Rethinking the Evaluation of Out-of-Distribution Detection: A Sorites Paradox

0

Sign in to get full access
Overview
- The paper discusses issues with the current evaluation of out-of-distribution (OOD) detection methods, a crucial task in machine learning.
- It highlights a "Sorites paradox" where small, seemingly imperceptible changes to inputs can lead to drastically different OOD detection results.
- The authors propose rethinking benchmark construction to address this problem and provide more meaningful and robust OOD evaluation.
Plain English Explanation
Out-of-distribution (OOD) detection is the task of identifying inputs that are significantly different from the data a machine learning model was trained on. This is an important capability, as models can perform poorly on inputs that are very different from their training data.
However, the paper argues that the current ways of evaluating OOD detection methods have some fundamental issues. It uses the "Sorites paradox" as an example - this is a paradox where making a small, seemingly insignificant change to something can lead to a drastically different conclusion.
Similarly, the paper shows that machine learning models can give wildly different OOD detection results even when the input is only slightly changed. This undermines the meaningfulness of current OOD evaluation practices.
To address this, the authors propose rethinking how OOD detection benchmarks are constructed. The goal is to create more robust and informative ways of evaluating these important capabilities in machine learning models.
Technical Explanation
The paper first discusses the growing importance of OOD detection in machine learning, as models are being deployed in increasingly diverse real-world settings. Evaluating OOD detection performance is crucial, but the authors argue that current benchmark designs suffer from significant flaws.
Specifically, they highlight the "Sorites paradox" - a philosophical puzzle where making tiny, incremental changes to something can eventually lead to a drastically different classification. The paper shows that this paradox also applies to OOD detection, where small input perturbations can cause models to drastically change their OOD predictions.
This raises doubts about the meaningfulness of current OOD detection benchmarks, which typically rely on a clear delineation between in-distribution and out-of-distribution data. The authors propose that a more nuanced, continuous perspective on OOD detection is needed, where the goal is to capture a model's overall robustness to distributional shift rather than binary classification.
To this end, the paper discusses several ways that OOD benchmarks could be reconstructed, such as using continual unsupervised OOD detection techniques or embracing covariate shift as a more realistic OOD paradigm. It also highlights the need for more diverse OOD benchmarks, including in specialized domains like medical imaging.
Critical Analysis
The paper makes a compelling case that current OOD detection evaluation practices are flawed and in need of rethinking. The Sorites paradox example vividly illustrates how small input changes can dramatically impact OOD detection, undermining the meaningfulness of binary in-distribution/out-of-distribution classification.
However, the proposed solutions, while promising, also come with their own challenges. Embracing a more continuous perspective on OOD, for instance, raises questions about how to quantify and compare models' overall robustness. And constructing more diverse, realistic OOD benchmarks is a non-trivial undertaking.
Additionally, the paper does not delve deeply into the potential societal impacts of improved OOD detection, such as enhanced safety for AI systems deployed in high-stakes domains. Exploring these implications could further strengthen the case for rethinking OOD evaluation.
Overall, the paper makes a strong case that the machine learning community needs to take a critical look at how it assesses OOD detection capabilities. The authors' suggestions provide a valuable starting point for more meaningful and robust OOD evaluation frameworks.
Conclusion
This paper argues that the current methods for evaluating out-of-distribution (OOD) detection in machine learning models are fundamentally flawed. It uses the Sorites paradox to illustrate how small, imperceptible changes to inputs can lead to drastically different OOD detection results, undermining the meaningfulness of existing benchmarks.
To address this issue, the authors propose rethinking how OOD detection benchmarks are constructed. This could involve embracing more continuous, robustness-focused perspectives on OOD, as well as developing a more diverse set of OOD evaluation datasets and scenarios.
Improving OOD detection is crucial as machine learning models are deployed in increasingly complex real-world settings. By addressing the shortcomings of current evaluation practices, the field can develop more reliable and useful OOD detection capabilities to enhance the safety and robustness of AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Rethinking the Evaluation of Out-of-Distribution Detection: A Sorites Paradox
Xingming Long, Jie Zhang, Shiguang Shan, Xilin Chen
Most existing out-of-distribution (OOD) detection benchmarks classify samples with novel labels as the OOD data. However, some marginal OOD samples actually have close semantic contents to the in-distribution (ID) sample, which makes determining the OOD sample a Sorites Paradox. In this paper, we construct a benchmark named Incremental Shift OOD (IS-OOD) to address the issue, in which we divide the test samples into subsets with different semantic and covariate shift degrees relative to the ID dataset. The data division is achieved through a shift measuring method based on our proposed Language Aligned Image feature Decomposition (LAID). Moreover, we construct a Synthetic Incremental Shift (Syn-IS) dataset that contains high-quality generated images with more diverse covariate contents to complement the IS-OOD benchmark. We evaluate current OOD detection methods on our benchmark and find several important insights: (1) The performance of most OOD detection methods significantly improves as the semantic shift increases; (2) Some methods like GradNorm may have different OOD detection mechanisms as they rely less on semantic shifts to make decisions; (3) Excessive covariate shifts in the image are also likely to be considered as OOD for some methods. Our code and data are released in https://github.com/qqwsad5/IS-OOD.
Read more6/17/2024

0
Rethinking Out-of-Distribution Detection on Imbalanced Data Distribution
Kai Liu, Zhihang Fu, Sheng Jin, Chao Chen, Ze Chen, Rongxin Jiang, Fan Zhou, Yaowu Chen, Jieping Ye
Detecting and rejecting unknown out-of-distribution (OOD) samples is critical for deployed neural networks to void unreliable predictions. In real-world scenarios, however, the efficacy of existing OOD detection methods is often impeded by the inherent imbalance of in-distribution (ID) data, which causes significant performance decline. Through statistical observations, we have identified two common challenges faced by different OOD detectors: misidentifying tail class ID samples as OOD, while erroneously predicting OOD samples as head class from ID. To explain this phenomenon, we introduce a generalized statistical framework, termed ImOOD, to formulate the OOD detection problem on imbalanced data distribution. Consequently, the theoretical analysis reveals that there exists a class-aware bias item between balanced and imbalanced OOD detection, which contributes to the performance gap. Building upon this finding, we present a unified training-time regularization technique to mitigate the bias and boost imbalanced OOD detectors across architecture designs. Our theoretically grounded method translates into consistent improvements on the representative CIFAR10-LT, CIFAR100-LT, and ImageNet-LT benchmarks against several state-of-the-art OOD detection approaches. Code will be made public soon.
Read more7/24/2024

0
Can Your Generative Model Detect Out-of-Distribution Covariate Shift?
Christiaan Viviers, Amaan Valiuddin, Francisco Caetano, Lemar Abdi, Lena Filatova, Peter de With, Fons van der Sommen
Detecting Out-of-Distribution~(OOD) sensory data and covariate distribution shift aims to identify new test examples with different high-level image statistics to the captured, normal and In-Distribution (ID) set. Existing OOD detection literature largely focuses on semantic shift with little-to-no consensus over covariate shift. Generative models capture the ID data in an unsupervised manner, enabling them to effectively identify samples that deviate significantly from this learned distribution, irrespective of the downstream task. In this work, we elucidate the ability of generative models to detect and quantify domain-specific covariate shift through extensive analyses that involves a variety of models. To this end, we conjecture that it is sufficient to detect most occurring sensory faults (anomalies and deviations in global signals statistics) by solely modeling high-frequency signal-dependent and independent details. We propose a novel method, CovariateFlow, for OOD detection, specifically tailored to covariate heteroscedastic high-frequency image-components using conditional Normalizing Flows (cNFs). Our results on CIFAR10 vs. CIFAR10-C and ImageNet200 vs. ImageNet200-C demonstrate the effectiveness of the method by accurately detecting OOD covariate shift. This work contributes to enhancing the fidelity of imaging systems and aiding machine learning models in OOD detection in the presence of covariate shift.
Read more9/6/2024
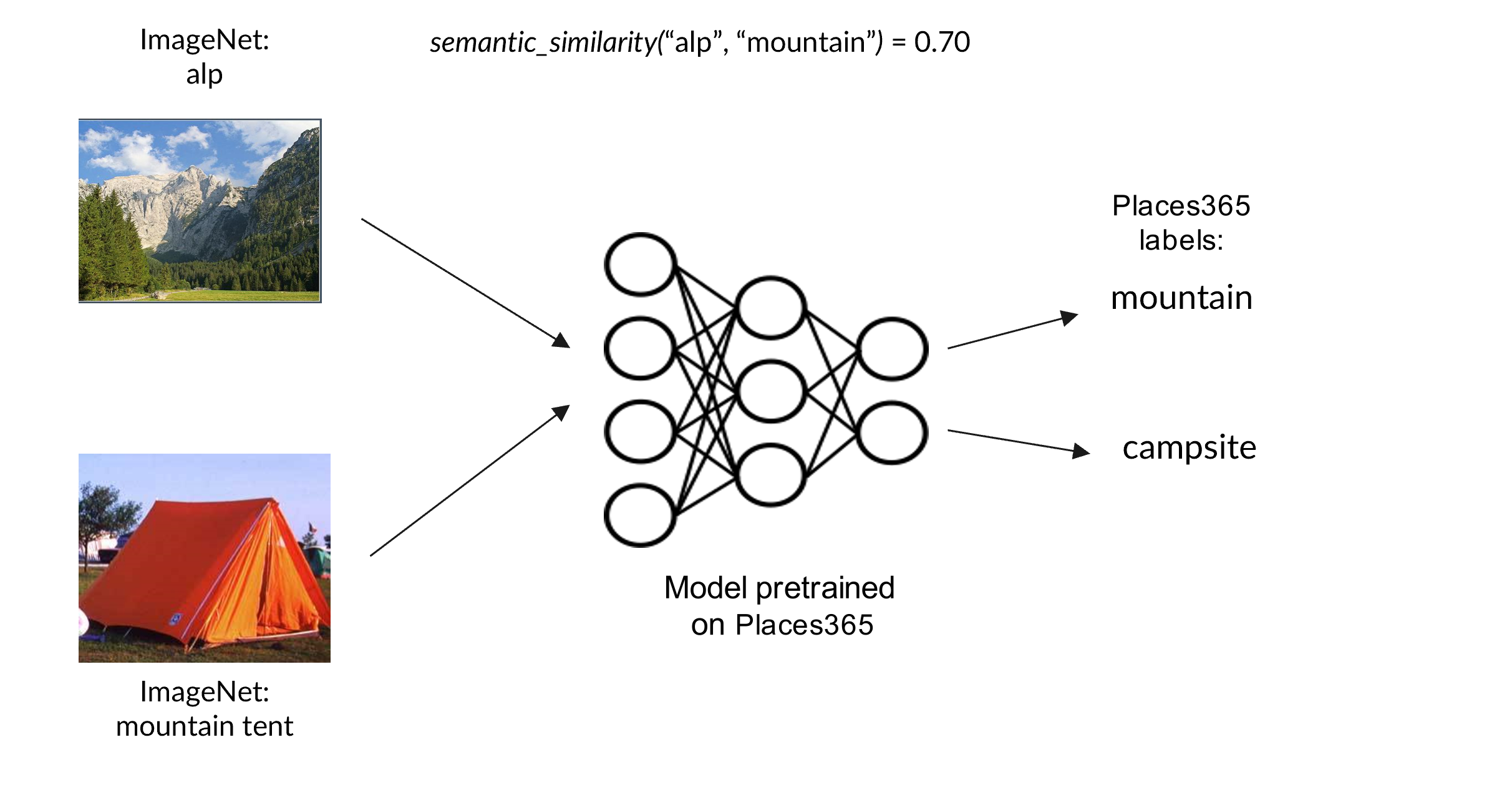
0
Toward a Realistic Benchmark for Out-of-Distribution Detection
Pietro Recalcati, Fabio Garcea, Luca Piano, Fabrizio Lamberti, Lia Morra
Deep neural networks are increasingly used in a wide range of technologies and services, but remain highly susceptible to out-of-distribution (OOD) samples, that is, drawn from a different distribution than the original training set. A common approach to address this issue is to endow deep neural networks with the ability to detect OOD samples. Several benchmarks have been proposed to design and validate OOD detection techniques. However, many of them are based on far-OOD samples drawn from very different distributions, and thus lack the complexity needed to capture the nuances of real-world scenarios. In this work, we introduce a comprehensive benchmark for OOD detection, based on ImageNet and Places365, that assigns individual classes as in-distribution or out-of-distribution depending on the semantic similarity with the training set. Several techniques can be used to determine which classes should be considered in-distribution, yielding benchmarks with varying properties. Experimental results on different OOD detection techniques show how their measured efficacy depends on the selected benchmark and how confidence-based techniques may outperform classifier-based ones on near-OOD samples.
Read more4/17/2024