Rewards-in-Context: Multi-objective Alignment of Foundation Models with Dynamic Preference Adjustment

0
🏷️
Sign in to get full access
Overview
- Aligning large AI models (like language models and diffusion models) with diverse human preferences is a critical challenge for developing helpful and safe AI systems.
- Fine-tuning these models using reinforcement learning (RL) is often costly and unstable, and the complexity of human preferences further complicates the alignment process.
- This paper introduces "Rewards-in-Context" (RiC), a simpler approach that uses supervised fine-tuning to align models with multiple rewards.
- RiC supports dynamic adjustment of the model's outputs to better match user preferences during inference time.
Plain English Explanation
As AI systems become more advanced, it's important to ensure they behave in alignment with human values and preferences. This is a challenging problem, as people often have multiple, sometimes conflicting preferences that they want an AI system to balance.
Rewards-in-Context (RiC) aims to address this by conditioning the AI model's responses on various "reward" signals that represent different user preferences. Rather than using reinforcement learning, which can be unstable and computationally expensive, RiC uses a simpler supervised fine-tuning approach to align the model.
Importantly, RiC also allows the system to dynamically adjust its outputs during actual use to better match the user's preferences in that specific context. This is inspired by an optimization technique that aims to find the best compromise between competing objectives.
The key ideas behind RiC are its simplicity and flexibility. By using a single fine-tuned model and dynamic adjustment, it can accommodate diverse user preferences more efficiently than complex reinforcement learning approaches.
Technical Explanation
The paper introduces the "Rewards-in-Context" (RiC) method for aligning large AI models like language models and diffusion models with multiple human preferences. Rather than using reinforcement learning (RL), which can be costly and unstable, RiC applies supervised fine-tuning to condition the model's responses on various reward signals representing different objectives.
Inspired by the analytical solution to an abstracted convex optimization problem, RiC also includes a dynamic inference-time adjustment technique. This allows the model to adapt its outputs during use to better balance the competing objectives and approach a Pareto-optimal solution.
Experiments show that RiC can effectively align both language models and diffusion models to diverse reward signals, requiring only around 10% of the GPU hours needed for a multi-objective RL baseline. This demonstrates the benefits of RiC's simplicity and adaptivity compared to more complex RL approaches.
Critical Analysis
The paper makes a compelling case for the RiC approach to multi-objective alignment of large AI models. By using supervised fine-tuning instead of reinforcement learning, RiC is more stable and efficient, requiring less computational resources. The dynamic adjustment technique is also an interesting innovation, drawing insights from optimization theory to improve the model's ability to balance competing objectives.
However, the paper does not fully address potential limitations or concerns with the RiC method. For example, it's unclear how well RiC would scale to an even larger number of competing objectives, or how sensitive the dynamic adjustment is to the quality and coverage of the training data for the various reward signals.
Additional research on the theoretical properties and robustness of the optimization-inspired adjustment method could help strengthen the claims made in the paper. Exploring the influence of reward margins and confidence-aware optimization techniques may also yield insights to further improve the RiC approach.
Overall, the RiC method represents a promising step forward in the challenging problem of aligning large AI models with diverse human preferences. But continued research and analysis will be needed to fully understand its capabilities and limitations.
Conclusion
This paper introduces the "Rewards-in-Context" (RiC) approach, which uses supervised fine-tuning and dynamic inference-time adjustment to align large AI models like language models and diffusion models with multiple human preferences.
By avoiding the instability and computational cost of reinforcement learning, RiC offers a simpler and more efficient solution to the problem of multi-objective alignment. The dynamic adjustment technique, inspired by optimization theory, allows the model to better balance competing objectives during actual use.
The empirical results demonstrate the effectiveness of RiC, suggesting it could be a valuable tool for developing AI systems that are helpful and aligned with human values. However, further research is needed to fully understand the method's scalability, robustness, and potential limitations.
Overall, the RiC paper represents an important contribution to the ongoing challenge of creating AI systems that are safe and beneficial to humanity.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
0
Rewards-in-Context: Multi-objective Alignment of Foundation Models with Dynamic Preference Adjustment
Rui Yang, Xiaoman Pan, Feng Luo, Shuang Qiu, Han Zhong, Dong Yu, Jianshu Chen
We consider the problem of multi-objective alignment of foundation models with human preferences, which is a critical step towards helpful and harmless AI systems. However, it is generally costly and unstable to fine-tune large foundation models using reinforcement learning (RL), and the multi-dimensionality, heterogeneity, and conflicting nature of human preferences further complicate the alignment process. In this paper, we introduce Rewards-in-Context (RiC), which conditions the response of a foundation model on multiple rewards in its prompt context and applies supervised fine-tuning for alignment. The salient features of RiC are simplicity and adaptivity, as it only requires supervised fine-tuning of a single foundation model and supports dynamic adjustment for user preferences during inference time. Inspired by the analytical solution of an abstracted convex optimization problem, our dynamic inference-time adjustment method approaches the Pareto-optimal solution for multiple objectives. Empirical evidence demonstrates the efficacy of our method in aligning both Large Language Models (LLMs) and diffusion models to accommodate diverse rewards with only around 10% GPU hours compared with multi-objective RL baseline.
Read more6/6/2024
💬
0
Improving Context-Aware Preference Modeling for Language Models
Silviu Pitis, Ziang Xiao, Nicolas Le Roux, Alessandro Sordoni
While finetuning language models from pairwise preferences has proven remarkably effective, the underspecified nature of natural language presents critical challenges. Direct preference feedback is uninterpretable, difficult to provide where multidimensional criteria may apply, and often inconsistent, either because it is based on incomplete instructions or provided by diverse principals. To address these challenges, we consider the two-step preference modeling procedure that first resolves the under-specification by selecting a context, and then evaluates preference with respect to the chosen context. We decompose reward modeling error according to these two steps, which suggests that supervising context in addition to context-specific preference may be a viable approach to aligning models with diverse human preferences. For this to work, the ability of models to evaluate context-specific preference is critical. To this end, we contribute context-conditioned preference datasets and accompanying experiments that investigate the ability of language models to evaluate context-specific preference. We use our datasets to (1) show that existing preference models benefit from, but fail to fully consider, added context, (2) finetune a context-aware reward model with context-specific performance exceeding that of GPT-4 and Llama 3 70B on tested datasets, and (3) investigate the value of context-aware preference modeling.
Read more7/23/2024
🔄
0
LIRE: listwise reward enhancement for preference alignment
Mingye Zhu, Yi Liu, Lei Zhang, Junbo Guo, Zhendong Mao
Recently, tremendous strides have been made to align the generation of Large Language Models (LLMs) with human values to mitigate toxic or unhelpful content. Leveraging Reinforcement Learning from Human Feedback (RLHF) proves effective and is widely adopted by researchers. However, implementing RLHF is complex, and its sensitivity to hyperparameters renders achieving stable performance and scalability challenging. Furthermore, prevailing approaches to preference alignment primarily concentrate on pairwise comparisons, with limited exploration into multi-response scenarios, thereby overlooking the potential richness within the candidate pool. For the above reasons, we propose a new approach: Listwise Reward Enhancement for Preference Alignment (LIRE), a gradient-based reward optimization approach that incorporates the offline rewards of multiple responses into a streamlined listwise framework, thus eliminating the need for online sampling during training. LIRE is straightforward to implement, requiring minimal parameter tuning, and seamlessly aligns with the pairwise paradigm while naturally extending to multi-response scenarios. Moreover, we introduce a self-enhancement algorithm aimed at iteratively refining the reward during training. Our experiments demonstrate that LIRE consistently outperforms existing methods across several benchmarks on dialogue and summarization tasks, with good transferability to out-of-distribution data, assessed using proxy reward models and human annotators.
Read more6/5/2024
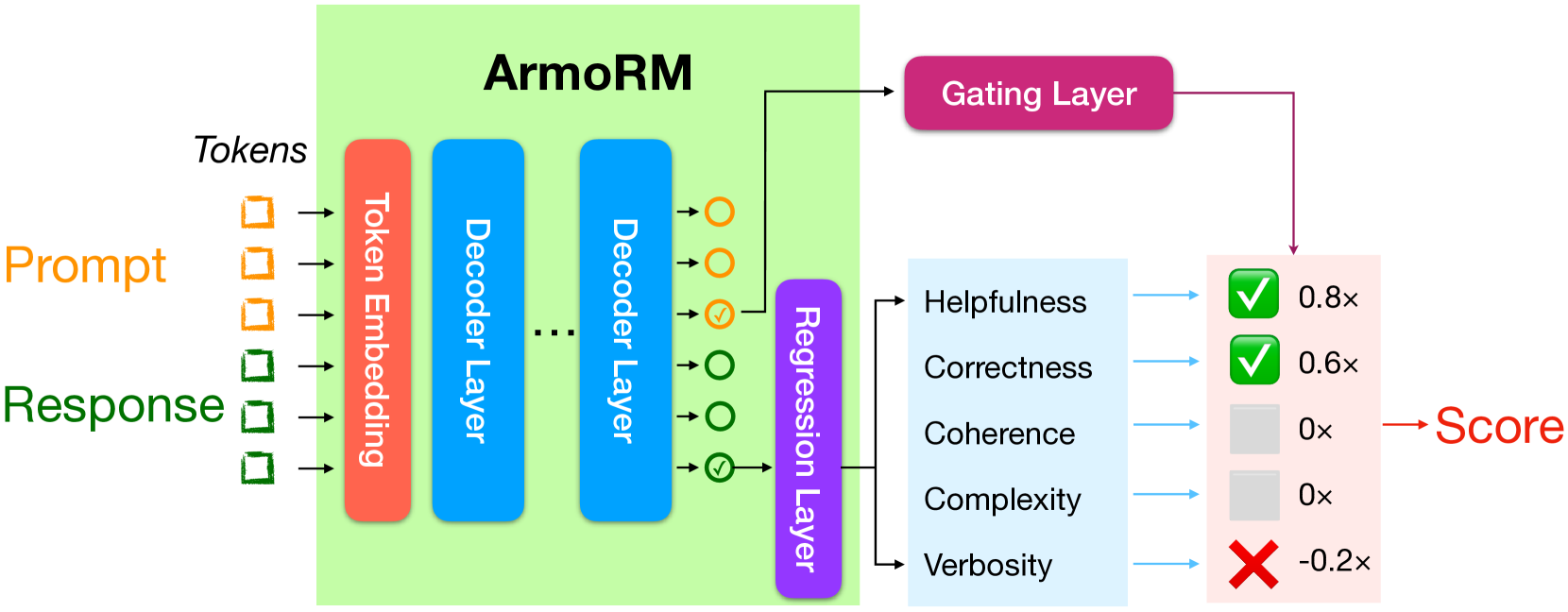
0
Interpretable Preferences via Multi-Objective Reward Modeling and Mixture-of-Experts
Haoxiang Wang, Wei Xiong, Tengyang Xie, Han Zhao, Tong Zhang
Reinforcement learning from human feedback (RLHF) has emerged as the primary method for aligning large language models (LLMs) with human preferences. The RLHF process typically starts by training a reward model (RM) using human preference data. Conventional RMs are trained on pairwise responses to the same user request, with relative ratings indicating which response humans prefer. The trained RM serves as a proxy for human preferences. However, due to the black-box nature of RMs, their outputs lack interpretability, as humans cannot intuitively understand why an RM thinks a response is good or not. As RMs act as human preference proxies, we believe they should be human-interpretable to ensure that their internal decision processes are consistent with human preferences and to prevent reward hacking in LLM alignment. To build RMs with interpretable preferences, we propose a two-stage approach: i) train an Absolute-Rating Multi-Objective Reward Model (ArmoRM) with multi-dimensional absolute-rating data, each dimension corresponding to a human-interpretable objective (e.g., honesty, verbosity, safety); ii) employ a Mixture-of-Experts (MoE) strategy with a gating network that automatically selects the most suitable reward objectives based on the context. We efficiently trained an ArmoRM with Llama-3 8B and a gating network consisting of a shallow MLP on top of the ArmoRM. Our trained model, ArmoRM-Llama3-8B, obtains state-of-the-art performance on RewardBench, a benchmark evaluating RMs for language modeling. Notably, the performance of our model surpasses the LLM-as-a-judge method with GPT-4 judges by a margin, and approaches the performance of the much larger Nemotron-4 340B reward model.
Read more6/19/2024