Towards Codable Watermarking for Injecting Multi-bits Information to LLMs
2307.15992
0
0
🛸
Abstract
As large language models (LLMs) generate texts with increasing fluency and realism, there is a growing need to identify the source of texts to prevent the abuse of LLMs. Text watermarking techniques have proven reliable in distinguishing whether a text is generated by LLMs by injecting hidden patterns. However, we argue that existing LLM watermarking methods are encoding-inefficient and cannot flexibly meet the diverse information encoding needs (such as encoding model version, generation time, user id, etc.). In this work, we conduct the first systematic study on the topic of Codable Text Watermarking for LLMs (CTWL) that allows text watermarks to carry multi-bit customizable information. First of all, we study the taxonomy of LLM watermarking technologies and give a mathematical formulation for CTWL. Additionally, we provide a comprehensive evaluation system for CTWL: (1) watermarking success rate, (2) robustness against various corruptions, (3) coding rate of payload information, (4) encoding and decoding efficiency, (5) impacts on the quality of the generated text. To meet the requirements of these non-Pareto-improving metrics, we follow the most prominent vocabulary partition-based watermarking direction, and devise an advanced CTWL method named Balance-Marking. The core idea of our method is to use a proxy language model to split the vocabulary into probability-balanced parts, thereby effectively maintaining the quality of the watermarked text. Our code is available at https://github.com/lancopku/codable-watermarking-for-llm.
Create account to get full access
Overview
- As large language models (LLMs) generate more realistic and fluent texts, there is a growing need to identify the source of these texts to prevent misuse.
- Text watermarking techniques have proven reliable in distinguishing whether a text is generated by LLMs by embedding hidden patterns.
- Existing LLM watermarking methods are encoding-inefficient and cannot flexibly meet diverse information encoding needs (e.g., encoding model version, generation time, user id).
- This work proposes a systematic study on Codable Text Watermarking for LLMs (CTWL) that allows text watermarks to carry multi-bit customizable information.
Plain English Explanation
As large language models become more advanced, they can generate text that is increasingly realistic and fluent, making it harder to tell if the text was written by a human or by a machine. To address this, researchers have developed text watermarking techniques that can embed hidden patterns in the text to identify its source.
However, the existing watermarking methods have limitations. They are not very efficient at encoding information, and they cannot easily be customized to include different types of data, such as the version of the language model used, when the text was generated, or who generated it.
In this paper, the researchers conduct a comprehensive study on a new approach called Codable Text Watermarking for LLMs (CTWL). CTWL allows the watermark to carry multiple bits of customizable information, making it more flexible and useful.
The key idea is to use a "proxy" language model to split the vocabulary into parts that have a balanced probability of being used. This helps maintain the quality of the watermarked text, ensuring it still reads naturally. The researchers also develop a comprehensive evaluation system to assess the watermarking method's success rate, robustness, encoding efficiency, and impact on text quality.
Technical Explanation
The researchers first study the taxonomy of LLM watermarking technologies and provide a mathematical formulation for Codable Text Watermarking for LLMs (CTWL). CTWL aims to allow text watermarks to carry multi-bit customizable information, in contrast to existing methods that are encoding-inefficient and lack flexibility.
To evaluate CTWL, the researchers propose a comprehensive system that considers: (1) watermarking success rate, (2) robustness against various corruptions, (3) coding rate of payload information, (4) encoding and decoding efficiency, and (5) impacts on the quality of the generated text. These metrics are often non-Pareto-improving, meaning improvements in one area may come at the cost of others.
The researchers follow the prominent vocabulary partition-based watermarking approach and devise an advanced CTWL method called "Balance-Marking." The key idea is to use a proxy language model to split the vocabulary into probability-balanced parts, which helps maintain the quality of the watermarked text. This is in contrast to entropy-based text watermarking detection methods, which may struggle with preserving text quality.
The researchers make their code available at https://github.com/lancopku/codable-watermarking-for-llm for further research and development.
Critical Analysis
The paper presents a comprehensive study on Codable Text Watermarking for LLMs (CTWL), which addresses the limitations of existing watermarking methods. The proposed Balance-Marking approach seems promising in maintaining text quality while encoding customizable information.
However, the paper does not discuss the potential computational overhead or latency introduced by the proxy language model used in Balance-Marking. Additionally, the researchers could have explored the robustness of the watermarking technique against more advanced attacks, such as training LLMs over neurally compressed text or deciphering textual authenticity through a generalized strategy.
Further research could also investigate the practical implications of CTWL, such as its deployment in real-world scenarios and the potential impact on user privacy and trust in LLM-generated content.
Conclusion
This paper presents a systematic study on Codable Text Watermarking for LLMs (CTWL), a novel approach that allows text watermarks to carry multi-bit customizable information. The proposed Balance-Marking method addresses the limitations of existing watermarking techniques by using a proxy language model to maintain the quality of the watermarked text.
The comprehensive evaluation system developed by the researchers provides a valuable framework for assessing the performance of CTWL across various metrics, including watermarking success rate, robustness, encoding efficiency, and impact on text quality. The availability of the researchers' code on GitHub also encourages further development and exploration of this important topic in the field of large language model watermarking.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
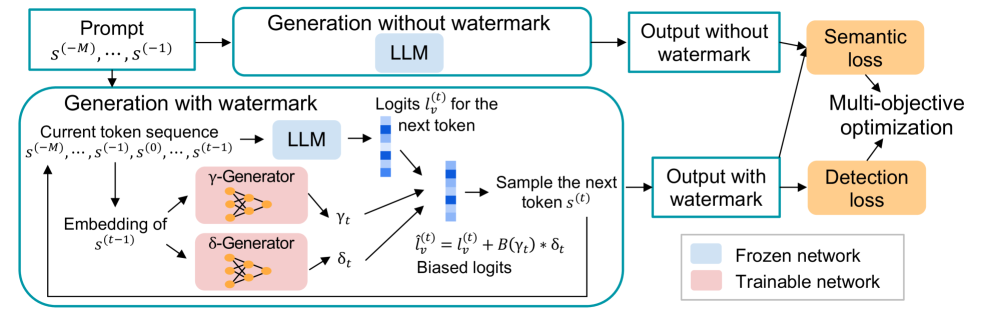
Token-Specific Watermarking with Enhanced Detectability and Semantic Coherence for Large Language Models
Mingjia Huo, Sai Ashish Somayajula, Youwei Liang, Ruisi Zhang, Farinaz Koushanfar, Pengtao Xie
0
0
Large language models generate high-quality responses with potential misinformation, underscoring the need for regulation by distinguishing AI-generated and human-written texts. Watermarking is pivotal in this context, which involves embedding hidden markers in texts during the LLM inference phase, which is imperceptible to humans. Achieving both the detectability of inserted watermarks and the semantic quality of generated texts is challenging. While current watermarking algorithms have made promising progress in this direction, there remains significant scope for improvement. To address these challenges, we introduce a novel multi-objective optimization (MOO) approach for watermarking that utilizes lightweight networks to generate token-specific watermarking logits and splitting ratios. By leveraging MOO to optimize for both detection and semantic objective functions, our method simultaneously achieves detectability and semantic integrity. Experimental results show that our method outperforms current watermarking techniques in enhancing the detectability of texts generated by LLMs while maintaining their semantic coherence. Our code is available at https://github.com/mignonjia/TS_watermark.
6/7/2024

Watermarking Language Models with Error Correcting Codes
Patrick Chao, Edgar Dobriban, Hamed Hassani
0
0
Recent progress in large language models enables the creation of realistic machine-generated content. Watermarking is a promising approach to distinguish machine-generated text from human text, embedding statistical signals in the output that are ideally undetectable to humans. We propose a watermarking framework that encodes such signals through an error correcting code. Our method, termed robust binary code (RBC) watermark, introduces no distortion compared to the original probability distribution, and no noticeable degradation in quality. We evaluate our watermark on base and instruction fine-tuned models and find our watermark is robust to edits, deletions, and translations. We provide an information-theoretic perspective on watermarking, a powerful statistical test for detection and for generating p-values, and theoretical guarantees. Our empirical findings suggest our watermark is fast, powerful, and robust, comparing favorably to the state-of-the-art.
6/18/2024
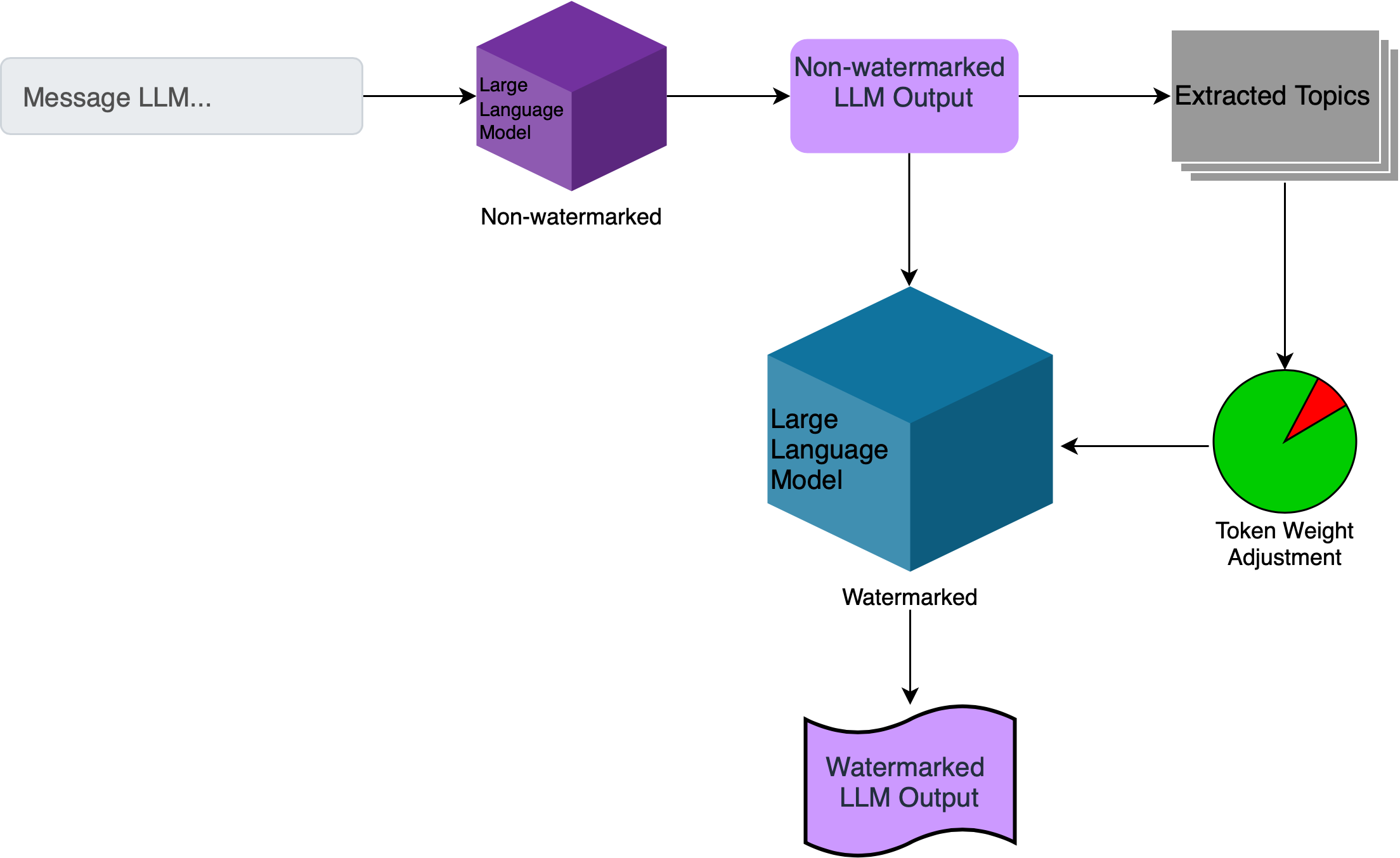
Topic-based Watermarks for LLM-Generated Text
Alexander Nemecek, Yuzhou Jiang, Erman Ayday
0
0
Recent advancements of large language models (LLMs) have resulted in indistinguishable text outputs comparable to human-generated text. Watermarking algorithms are potential tools that offer a way to differentiate between LLM- and human-generated text by embedding detectable signatures within LLM-generated output. However, current watermarking schemes lack robustness against known attacks against watermarking algorithms. In addition, they are impractical considering an LLM generates tens of thousands of text outputs per day and the watermarking algorithm needs to memorize each output it generates for the detection to work. In this work, focusing on the limitations of current watermarking schemes, we propose the concept of a topic-based watermarking algorithm for LLMs. The proposed algorithm determines how to generate tokens for the watermarked LLM output based on extracted topics of an input prompt or the output of a non-watermarked LLM. Inspired from previous work, we propose using a pair of lists (that are generated based on the specified extracted topic(s)) that specify certain tokens to be included or excluded while generating the watermarked output of the LLM. Using the proposed watermarking algorithm, we show the practicality of a watermark detection algorithm. Furthermore, we discuss a wide range of attacks that can emerge against watermarking algorithms for LLMs and the benefit of the proposed watermarking scheme for the feasibility of modeling a potential attacker considering its benefit vs. loss.
4/17/2024
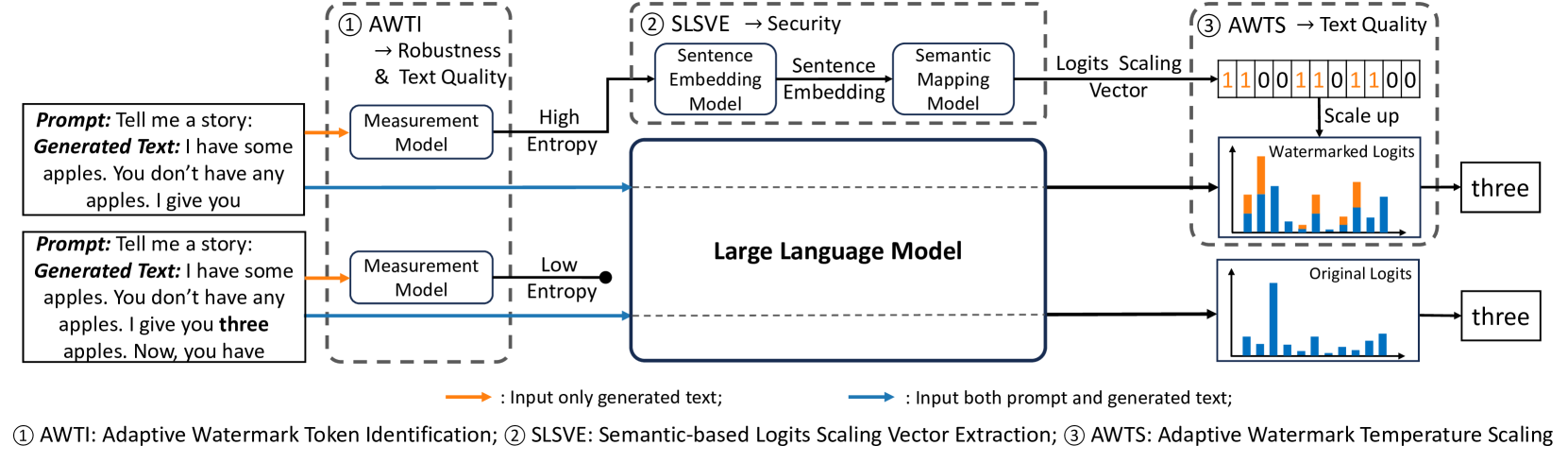
Adaptive Text Watermark for Large Language Models
Yepeng Liu, Yuheng Bu
0
0
The advancement of Large Language Models (LLMs) has led to increasing concerns about the misuse of AI-generated text, and watermarking for LLM-generated text has emerged as a potential solution. However, it is challenging to generate high-quality watermarked text while maintaining strong security, robustness, and the ability to detect watermarks without prior knowledge of the prompt or model. This paper proposes an adaptive watermarking strategy to address this problem. To improve the text quality and maintain robustness, we adaptively add watermarking to token distributions with high entropy measured using an auxiliary model and keep the low entropy token distributions untouched. For the sake of security and to further minimize the watermark's impact on text quality, instead of using a fixed green/red list generated from a random secret key, which can be vulnerable to decryption and forgery, we adaptively scale up the output logits in proportion based on the semantic embedding of previously generated text using a well designed semantic mapping model. Our experiments involving various LLMs demonstrate that our approach achieves comparable robustness performance to existing watermark methods. Additionally, the text generated by our method has perplexity comparable to that of emph{un-watermarked} LLMs while maintaining security even under various attacks.
6/11/2024