RETVec: Resilient and Efficient Text Vectorizer
2302.09207
3
0
👨🏫
Abstract
This paper describes RETVec, an efficient, resilient, and multilingual text vectorizer designed for neural-based text processing. RETVec combines a novel character encoding with an optional small embedding model to embed words into a 256-dimensional vector space. The RETVec embedding model is pre-trained using pair-wise metric learning to be robust against typos and character-level adversarial attacks. In this paper, we evaluate and compare RETVec to state-of-the-art vectorizers and word embeddings on popular model architectures and datasets. These comparisons demonstrate that RETVec leads to competitive, multilingual models that are significantly more resilient to typos and adversarial text attacks. RETVec is available under the Apache 2 license at https://github.com/google-research/retvec.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- RETVec is an efficient, resilient, and multilingual text vectorizer designed for neural-based text processing.
- It combines a novel character encoding with an optional small embedding model to embed words into a 256-dimensional vector space.
- RETVec's embedding model is pre-trained using pair-wise metric learning to be robust against typos and character-level adversarial attacks.
- Evaluations show RETVec leads to competitive, multilingual models that are significantly more resilient to typos and adversarial text attacks.
Plain English Explanation
RETVec is a new way to convert words into numbers that can be understood by artificial intelligence (AI) systems. It has some unique features that make it better than other approaches:
- It uses a novel character encoding method, which means it has a special way of representing the letters and symbols in words.
- It also has a small embedding model, which is like a mini-dictionary that maps words to 256 numbers.
- The embedding model is trained in a special way to be resistant to typos (spelling mistakes) and attacks that try to trick the system by slightly changing the words.
The paper's experiments show that using RETVec results in AI models that perform well on various tasks and are much more resilient to text-based attacks and errors. This could be very useful for building real-world AI applications that need to work with messy, imperfect text data.
Technical Explanation
RETVec combines a novel character encoding with an optional small embedding model to convert words into 256-dimensional vectors. The character encoding is designed to be efficient and resilient, while the embedding model is pre-trained using pair-wise metric learning to learn representations that are robust to typos and adversarial attacks.
The paper evaluates RETVec on popular model architectures and datasets, comparing it to state-of-the-art vectorizers and word embeddings like GECKO, LLM2Vec, LeanVec, Efficient Multi-Vector Dense Retrieval, and Towards Robustness: Text-to-Visualization Translation Against. The results show that RETVec leads to competitive, multilingual models that are significantly more resilient to typos and adversarial text attacks.
Critical Analysis
The paper provides a thorough evaluation of RETVec, but it does not address some potential limitations:
- The performance of RETVec may degrade on very long or complex texts, as the 256-dimensional representations may not be sufficient to capture all the semantic information.
- The resilience of RETVec to more advanced adversarial attacks, such as those that leverage contextual information, is not evaluated.
- The computational efficiency of RETVec compared to other vectorizers is not extensively benchmarked, which could be an important consideration for real-world applications.
Further research could explore these areas and investigate the broader applicability of RETVec in different domains and use cases.
Conclusion
RETVec is an efficient, resilient, and multilingual text vectorizer that shows promise for building AI models that can handle real-world text data with errors and attacks. The novel character encoding and pre-trained embedding model make RETVec a compelling alternative to existing vectorizers, with potential applications in areas like natural language processing, information retrieval, and content moderation. As the field of AI continues to advance, tools like RETVec will be increasingly important for developing robust and reliable systems that can operate in the messy, imperfect world of human language.
Related Papers
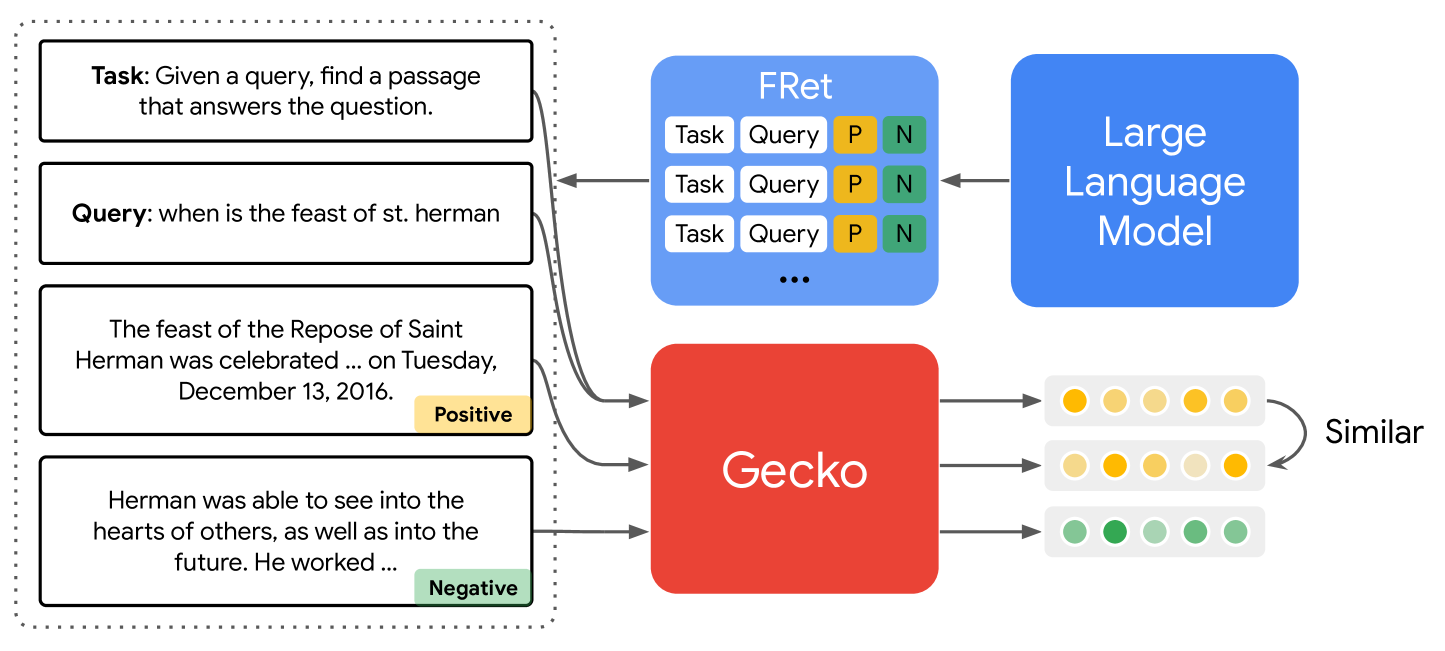
Gecko: Versatile Text Embeddings Distilled from Large Language Models
Jinhyuk Lee, Zhuyun Dai, Xiaoqi Ren, Blair Chen, Daniel Cer, Jeremy R. Cole, Kai Hui, Michael Boratko, Rajvi Kapadia, Wen Ding, Yi Luan, Sai Meher Karthik Duddu, Gustavo Hernandez Abrego, Weiqiang Shi, Nithi Gupta, Aditya Kusupati, Prateek Jain, Siddhartha Reddy Jonnalagadda, Ming-Wei Chang, Iftekhar Naim
0
0
We present Gecko, a compact and versatile text embedding model. Gecko achieves strong retrieval performance by leveraging a key idea: distilling knowledge from large language models (LLMs) into a retriever. Our two-step distillation process begins with generating diverse, synthetic paired data using an LLM. Next, we further refine the data quality by retrieving a set of candidate passages for each query, and relabeling the positive and hard negative passages using the same LLM. The effectiveness of our approach is demonstrated by the compactness of the Gecko. On the Massive Text Embedding Benchmark (MTEB), Gecko with 256 embedding dimensions outperforms all existing entries with 768 embedding size. Gecko with 768 embedding dimensions achieves an average score of 66.31, competing with 7x larger models and 5x higher dimensional embeddings.
4/1/2024
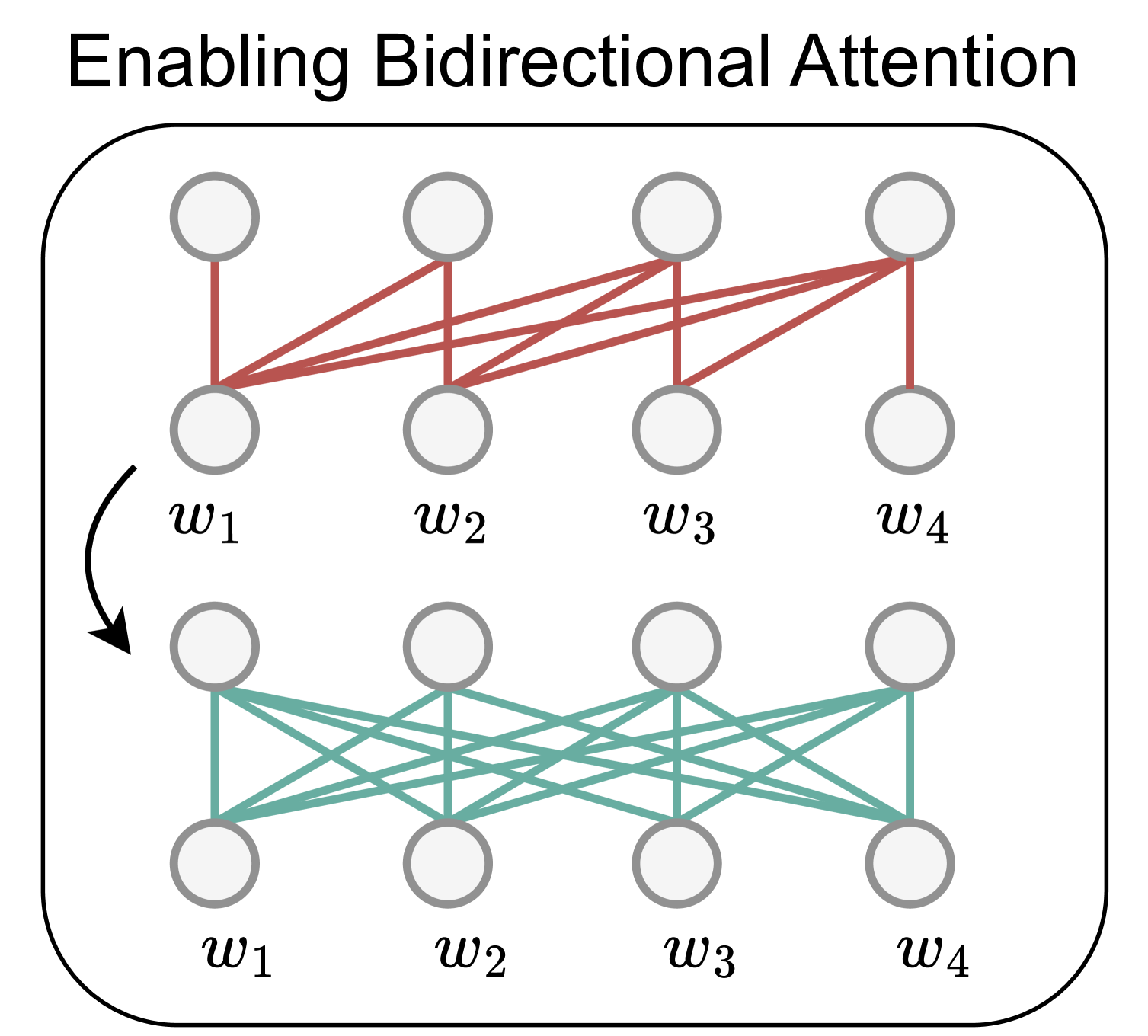
LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders
Parishad BehnamGhader, Vaibhav Adlakha, Marius Mosbach, Dzmitry Bahdanau, Nicolas Chapados, Siva Reddy
0
0
Large decoder-only language models (LLMs) are the state-of-the-art models on most of today's NLP tasks and benchmarks. Yet, the community is only slowly adopting these models for text embedding tasks, which require rich contextualized representations. In this work, we introduce LLM2Vec, a simple unsupervised approach that can transform any decoder-only LLM into a strong text encoder. LLM2Vec consists of three simple steps: 1) enabling bidirectional attention, 2) masked next token prediction, and 3) unsupervised contrastive learning. We demonstrate the effectiveness of LLM2Vec by applying it to 3 popular LLMs ranging from 1.3B to 7B parameters and evaluate the transformed models on English word- and sequence-level tasks. We outperform encoder-only models by a large margin on word-level tasks and reach a new unsupervised state-of-the-art performance on the Massive Text Embeddings Benchmark (MTEB). Moreover, when combining LLM2Vec with supervised contrastive learning, we achieve state-of-the-art performance on MTEB among models that train only on publicly available data. Our strong empirical results and extensive analysis demonstrate that LLMs can be effectively transformed into universal text encoders in a parameter-efficient manner without the need for expensive adaptation or synthetic GPT-4 generated data.
4/10/2024

LeanVec: Searching vectors faster by making them fit
Mariano Tepper, Ishwar Singh Bhati, Cecilia Aguerrebere, Mark Hildebrand, Ted Willke
0
0
Modern deep learning models have the ability to generate high-dimensional vectors whose similarity reflects semantic resemblance. Thus, similarity search, i.e., the operation of retrieving those vectors in a large collection that are similar to a given query, has become a critical component of a wide range of applications that demand highly accurate and timely answers. In this setting, the high vector dimensionality puts similarity search systems under compute and memory pressure, leading to subpar performance. Additionally, cross-modal retrieval tasks have become increasingly common, e.g., where a user inputs a text query to find the most relevant images for that query. However, these queries often have different distributions than the database embeddings, making it challenging to achieve high accuracy. In this work, we present LeanVec, a framework that combines linear dimensionality reduction with vector quantization to accelerate similarity search on high-dimensional vectors while maintaining accuracy. We present LeanVec variants for in-distribution (ID) and out-of-distribution (OOD) queries. LeanVec-ID yields accuracies on par with those from recently introduced deep learning alternatives whose computational overhead precludes their usage in practice. LeanVec-OOD uses two novel techniques for dimensionality reduction that consider the query and database distributions to simultaneously boost the accuracy and the performance of the framework even further (even presenting competitive results when the query and database distributions match). All in all, our extensive and varied experimental results show that LeanVec produces state-of-the-art results, with up to 3.7x improvement in search throughput and up to 4.9x faster index build time over the state of the art.
4/4/2024

Efficient Multi-Vector Dense Retrieval Using Bit Vectors
Franco Maria Nardini, Cosimo Rulli, Rossano Venturini
0
0
Dense retrieval techniques employ pre-trained large language models to build a high-dimensional representation of queries and passages. These representations compute the relevance of a passage w.r.t. to a query using efficient similarity measures. In this line, multi-vector representations show improved effectiveness at the expense of a one-order-of-magnitude increase in memory footprint and query latency by encoding queries and documents on a per-token level. Recently, PLAID has tackled these problems by introducing a centroid-based term representation to reduce the memory impact of multi-vector systems. By exploiting a centroid interaction mechanism, PLAID filters out non-relevant documents, thus reducing the cost of the successive ranking stages. This paper proposes ``Efficient Multi-Vector dense retrieval with Bit vectors'' (EMVB), a novel framework for efficient query processing in multi-vector dense retrieval. First, EMVB employs a highly efficient pre-filtering step of passages using optimized bit vectors. Second, the computation of the centroid interaction happens column-wise, exploiting SIMD instructions, thus reducing its latency. Third, EMVB leverages Product Quantization (PQ) to reduce the memory footprint of storing vector representations while jointly allowing for fast late interaction. Fourth, we introduce a per-document term filtering method that further improves the efficiency of the last step. Experiments on MS MARCO and LoTTE show that EMVB is up to 2.8x faster while reducing the memory footprint by 1.8x with no loss in retrieval accuracy compared to PLAID.
4/4/2024