Towards Robustness of Text-to-Visualization Translation against Lexical and Phrasal Variability
2404.07135
0
0
Abstract
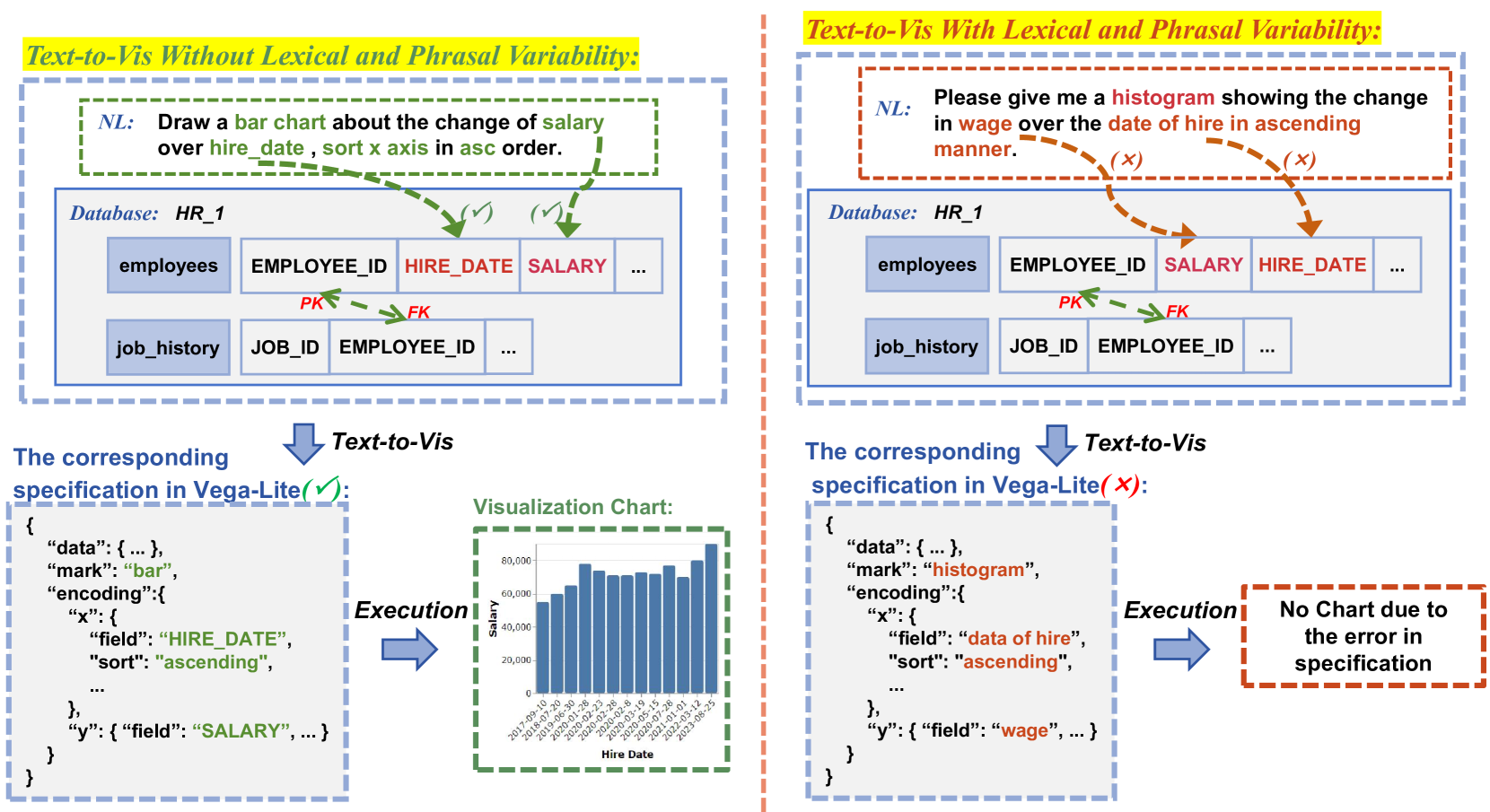
Text-to-Vis is an emerging task in the natural language processing (NLP) area that aims to automatically generate data visualizations from natural language questions (NLQs). Despite their progress, existing text-to-vis models often heavily rely on lexical matching between words in the questions and tokens in data schemas. This overreliance on lexical matching may lead to a diminished level of model robustness against input variations. In this study, we thoroughly examine the robustness of current text-to-vis models, an area that has not previously been explored. In particular, we construct the first robustness dataset nvBench-Rob, which contains diverse lexical and phrasal variations based on the original text-to-vis benchmark nvBench. Then, we found that the performance of existing text-to-vis models on this new dataset dramatically drops, implying that these methods exhibit inadequate robustness overall. Finally, we propose a novel framework based on Retrieval-Augmented Generation (RAG) technique, named GRED, specifically designed to address input perturbations in these two variants. The framework consists of three parts: NLQ-Retrieval Generator, Visualization Query-Retrieval Retuner and Annotation-based Debugger, which are used to tackle the challenges posed by natural language variants, programming style differences and data schema variants, respectively. Extensive experimental evaluations show that, compared to the state-of-the-art model RGVisNet in the Text-to-Vis field, GRED performs better in terms of model robustness, with a 32% increase in accuracy on the proposed nvBench-Rob dataset.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents nvBench-Rob, a new dataset for evaluating the robustness of text-to-visualization translation models against lexical and phrasal variability.
- The dataset contains diverse paraphrases of the original prompts used in the nvBench dataset, which was designed for evaluating text-to-visualization translation.
- The authors aim to assess how well models can handle variations in language when generating visualizations from text-based instructions.
Plain English Explanation
The paper describes a new dataset called nvBench-Rob that is designed to test how well text-to-visualization translation models can handle differences in the way people phrase instructions or descriptions. The nvBench dataset was previously created to evaluate these types of models, but nvBench-Rob adds many alternative phrasings for the original prompts.
The goal is to see if models can still generate the correct visualizations even when the text prompts use different words or phrasing to convey the same meaning. This is an important capability, as real-world users are unlikely to always phrase their requests in the exact same way as the training data. By including these lexical and phrasal variations, the nvBench-Rob dataset aims to provide a more robust and realistic assessment of text-to-visualization translation models.
Technical Explanation
The authors present the nvBench-Rob dataset, which builds upon the nvBench dataset for evaluating text-to-visualization translation. nvBench-Rob includes a diverse set of paraphrased prompts for each of the original nvBench examples.
To create nvBench-Rob, the authors used a combination of manual and automatic techniques to generate alternative phrasings for the nvBench prompts. This includes using templates, lexical substitutions, and backtranslation to introduce lexical and phrasal variations while preserving the intended meaning.
The resulting dataset contains over 50,000 text prompts corresponding to the 5,000 unique visualizations in nvBench. This expanded set of prompts is designed to assess a model's ability to handle linguistic variability and generate the correct visualization regardless of how the input instruction is phrased.
Critical Analysis
The authors acknowledge that while nvBench-Rob provides a more robust evaluation of text-to-visualization translation, it does not address other important aspects of model performance, such as the ability to handle open-ended natural language or generate novel visualizations. The dataset is also limited to the specific visualization types and domains covered by nvBench.
Additionally, the paraphrasing techniques used to create the alternative prompts, while diverse, may not fully capture the breadth of linguistic variation that models would encounter in real-world applications. Further research could explore incorporating more advanced natural language processing techniques or crowdsourcing to generate an even more diverse set of prompts.
Conclusion
The nvBench-Rob dataset represents an important step towards creating more robust and reliable text-to-visualization translation models. By introducing lexical and phrasal variability into the evaluation process, the authors aim to better assess a model's ability to handle the linguistic diversity of real-world user inputs. This work could inspire further advancements in vision-language models and multimodal retrieval systems, ultimately leading to more accessible and user-friendly visualization tools.
Related Papers
Automated Data Visualization from Natural Language via Large Language Models: An Exploratory Study
Yang Wu, Yao Wan, Hongyu Zhang, Yulei Sui, Wucai Wei, Wei Zhao, Guandong Xu, Hai Jin
0
0
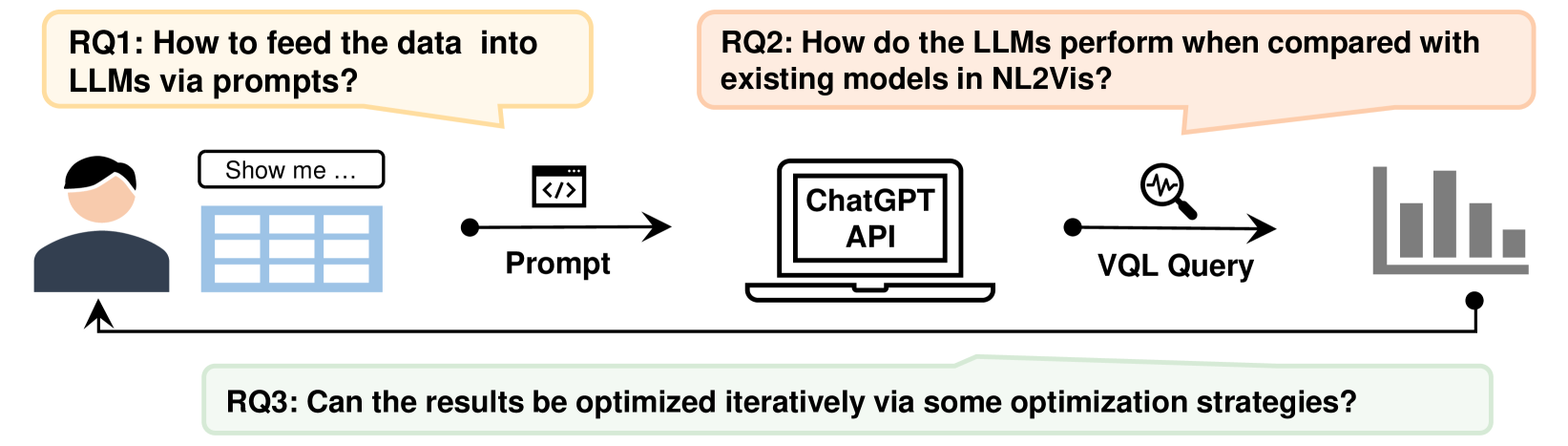
The Natural Language to Visualization (NL2Vis) task aims to transform natural-language descriptions into visual representations for a grounded table, enabling users to gain insights from vast amounts of data. Recently, many deep learning-based approaches have been developed for NL2Vis. Despite the considerable efforts made by these approaches, challenges persist in visualizing data sourced from unseen databases or spanning multiple tables. Taking inspiration from the remarkable generation capabilities of Large Language Models (LLMs), this paper conducts an empirical study to evaluate their potential in generating visualizations, and explore the effectiveness of in-context learning prompts for enhancing this task. In particular, we first explore the ways of transforming structured tabular data into sequential text prompts, as to feed them into LLMs and analyze which table content contributes most to the NL2Vis. Our findings suggest that transforming structured tabular data into programs is effective, and it is essential to consider the table schema when formulating prompts. Furthermore, we evaluate two types of LLMs: finetuned models (e.g., T5-Small) and inference-only models (e.g., GPT-3.5), against state-of-the-art methods, using the NL2Vis benchmarks (i.e., nvBench). The experimental results reveal that LLMs outperform baselines, with inference-only models consistently exhibiting performance improvements, at times even surpassing fine-tuned models when provided with certain few-shot demonstrations through in-context learning. Finally, we analyze when the LLMs fail in NL2Vis, and propose to iteratively update the results using strategies such as chain-of-thought, role-playing, and code-interpreter. The experimental results confirm the efficacy of iterative updates and hold great potential for future study.
4/29/2024
Revisiting the Adversarial Robustness of Vision Language Models: a Multimodal Perspective
Wanqi Zhou, Shuanghao Bai, Qibin Zhao, Badong Chen
0
0
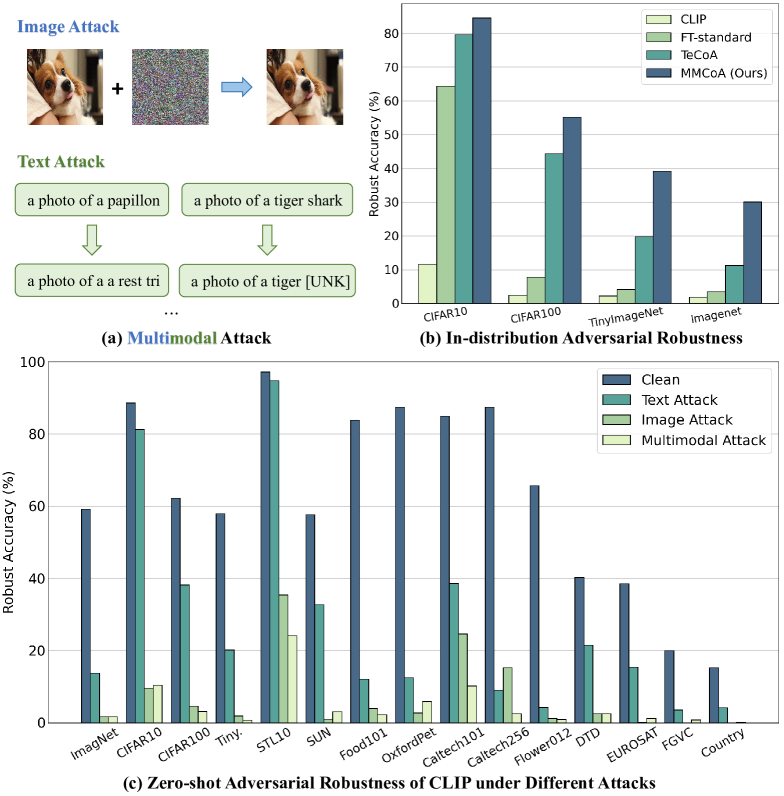
Pretrained vision-language models (VLMs) like CLIP have shown impressive generalization performance across various downstream tasks, yet they remain vulnerable to adversarial attacks. While prior research has primarily concentrated on improving the adversarial robustness of image encoders to guard against attacks on images, the exploration of text-based and multimodal attacks has largely been overlooked. In this work, we initiate the first known and comprehensive effort to study adapting vision-language models for adversarial robustness under the multimodal attack. Firstly, we introduce a multimodal attack strategy and investigate the impact of different attacks. We then propose a multimodal contrastive adversarial training loss, aligning the clean and adversarial text embeddings with the adversarial and clean visual features, to enhance the adversarial robustness of both image and text encoders of CLIP. Extensive experiments on 15 datasets across two tasks demonstrate that our method significantly improves the adversarial robustness of CLIP. Interestingly, we find that the model fine-tuned against multimodal adversarial attacks exhibits greater robustness than its counterpart fine-tuned solely against image-based attacks, even in the context of image attacks, which may open up new possibilities for enhancing the security of VLMs.
5/1/2024
🌐
VISLA Benchmark: Evaluating Embedding Sensitivity to Semantic and Lexical Alterations
Sri Harsha Dumpala, Aman Jaiswal, Chandramouli Sastry, Evangelos Milios, Sageev Oore, Hassan Sajjad
0
0
Despite their remarkable successes, state-of-the-art language models face challenges in grasping certain important semantic details. This paper introduces the VISLA (Variance and Invariance to Semantic and Lexical Alterations) benchmark, designed to evaluate the semantic and lexical understanding of language models. VISLA presents a 3-way semantic (in)equivalence task with a triplet of sentences associated with an image, to evaluate both vision-language models (VLMs) and unimodal language models (ULMs). An evaluation involving 34 VLMs and 20 ULMs reveals surprising difficulties in distinguishing between lexical and semantic variations. Spatial semantics encoded by language models also appear to be highly sensitive to lexical information. Notably, text encoders of VLMs demonstrate greater sensitivity to semantic and lexical variations than unimodal text encoders. Our contributions include the unification of image-to-text and text-to-text retrieval tasks, an off-the-shelf evaluation without fine-tuning, and assessing LMs' semantic (in)variance in the presence of lexical alterations. The results highlight strengths and weaknesses across diverse vision and unimodal language models, contributing to a deeper understanding of their capabilities. % VISLA enables a rigorous evaluation, shedding light on language models' capabilities in handling semantic and lexical nuances. Data and code will be made available at https://github.com/Sri-Harsha/visla_benchmark.
4/26/2024
🏷️
Open-ended VQA benchmarking of Vision-Language models by exploiting Classification datasets and their semantic hierarchy
Simon Ging, Mar'ia A. Bravo, Thomas Brox
0
0
The evaluation of text-generative vision-language models is a challenging yet crucial endeavor. By addressing the limitations of existing Visual Question Answering (VQA) benchmarks and proposing innovative evaluation methodologies, our research seeks to advance our understanding of these models' capabilities. We propose a novel VQA benchmark based on well-known visual classification datasets which allows a granular evaluation of text-generative vision-language models and their comparison with discriminative vision-language models. To improve the assessment of coarse answers on fine-grained classification tasks, we suggest using the semantic hierarchy of the label space to ask automatically generated follow-up questions about the ground-truth category. Finally, we compare traditional NLP and LLM-based metrics for the problem of evaluating model predictions given ground-truth answers. We perform a human evaluation study upon which we base our decision on the final metric. We apply our benchmark to a suite of vision-language models and show a detailed comparison of their abilities on object, action, and attribute classification. Our contributions aim to lay the foundation for more precise and meaningful assessments, facilitating targeted progress in the exciting field of vision-language modeling.
5/7/2024