Recent advances in interpretable machine learning using structure-based protein representations

0

Sign in to get full access
Overview
- Summarizes recent advances in using structure-based protein representations for interpretable machine learning
- Explores how these approaches can improve protein functionality prediction, protein-protein interaction modeling, and protein structure prediction
- Highlights the importance of incorporating structural information to enhance the interpretability of ML models in structural biology
Plain English Explanation
Proteins are the building blocks of life, performing essential functions in our bodies. Understanding how proteins work is crucial for developing new drugs and treatments. However, predicting a protein's function or how it interacts with other proteins is a complex challenge.
Machine learning (ML) models have shown promise in tackling these problems, but they can often be "black boxes" - their inner workings are difficult to interpret. This makes it hard to understand why the models make certain predictions, limiting their real-world application.
The research covered in this paper explores how incorporating information about a protein's 3D structure can make ML models more interpretable. By representing proteins based on their structural features, rather than just their sequence of amino acids, these models can provide insights into the physical and chemical mechanisms driving protein behavior.
This approach allows the models to identify specific regions or interactions within a protein that are most important for predicting its function or interactions. Researchers can then analyze these "important features" to better understand the underlying biology.
Overall, this work highlights how blending structural biology and interpretable ML can lead to more trustworthy and impactful applications in areas like drug discovery and personalized medicine. By making the "black box" more transparent, these techniques could accelerate scientific understanding and innovation.
Technical Explanation
The paper reviews recent advances in using structure-based protein representations to develop interpretable machine learning (ML) models. These approaches aim to leverage information about a protein's 3D structure, in addition to its sequence of amino acids, to enhance the interpretability of ML models for tasks like protein functionality prediction, protein-protein interaction modeling, and protein structure prediction.
One key technique is the use of graph neural networks (GNNs) to encode a protein's structural features. GNNs can capture the spatial relationships between amino acids, as well as physicochemical properties like hydrogen bonding and electrostatic interactions. By focusing the model on these structural insights, rather than just the linear sequence, the resulting predictions become more interpretable.
Other methods explore ways to learn robust structural representations through self-supervised learning on large protein structure datasets. This allows the models to extract general principles about protein folding and function, which can then be applied to specific prediction tasks.
The paper also discusses how these structure-based representations can be combined with language models trained on protein sequences. This cross-modal approach leverages complementary information to build even more powerful and interpretable ML systems for structural biology.
Overall, the research highlights the value of incorporating structural knowledge to enhance the transparency and trustworthiness of ML models in this domain. By making the "black box" more interpretable, these techniques can accelerate scientific discovery and enable more reliable applications in areas like drug design and personalized medicine.
Critical Analysis
The paper provides a thorough review of recent advancements in the use of structure-based protein representations for interpretable machine learning. The authors effectively demonstrate how incorporating structural information, rather than relying solely on sequence data, can lead to more interpretable and insightful models for predicting protein function, interactions, and structure.
One potential limitation discussed is the availability and quality of protein structure data, which can be scarce or incomplete, especially for less-studied proteins. The authors suggest that continued improvements in experimental and computational protein structure prediction methods will be crucial to expand the applicability of these structure-based ML approaches.
Additionally, while the paper highlights the benefits of interpretability, it does not extensively explore potential challenges or pitfalls in translating these research advances into real-world applications. Factors such as model robustness, scalability, and integration with existing workflows may require further investigation to ensure the seamless adoption of these techniques in fields like drug discovery and personalized medicine.
Overall, the paper provides a compelling case for the value of blending structural biology and interpretable machine learning. By making the "black box" more transparent, these approaches have the potential to accelerate scientific understanding and enable more trustworthy and impactful applications in the life sciences.
Conclusion
This review paper highlights recent advancements in the use of structure-based protein representations to develop more interpretable machine learning models for tasks in structural biology. By encoding information about a protein's 3D structure, rather than just its linear sequence, these approaches can provide insights into the physical and chemical mechanisms driving protein function and interactions.
The incorporation of structural knowledge, through techniques like graph neural networks and cross-modal learning, has been shown to enhance the transparency and trustworthiness of ML models in areas such as protein functionality prediction, protein-protein interaction modeling, and protein structure prediction. This improved interpretability can accelerate scientific discovery and enable more reliable applications in fields like drug design and personalized medicine.
As the availability and quality of protein structure data continue to improve, the continued development of these structure-based, interpretable ML techniques holds great promise for advancing our understanding of the fundamental mechanisms of life and driving innovation in the life sciences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Recent advances in interpretable machine learning using structure-based protein representations
Luiz Felipe Vecchietti, Minji Lee, Begench Hangeldiyev, Hyunkyu Jung, Hahnbeom Park, Tae-Kyun Kim, Meeyoung Cha, Ho Min Kim
Recent advancements in machine learning (ML) are transforming the field of structural biology. For example, AlphaFold, a groundbreaking neural network for protein structure prediction, has been widely adopted by researchers. The availability of easy-to-use interfaces and interpretable outcomes from the neural network architecture, such as the confidence scores used to color the predicted structures, have made AlphaFold accessible even to non-ML experts. In this paper, we present various methods for representing protein 3D structures from low- to high-resolution, and show how interpretable ML methods can support tasks such as predicting protein structures, protein function, and protein-protein interactions. This survey also emphasizes the significance of interpreting and visualizing ML-based inference for structure-based protein representations that enhance interpretability and knowledge discovery. Developing such interpretable approaches promises to further accelerate fields including drug development and protein design.
Read more9/27/2024
0
Learning the Language of Protein Structure
Benoit Gaujac, J'er'emie Don`a, Liviu Copoiu, Timothy Atkinson, Thomas Pierrot, Thomas D. Barrett
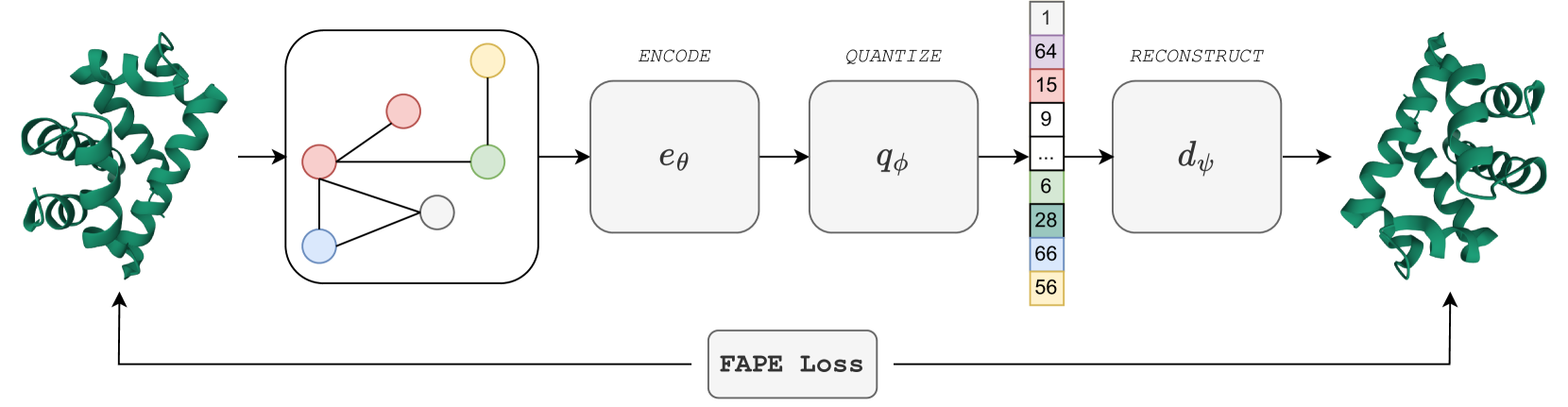
Representation learning and emph{de novo} generation of proteins are pivotal computational biology tasks. Whilst natural language processing (NLP) techniques have proven highly effective for protein sequence modelling, structure modelling presents a complex challenge, primarily due to its continuous and three-dimensional nature. Motivated by this discrepancy, we introduce an approach using a vector-quantized autoencoder that effectively tokenizes protein structures into discrete representations. This method transforms the continuous, complex space of protein structures into a manageable, discrete format with a codebook ranging from 4096 to 64000 tokens, achieving high-fidelity reconstructions with backbone root mean square deviations (RMSD) of approximately 1-5 AA. To demonstrate the efficacy of our learned representations, we show that a simple GPT model trained on our codebooks can generate novel, diverse, and designable protein structures. Our approach not only provides representations of protein structure, but also mitigates the challenges of disparate modal representations and sets a foundation for seamless, multi-modal integration, enhancing the capabilities of computational methods in protein design.
Read more5/28/2024
0
Protein Representation Learning by Capturing Protein Sequence-Structure-Function Relationship
Eunji Ko, Seul Lee, Minseon Kim, Dongki Kim
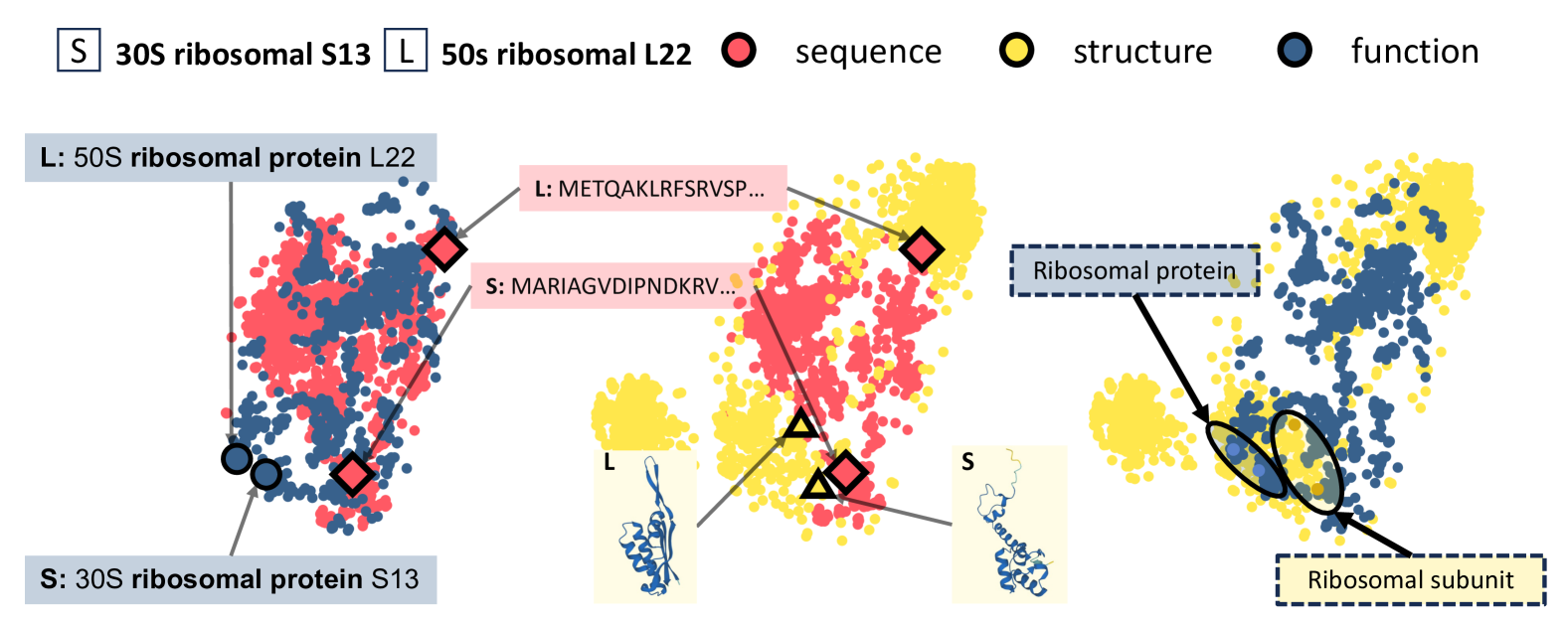
The goal of protein representation learning is to extract knowledge from protein databases that can be applied to various protein-related downstream tasks. Although protein sequence, structure, and function are the three key modalities for a comprehensive understanding of proteins, existing methods for protein representation learning have utilized only one or two of these modalities due to the difficulty of capturing the asymmetric interrelationships between them. To account for this asymmetry, we introduce our novel asymmetric multi-modal masked autoencoder (AMMA). AMMA adopts (1) a unified multi-modal encoder to integrate all three modalities into a unified representation space and (2) asymmetric decoders to ensure that sequence latent features reflect structural and functional information. The experiments demonstrate that the proposed AMMA is highly effective in learning protein representations that exhibit well-aligned inter-modal relationships, which in turn makes it effective for various downstream protein-related tasks.
Read more5/14/2024
0
Evaluating representation learning on the protein structure universe
Arian R. Jamasb, Alex Morehead, Chaitanya K. Joshi, Zuobai Zhang, Kieran Didi, Simon V. Mathis, Charles Harris, Jian Tang, Jianlin Cheng, Pietro Lio, Tom L. Blundell
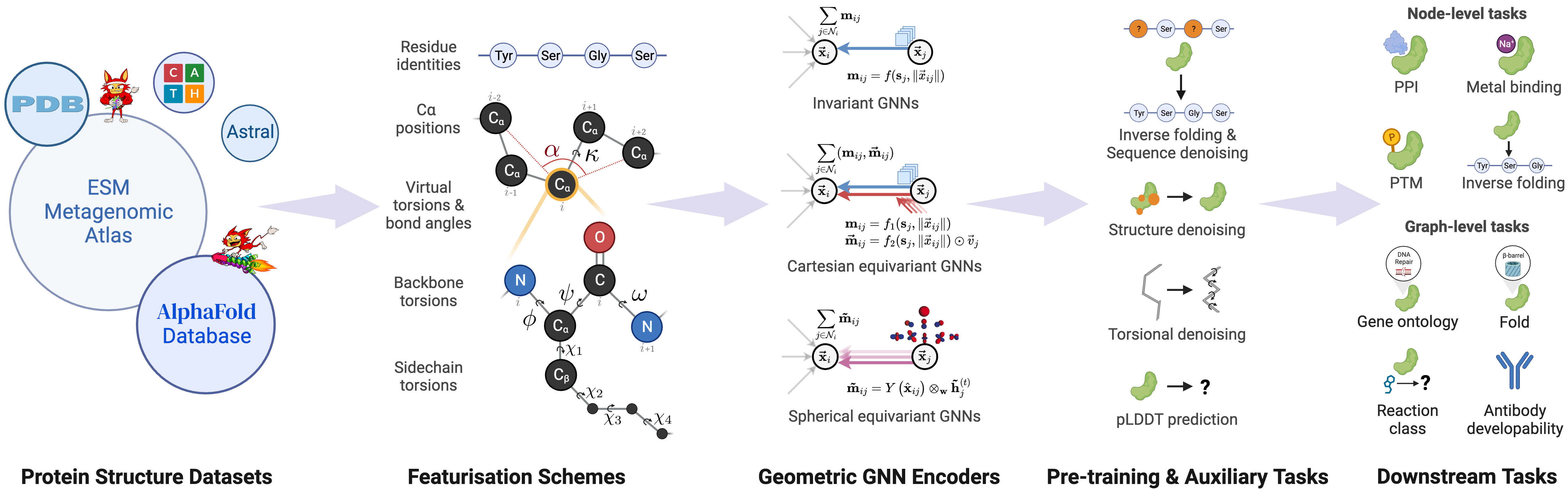
We introduce ProteinWorkshop, a comprehensive benchmark suite for representation learning on protein structures with Geometric Graph Neural Networks. We consider large-scale pre-training and downstream tasks on both experimental and predicted structures to enable the systematic evaluation of the quality of the learned structural representation and their usefulness in capturing functional relationships for downstream tasks. We find that: (1) large-scale pretraining on AlphaFold structures and auxiliary tasks consistently improve the performance of both rotation-invariant and equivariant GNNs, and (2) more expressive equivariant GNNs benefit from pretraining to a greater extent compared to invariant models. We aim to establish a common ground for the machine learning and computational biology communities to rigorously compare and advance protein structure representation learning. Our open-source codebase reduces the barrier to entry for working with large protein structure datasets by providing: (1) storage-efficient dataloaders for large-scale structural databases including AlphaFoldDB and ESM Atlas, as well as (2) utilities for constructing new tasks from the entire PDB. ProteinWorkshop is available at: github.com/a-r-j/ProteinWorkshop.
Read more6/21/2024