, but harmonizing and processing this information remains a challenging and costly task requiring significant clinical expertise. While large language models (LLMs) have shown promise in various healthcare applications, their potential for abstracting medical concepts from EHRs remains largely unexplored. We introduce EHRmonize, a framework leveraging LLMs to abstract medical concepts from EHR data. Our study uses medication data from two real-world EHR databases to evaluate five LLMs on two free-text extraction and six binary classification tasks across various prompting strategies. GPT-4o's with 10-shot prompting achieved the highest performance in all tasks, accompanied by Claude-3.5-Sonnet in a subset of tasks. GPT-4o achieved an accuracy of 97% in identifying generic route names, 82% for generic drug names, and 100% in performing binary classification of antibiotics. While EHRmonize significantly enhances efficiency, reducing annotation time by an estimated 60%, we emphasize that clinician oversight remains essential. Our framework, available as a Python package, offers a promising tool to assist clinicians in EHR data abstraction, potentially accelerating healthcare research and improving data harmonization processes.
7/2/2024
Towards Adapting Open-Source Large Language Models for Expert-Level Clinical Note Generation
Hanyin Wang, Chufan Gao, Bolun Liu, Qiping Xu, Guleid Hussein, Mohamad El Labban, Kingsley Iheasirim, Hariprasad Korsapati, Chuck Outcalt, Jimeng Sun
0
0
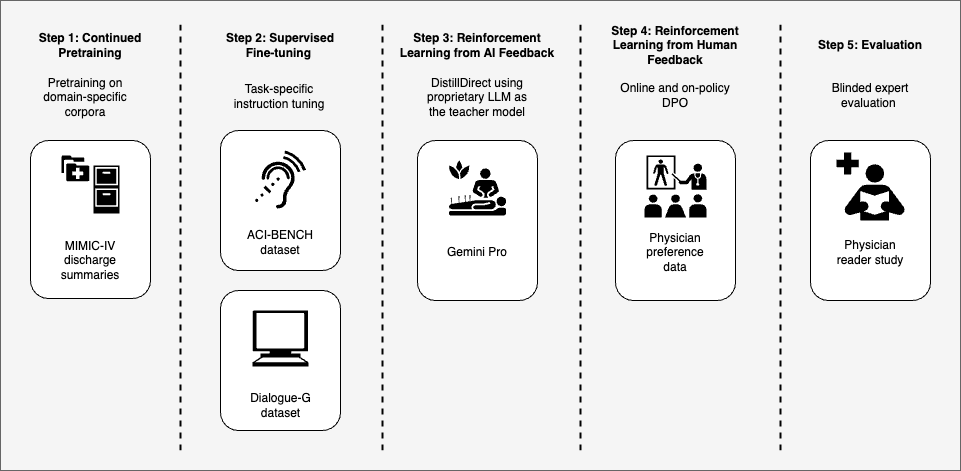
Proprietary Large Language Models (LLMs) such as GPT-4 and Gemini have demonstrated promising capabilities in clinical text summarization tasks. However, due to patient data privacy concerns and computational costs, many healthcare providers prefer using small, locally-hosted models over external generic LLMs. This study presents a comprehensive domain- and task-specific adaptation process for the open-source LLaMA-2 13 billion parameter model, enabling it to generate high-quality clinical notes from outpatient patient-doctor dialogues. Our process incorporates continued pre-training, supervised fine-tuning, and reinforcement learning from both AI and human feedback. We introduced a new approach, DistillDirect, for performing on-policy reinforcement learning with Gemini 1.0 Pro as the teacher model. Our resulting model, LLaMA-Clinic, can generate clinical notes comparable in quality to those authored by physicians. In a blinded physician reader study, the majority (90.4%) of individual evaluations rated the notes generated by LLaMA-Clinic as acceptable or higher across all three criteria: real-world readiness, completeness, and accuracy. In the more challenging Assessment and Plan section, LLaMA-Clinic scored higher (4.2/5) in real-world readiness than physician-authored notes (4.1/5). Our cost analysis for inference shows that our LLaMA-Clinic model achieves a 3.75-fold cost reduction compared to an external generic LLM service. Additionally, we highlight key considerations for future clinical note-generation tasks, emphasizing the importance of pre-defining a best-practice note format, rather than relying on LLMs to determine this for clinical practice. We have made our newly created synthetic clinic dialogue-note dataset and the physician feedback dataset publicly available to foster future research.
6/11/2024
💬
Benchmarking Large Language Models on Communicative Medical Coaching: a Novel System and Dataset
Hengguan Huang, Songtao Wang, Hongfu Liu, Hao Wang, Ye Wang
0
0
Traditional applications of natural language processing (NLP) in healthcare have predominantly focused on patient-centered services, enhancing patient interactions and care delivery, such as through medical dialogue systems. However, the potential of NLP to benefit inexperienced doctors, particularly in areas such as communicative medical coaching, remains largely unexplored. We introduce ChatCoach, a human-AI cooperative framework designed to assist medical learners in practicing their communication skills during patient consultations. ChatCoach (Our data and code are available online: https://github.com/zerowst/Chatcoach)differentiates itself from conventional dialogue systems by offering a simulated environment where medical learners can practice dialogues with a patient agent, while a coach agent provides immediate, structured feedback. This is facilitated by our proposed Generalized Chain-of-Thought (GCoT) approach, which fosters the generation of structured feedback and enhances the utilization of external knowledge sources. Additionally, we have developed a dataset specifically for evaluating Large Language Models (LLMs) within the ChatCoach framework on communicative medical coaching tasks. Our empirical results validate the effectiveness of ChatCoach.
6/11/2024

MediFact at MEDIQA-CORR 2024: Why AI Needs a Human Touch
Nadia Saeed
0
0
Accurate representation of medical information is crucial for patient safety, yet artificial intelligence (AI) systems, such as Large Language Models (LLMs), encounter challenges in error-free clinical text interpretation. This paper presents a novel approach submitted to the MEDIQA-CORR 2024 shared task (Ben Abacha et al., 2024a), focusing on the automatic correction of single-word errors in clinical notes. Unlike LLMs that rely on extensive generic data, our method emphasizes extracting contextually relevant information from available clinical text data. Leveraging an ensemble of extractive and abstractive question-answering approaches, we construct a supervised learning framework with domain-specific feature engineering. Our methodology incorporates domain expertise to enhance error correction accuracy. By integrating domain expertise and prioritizing meaningful information extraction, our approach underscores the significance of a human-centric strategy in adapting AI for healthcare.
4/30/2024