Reinforcement Learning for Fine-tuning Text-to-speech Diffusion Models
2405.14632
0
0
🏅
Abstract
Recent advancements in generative models have sparked significant interest within the machine learning community. Particularly, diffusion models have demonstrated remarkable capabilities in synthesizing images and speech. Studies such as those by Lee et al. [19], Black et al. [4], Wang et al. [36], and Fan et al. [8] illustrate that Reinforcement Learning with Human Feedback (RLHF) can enhance diffusion models for image synthesis. However, due to architectural differences between these models and those employed in speech synthesis, it remains uncertain whether RLHF could similarly benefit speech synthesis models. In this paper, we explore the practical application of RLHF to diffusion-based text-to-speech synthesis, leveraging the mean opinion score (MOS) as predicted by UTokyo-SaruLab MOS prediction system [29] as a proxy loss. We introduce diffusion model loss-guided RL policy optimization (DLPO) and compare it against other RLHF approaches, employing the NISQA speech quality and naturalness assessment model [21] and human preference experiments for further evaluation. Our results show that RLHF can enhance diffusion-based text-to-speech synthesis models, and, moreover, DLPO can better improve diffusion models in generating natural and high quality speech audios.
Create account to get full access
Overview
- Recent advancements in generative models, particularly diffusion models, have shown remarkable capabilities in synthesizing images and speech.
- Studies have demonstrated that Reinforcement Learning with Human Feedback (RLHF) can enhance diffusion models for image synthesis.
- However, it remains uncertain whether RLHF could similarly benefit speech synthesis models due to architectural differences.
- This paper explores the practical application of RLHF to diffusion-based text-to-speech synthesis, using the mean opinion score (MOS) as a proxy loss.
- The researchers introduce a new approach called diffusion model loss-guided RL policy optimization (DLPO) and compare it against other RLHF methods.
Plain English Explanation
Generative models, which can create new content like images or speech, have seen significant progress in recent years. Particularly, diffusion models have shown impressive abilities to generate high-quality images and speech.
Previous research has found that using Reinforcement Learning with Human Feedback (RLHF) can improve the performance of diffusion models for generating images. However, the researchers in this paper wanted to explore whether RLHF could also benefit diffusion models used for generating speech, since the underlying architecture of these models is different.
To investigate this, the researchers used a measure called the mean opinion score (MOS) as a way to assess the quality of the speech generated by the diffusion models. They then developed a new approach called diffusion model loss-guided RL policy optimization (DLPO) and compared it to other RLHF methods. The researchers evaluated the different approaches using automated speech quality assessment models and human preference experiments.
Technical Explanation
The paper explores the application of Reinforcement Learning with Human Feedback (RLHF) to diffusion-based text-to-speech synthesis models. The researchers leverage the mean opinion score (MOS) predicted by the UTokyo-SaruLab MOS prediction system as a proxy loss for their RLHF approach.
The researchers introduce a new method called diffusion model loss-guided RL policy optimization (DLPO), which aims to enhance the diffusion models' ability to generate natural and high-quality speech audio. They compare DLPO to other RLHF approaches, evaluating the generated speech using the NISQA speech quality and naturalness assessment model, as well as through human preference experiments.
The results show that RLHF can indeed improve the performance of diffusion-based text-to-speech synthesis models. Moreover, the researchers found that their proposed DLPO method outperforms other RLHF approaches in generating more natural and higher-quality speech audio.
Critical Analysis
The paper provides a valuable exploration of applying RLHF techniques to diffusion-based text-to-speech synthesis models, which have not been as extensively studied as their image synthesis counterparts. The researchers' introduction of the DLPO method is a novel contribution to the field.
However, the paper does not discuss any potential limitations or caveats of their approach. For example, it would be helpful to understand the computational and training resource requirements of DLPO compared to other RLHF methods, as well as any potential biases or artifacts that may arise in the generated speech.
Additionally, the paper could have delved deeper into the underlying reasons why RLHF is more beneficial for diffusion-based text-to-speech synthesis compared to other architectures. Exploring the specific architectural differences and how they interact with the RLHF process could provide valuable insights for the research community.
Overall, the paper presents an interesting and promising direction for enhancing diffusion-based speech synthesis models, but further research is needed to fully understand the limitations and potential issues with the proposed approach.
Conclusion
This paper demonstrates that Reinforcement Learning with Human Feedback (RLHF) can be effectively applied to diffusion-based text-to-speech synthesis models, leading to improved natural and high-quality speech generation. The researchers introduce a novel method called DLPO that outperforms other RLHF approaches in their experiments.
The findings of this paper suggest that RLHF techniques can be a valuable tool for enhancing the performance of diffusion models in speech synthesis, in addition to their well-documented benefits for image synthesis. This work opens up opportunities for further research and development in this area, which could have significant implications for the field of generative AI and its real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

RLHF Deciphered: A Critical Analysis of Reinforcement Learning from Human Feedback for LLMs
Shreyas Chaudhari, Pranjal Aggarwal, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, Karthik Narasimhan, Ameet Deshpande, Bruno Castro da Silva
0
0
State-of-the-art large language models (LLMs) have become indispensable tools for various tasks. However, training LLMs to serve as effective assistants for humans requires careful consideration. A promising approach is reinforcement learning from human feedback (RLHF), which leverages human feedback to update the model in accordance with human preferences and mitigate issues like toxicity and hallucinations. Yet, an understanding of RLHF for LLMs is largely entangled with initial design choices that popularized the method and current research focuses on augmenting those choices rather than fundamentally improving the framework. In this paper, we analyze RLHF through the lens of reinforcement learning principles to develop an understanding of its fundamentals, dedicating substantial focus to the core component of RLHF -- the reward model. Our study investigates modeling choices, caveats of function approximation, and their implications on RLHF training algorithms, highlighting the underlying assumptions made about the expressivity of reward. Our analysis improves the understanding of the role of reward models and methods for their training, concurrently revealing limitations of the current methodology. We characterize these limitations, including incorrect generalization, model misspecification, and the sparsity of feedback, along with their impact on the performance of a language model. The discussion and analysis are substantiated by a categorical review of current literature, serving as a reference for researchers and practitioners to understand the challenges of RLHF and build upon existing efforts.
4/17/2024
📈
Boosting Diffusion Model for Spectrogram Up-sampling in Text-to-speech: An Empirical Study
Chong Zhang, Yanqing Liu, Yang Zheng, Sheng Zhao
0
0
Scaling text-to-speech (TTS) with autoregressive language model (LM) to large-scale datasets by quantizing waveform into discrete speech tokens is making great progress to capture the diversity and expressiveness in human speech, but the speech reconstruction quality from discrete speech token is far from satisfaction depending on the compressed speech token compression ratio. Generative diffusion models trained with score-matching loss and continuous normalized flow trained with flow-matching loss have become prominent in generation of images as well as speech. LM based TTS systems usually quantize speech into discrete tokens and generate these tokens autoregressively, and finally use a diffusion model to up sample coarse-grained speech tokens into fine-grained codec features or mel-spectrograms before reconstructing into waveforms with vocoder, which has a high latency and is not realistic for real time speech applications. In this paper, we systematically investigate varied diffusion models for up sampling stage, which is the main bottleneck for streaming synthesis of LM and diffusion-based architecture, we present the model architecture, objective and subjective metrics to show quality and efficiency improvement.
6/10/2024

Nash Learning from Human Feedback
R'emi Munos, Michal Valko, Daniele Calandriello, Mohammad Gheshlaghi Azar, Mark Rowland, Zhaohan Daniel Guo, Yunhao Tang, Matthieu Geist, Thomas Mesnard, Andrea Michi, Marco Selvi, Sertan Girgin, Nikola Momchev, Olivier Bachem, Daniel J. Mankowitz, Doina Precup, Bilal Piot
0
0
Reinforcement learning from human feedback (RLHF) has emerged as the main paradigm for aligning large language models (LLMs) with human preferences. Typically, RLHF involves the initial step of learning a reward model from human feedback, often expressed as preferences between pairs of text generations produced by a pre-trained LLM. Subsequently, the LLM's policy is fine-tuned by optimizing it to maximize the reward model through a reinforcement learning algorithm. However, an inherent limitation of current reward models is their inability to fully represent the richness of human preferences and their dependency on the sampling distribution. In this study, we introduce an alternative pipeline for the fine-tuning of LLMs using pairwise human feedback. Our approach entails the initial learning of a preference model, which is conditioned on two inputs given a prompt, followed by the pursuit of a policy that consistently generates responses preferred over those generated by any competing policy, thus defining the Nash equilibrium of this preference model. We term this approach Nash learning from human feedback (NLHF). In the context of a tabular policy representation, we present a novel algorithmic solution, Nash-MD, founded on the principles of mirror descent. This algorithm produces a sequence of policies, with the last iteration converging to the regularized Nash equilibrium. Additionally, we explore parametric representations of policies and introduce gradient descent algorithms for deep-learning architectures. To demonstrate the effectiveness of our approach, we present experimental results involving the fine-tuning of a LLM for a text summarization task. We believe NLHF offers a compelling avenue for preference learning and policy optimization with the potential of advancing the field of aligning LLMs with human preferences.
6/12/2024
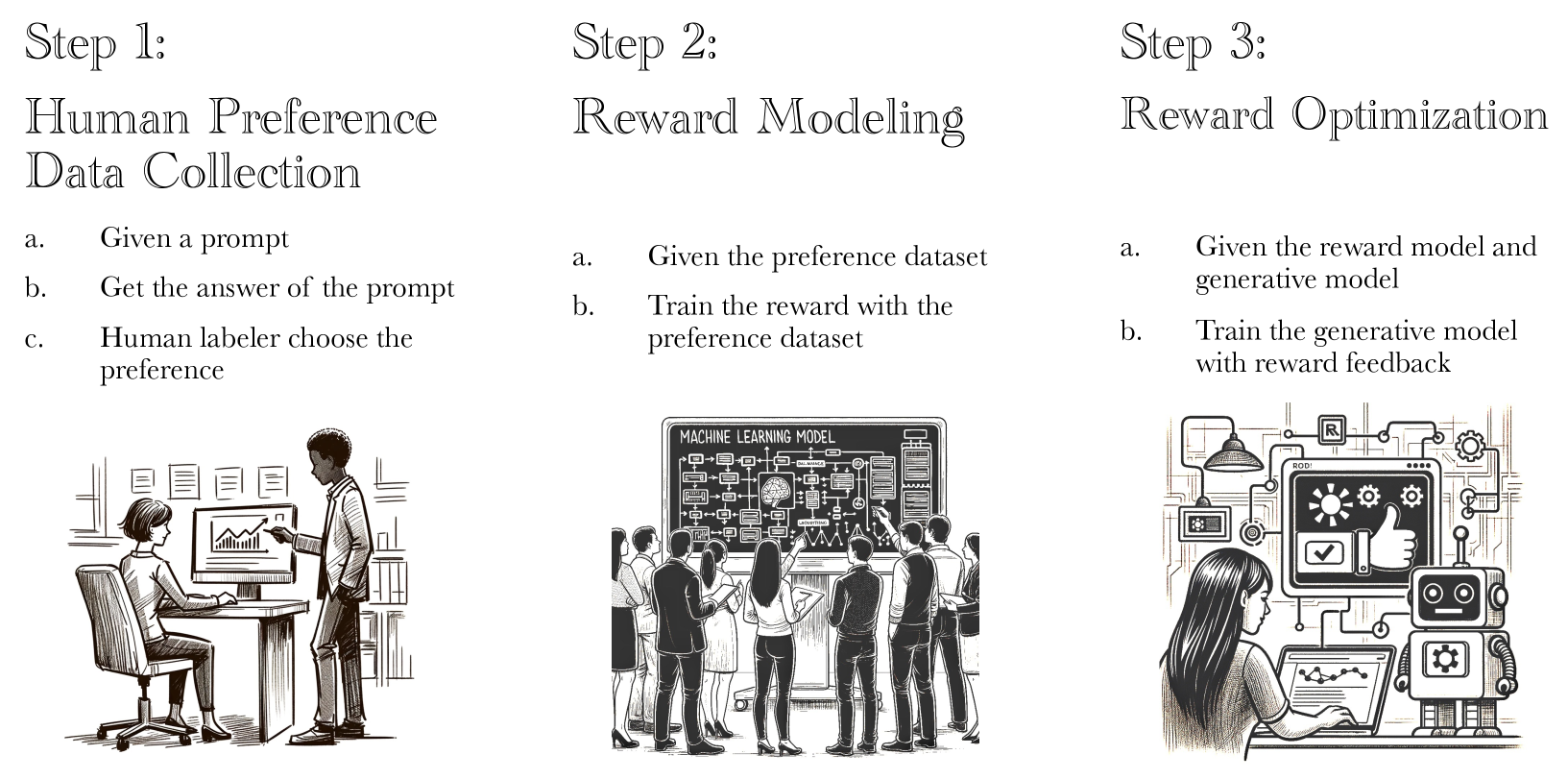
Iterative Preference Learning from Human Feedback: Bridging Theory and Practice for RLHF under KL-Constraint
Wei Xiong, Hanze Dong, Chenlu Ye, Ziqi Wang, Han Zhong, Heng Ji, Nan Jiang, Tong Zhang
0
0
This paper studies the alignment process of generative models with Reinforcement Learning from Human Feedback (RLHF). We first identify the primary challenges of existing popular methods like offline PPO and offline DPO as lacking in strategical exploration of the environment. Then, to understand the mathematical principle of RLHF, we consider a standard mathematical formulation, the reverse-KL regularized contextual bandit for RLHF. Despite its widespread practical application, a rigorous theoretical analysis of this formulation remains open. We investigate its behavior in three distinct settings -- offline, online, and hybrid -- and propose efficient algorithms with finite-sample theoretical guarantees. Moving towards practical applications, our framework, with a robust approximation of the information-theoretical policy improvement oracle, naturally gives rise to several novel RLHF algorithms. This includes an iterative version of the Direct Preference Optimization (DPO) algorithm for online settings, and a multi-step rejection sampling strategy for offline scenarios. Our empirical evaluations on real-world alignment experiment of large language model demonstrate that these proposed methods significantly surpass existing strong baselines, such as DPO and Rejection Sampling Optimization (RSO), showcasing the connections between solid theoretical foundations and their potent practical implementations.
5/2/2024