Rethinking the Role of Proxy Rewards in Language Model Alignment

0

Sign in to get full access
Overview
- This research paper proposes a new approach to preference-free alignment learning with regularized relevance reward.
- The key ideas include using open-source reward models to capture relevance, combining this with a regularized relevance reward, and learning a reward model without relying on human preferences.
- The paper presents experimental results and analysis to support the proposed approach.
Plain English Explanation
Developing AI systems that are aligned with human values is a crucial challenge. One approach is reward modeling, where the goal is to learn a reward function that captures what humans care about.
However, existing reward modeling methods often rely on explicit human preferences, which can be difficult to elicit and may not fully capture the nuance of human values. This paper explores an alternative approach, where the reward function is learned without directly using human preferences.
The key insight is to leverage open-source reward models that have been trained on large datasets to capture relevant aspects of the world. By tuning these models and combining them with a regularized relevance reward, the authors show that it's possible to learn a reward function that aligns with human values without relying on direct preference elicitation.
The paper demonstrates the effectiveness of this approach through experiments, highlighting its potential to leverage domain knowledge for efficient reward modeling.
Technical Explanation
The paper proposes a preference-free alignment learning approach that combines open-source reward models with a regularized relevance reward. The key steps are:
-
Leverage open-source reward models: The authors use pre-trained open-source reward models, such as GPT-Reward, to capture relevant aspects of the world.
-
Combine with regularized relevance reward: The open-source reward models are then combined with a regularized relevance reward that encourages the learned reward function to be relevant to the task at hand, without relying on explicit human preferences.
-
Learn the reward model: The reward model is learned by optimizing this combined objective, resulting in a reward function that aligns with human values without direct preference elicitation.
The authors evaluate their approach on several benchmarks and find that it outperforms baselines that rely on human preferences. The results suggest that leveraging domain knowledge through open-source reward models can be a promising direction for efficient and preference-free reward modeling.
Critical Analysis
The paper presents a novel and promising approach to preference-free alignment learning. However, there are a few potential limitations and areas for further research:
-
Generalization and robustness: While the experiments demonstrate the effectiveness of the proposed approach on the benchmarks considered, it would be important to evaluate its performance on a wider range of tasks and domains to assess its generalization and robustness.
-
Interpretability and transparency: The use of open-source reward models as a starting point raises questions about the interpretability and transparency of the final reward function. Exploring ways to maintain or improve interpretability would be valuable.
-
Ethical considerations: The preference-free nature of the approach raises ethical questions about the potential misalignment between the learned reward function and human values. Careful consideration of these issues is important as the field of reward modeling progresses.
Despite these potential limitations, the paper presents a compelling and innovative approach that could contribute to the ongoing efforts to develop AI systems that are aligned with human values.
Conclusion
This research paper introduces a novel preference-free alignment learning approach that combines open-source reward models with a regularized relevance reward. By leveraging existing reward models and avoiding direct human preference elicitation, the authors demonstrate a promising direction for efficient and transparent reward modeling.
The results suggest that this approach can outperform baselines that rely on human preferences, highlighting the potential of leveraging domain knowledge for reward model learning. As the field of AI alignment continues to evolve, this work could contribute to the development of more robust and ethical AI systems that are better aligned with human values.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Rethinking the Role of Proxy Rewards in Language Model Alignment
Sungdong Kim, Minjoon Seo
Learning from human feedback via proxy reward modeling has been studied to align Large Language Models (LLMs) with human values. However, achieving reliable training through that proxy reward model (RM) is not a trivial problem, and its behavior remained as a black-box. In this paper, we study the role of proxy rewards in the LLM alignment via `reverse reward engineering' by composing interpretable features as a white-box reward function. We aim to replicate the ground truth (gold) reward signal by achieving a monotonic relationship between the proxy and gold reward signals after training the model using the proxy reward in reinforcement learning (RL). Our findings indicate that successfully emulating the gold reward requires generating responses that are relevant with enough length to open-ended questions, while also ensuring response consistency in closed-ended questions. Furthermore, resulting models optimizing our devised white-box reward show competitive performances with strong open-source RMs in alignment benchmarks. We highlight its potential usage as a simple but strong reward baseline for the LLM alignment, not requiring explicit human feedback dataset and RM training. Our code is available at https://github.com/naver-ai/rethinking-proxy-reward.
Read more4/30/2024

0
Cost-Effective Proxy Reward Model Construction with On-Policy and Active Learning
Yifang Chen, Shuohang Wang, Ziyi Yang, Hiteshi Sharma, Nikos Karampatziakis, Donghan Yu, Kevin Jamieson, Simon Shaolei Du, Yelong Shen
Reinforcement learning with human feedback (RLHF), as a widely adopted approach in current large language model pipelines, is textit{bottlenecked by the size of human preference data}. While traditional methods rely on offline preference dataset constructions, recent approaches have shifted towards online settings, where a learner uses a small amount of labeled seed data and a large pool of unlabeled prompts to iteratively construct new preference data through self-generated responses and high-quality reward/preference feedback. However, most current online algorithms still focus on preference labeling during policy model updating with given feedback oracles, which incurs significant expert query costs. textit{We are the first to explore cost-effective proxy reward oracles construction strategies for further labeling preferences or rewards with extremely limited labeled data and expert query budgets}. Our approach introduces two key innovations: (1) on-policy query to avoid OOD and imbalance issues in seed data, and (2) active learning to select the most informative data for preference queries. Using these methods, we train a evaluation model with minimal expert-labeled data, which then effectively labels nine times more preference pairs for further RLHF training. For instance, our model using Direct Preference Optimization (DPO) gains around over 1% average improvement on AlpacaEval2, MMLU-5shot and MMLU-0shot, with only 1.7K query cost. Our methodology is orthogonal to other direct expert query-based strategies and therefore might be integrated with them to further reduce query costs.
Read more7/10/2024
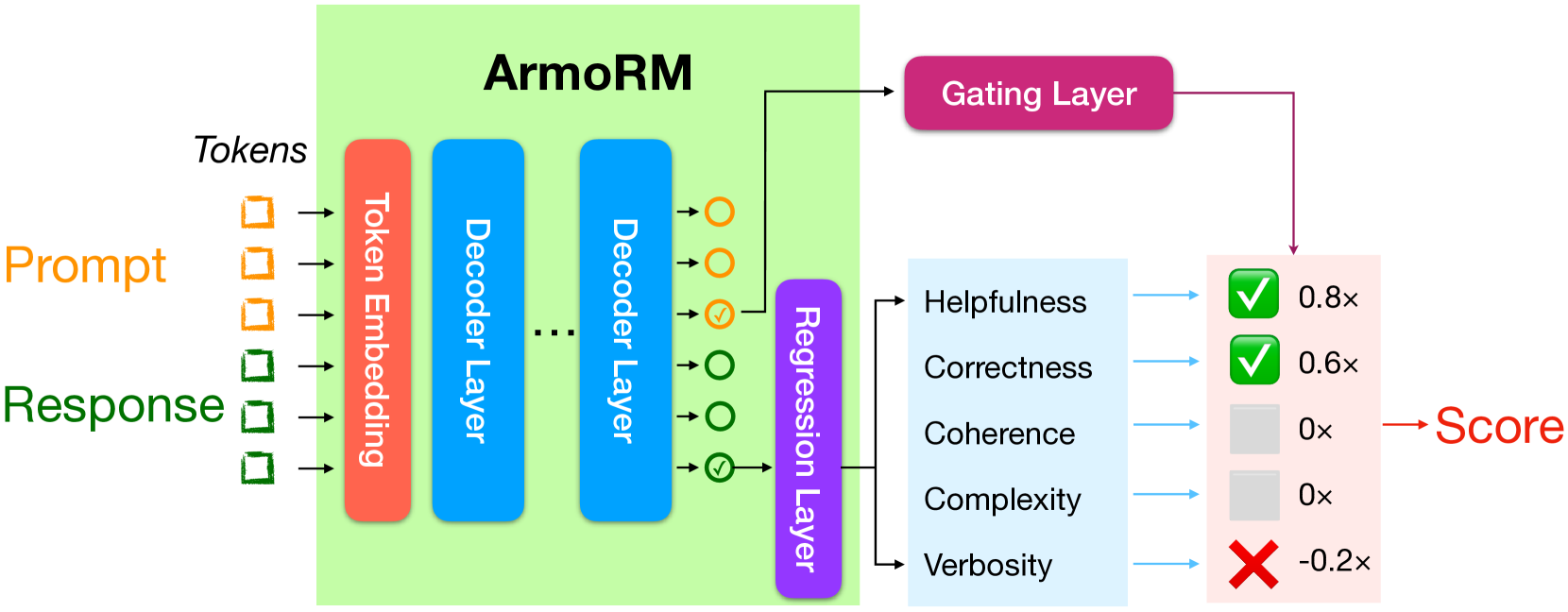
0
Interpretable Preferences via Multi-Objective Reward Modeling and Mixture-of-Experts
Haoxiang Wang, Wei Xiong, Tengyang Xie, Han Zhao, Tong Zhang
Reinforcement learning from human feedback (RLHF) has emerged as the primary method for aligning large language models (LLMs) with human preferences. The RLHF process typically starts by training a reward model (RM) using human preference data. Conventional RMs are trained on pairwise responses to the same user request, with relative ratings indicating which response humans prefer. The trained RM serves as a proxy for human preferences. However, due to the black-box nature of RMs, their outputs lack interpretability, as humans cannot intuitively understand why an RM thinks a response is good or not. As RMs act as human preference proxies, we believe they should be human-interpretable to ensure that their internal decision processes are consistent with human preferences and to prevent reward hacking in LLM alignment. To build RMs with interpretable preferences, we propose a two-stage approach: i) train an Absolute-Rating Multi-Objective Reward Model (ArmoRM) with multi-dimensional absolute-rating data, each dimension corresponding to a human-interpretable objective (e.g., honesty, verbosity, safety); ii) employ a Mixture-of-Experts (MoE) strategy with a gating network that automatically selects the most suitable reward objectives based on the context. We efficiently trained an ArmoRM with Llama-3 8B and a gating network consisting of a shallow MLP on top of the ArmoRM. Our trained model, ArmoRM-Llama3-8B, obtains state-of-the-art performance on RewardBench, a benchmark evaluating RMs for language modeling. Notably, the performance of our model surpasses the LLM-as-a-judge method with GPT-4 judges by a margin, and approaches the performance of the much larger Nemotron-4 340B reward model.
Read more6/19/2024

0
Aligning Large Language Models via Fine-grained Supervision
Dehong Xu, Liang Qiu, Minseok Kim, Faisal Ladhak, Jaeyoung Do
Pre-trained large-scale language models (LLMs) excel at producing coherent articles, yet their outputs may be untruthful, toxic, or fail to align with user expectations. Current approaches focus on using reinforcement learning with human feedback (RLHF) to improve model alignment, which works by transforming coarse human preferences of LLM outputs into a feedback signal that guides the model learning process. However, because this approach operates on sequence-level feedback, it lacks the precision to identify the exact parts of the output affecting user preferences. To address this gap, we propose a method to enhance LLM alignment through fine-grained token-level supervision. Specifically, we ask annotators to minimally edit less preferred responses within the standard reward modeling dataset to make them more favorable, ensuring changes are made only where necessary while retaining most of the original content. The refined dataset is used to train a token-level reward model, which is then used for training our fine-grained Proximal Policy Optimization (PPO) model. Our experiment results demonstrate that this approach can achieve up to an absolute improvement of $5.1%$ in LLM performance, in terms of win rate against the reference model, compared with the traditional PPO model.
Read more6/6/2024