RIME: Robust Preference-based Reinforcement Learning with Noisy Preferences

0

Sign in to get full access
Overview
- This paper presents a new method called RIME (Robust Preference-based Reinforcement Learning with Noisy Preferences) for training AI systems using human preferences as feedback.
- The key idea is to make the learning process more robust to noisy or inconsistent human feedback, which can often occur in real-world applications.
- RIME outperforms existing preference-based reinforcement learning methods on a range of simulated and real-world tasks.
Plain English Explanation
Reinforcement learning is a powerful technique where an AI system learns by trial-and-error, receiving rewards or punishments for its actions. Preference-based reinforcement learning takes this a step further by using human feedback, not just numerical rewards, to guide the learning process.
However, human feedback can be "noisy" - people may be inconsistent or make mistakes when providing preferences. This can cause issues for the AI system during training. The RIME method addresses this by making the learning process more robust to noisy preferences.
Instead of just optimizing for the human preferences, RIME also learns to model the noise and uncertainty in the feedback. This allows the system to better distinguish true preferences from inconsistencies or mistakes, leading to better overall performance.
RIME was tested on a variety of tasks, both in simulation and in the real world. It was able to outperform previous preference-based methods, showing the benefits of the noise-modeling approach. This could be particularly useful in applications where getting clean, consistent feedback from humans is challenging, such as training AI assistants or learning from diverse human preferences.
Technical Explanation
The key technical innovation in RIME is the use of a noise model to capture uncertainties in the human feedback. Rather than just optimizing the AI agent to match the observed preferences, RIME also learns to predict the noise characteristics of the feedback.
This is accomplished by training two neural networks in parallel - one to predict the true underlying preferences, and another to model the noise process. The agent then uses both of these components to inform its actions, allowing it to be more robust to inconsistent or erroneous feedback from humans.
The paper demonstrates the effectiveness of this approach on a suite of simulated tasks as well as real-world robotic manipulation and dialog problems. RIME is shown to outperform prior preference-based RL methods, particularly in scenarios with high levels of noise in the human feedback.
Critical Analysis
The authors acknowledge several limitations of the RIME approach. First, the noise model adds additional complexity to the learning process, which could make it harder to scale to very large or high-dimensional problems. The authors also note that the success of RIME relies on the ability to accurately model the noise characteristics of the human feedback, which may not always be possible in real-world settings.
Additionally, the paper does not explore the impact of different types of noise (e.g. systematic biases versus random inconsistencies) or how the noise model might need to be adapted for different application domains. Further research would be needed to fully understand the strengths and weaknesses of the RIME approach across a broader range of scenarios.
That said, the core idea of making preference-based RL more robust to noisy feedback is an important one, and the empirical results presented in the paper are promising. As AI systems become more embedded in real-world applications, developing methods that can handle imperfect human input will be crucial.
Conclusion
The RIME method presented in this paper represents a significant step forward in preference-based reinforcement learning. By explicitly modeling the noise and uncertainty in human feedback, RIME is able to learn more robust and effective policies, outperforming prior approaches on a range of tasks.
While there are still open questions and limitations to address, the RIME framework demonstrates the potential benefits of considering the noise characteristics of human input when training AI systems. As preference-based RL continues to grow in importance, techniques like RIME could play a key role in building AI assistants and agents that can reliably learn from imperfect human guidance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RIME: Robust Preference-based Reinforcement Learning with Noisy Preferences
Jie Cheng, Gang Xiong, Xingyuan Dai, Qinghai Miao, Yisheng Lv, Fei-Yue Wang
Preference-based Reinforcement Learning (PbRL) circumvents the need for reward engineering by harnessing human preferences as the reward signal. However, current PbRL methods excessively depend on high-quality feedback from domain experts, which results in a lack of robustness. In this paper, we present RIME, a robust PbRL algorithm for effective reward learning from noisy preferences. Our method utilizes a sample selection-based discriminator to dynamically filter out noise and ensure robust training. To counteract the cumulative error stemming from incorrect selection, we suggest a warm start for the reward model, which additionally bridges the performance gap during the transition from pre-training to online training in PbRL. Our experiments on robotic manipulation and locomotion tasks demonstrate that RIME significantly enhances the robustness of the state-of-the-art PbRL method. Code is available at https://github.com/CJReinforce/RIME_ICML2024.
Read more5/31/2024
0
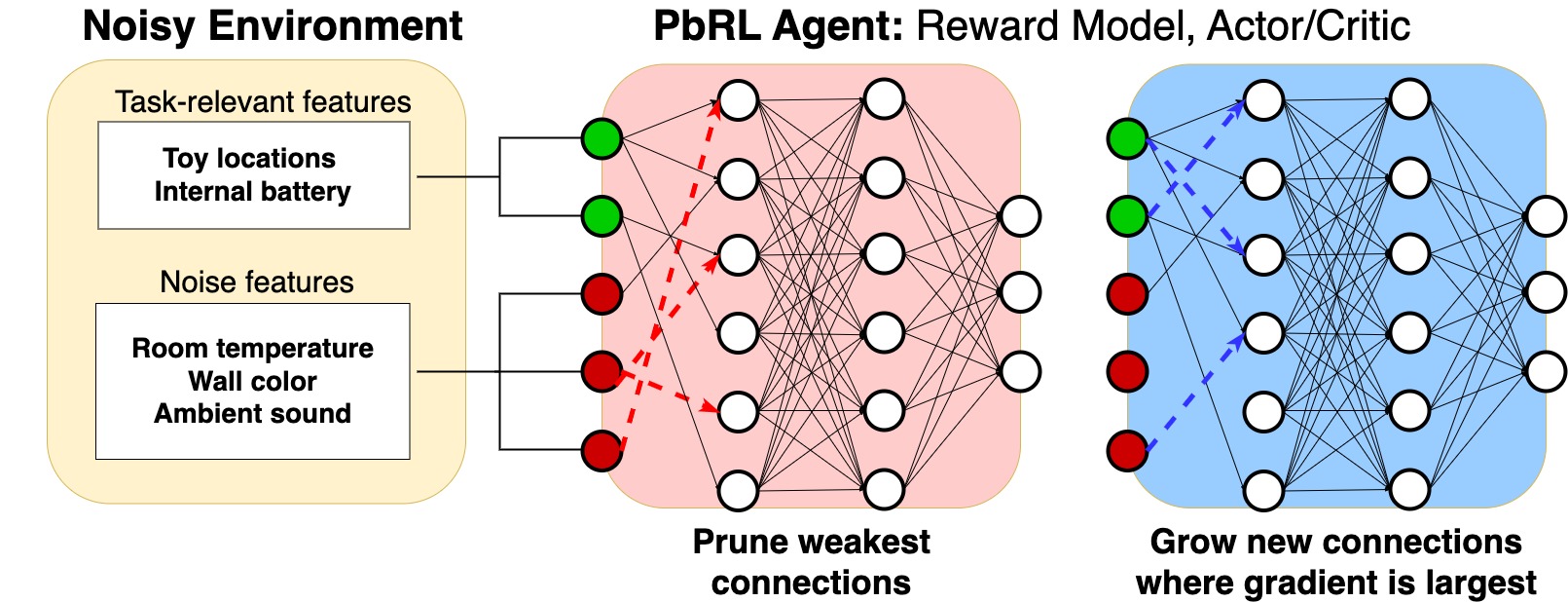
Boosting Robustness in Preference-Based Reinforcement Learning with Dynamic Sparsity
Calarina Muslimani, Bram Grooten, Deepak Ranganatha Sastry Mamillapalli, Mykola Pechenizkiy, Decebal Constantin Mocanu, Matthew E. Taylor
For autonomous agents to successfully integrate into human-centered environments, agents should be able to learn from and adapt to humans in their native settings. Preference-based reinforcement learning (PbRL) is a promising approach that learns reward functions from human preferences. This enables RL agents to adapt their behavior based on human desires. However, humans live in a world full of diverse information, most of which is not relevant to completing a particular task. It becomes essential that agents learn to focus on the subset of task-relevant environment features. Unfortunately, prior work has largely ignored this aspect; primarily focusing on improving PbRL algorithms in standard RL environments that are carefully constructed to contain only task-relevant features. This can result in algorithms that may not effectively transfer to a more noisy real-world setting. To that end, this work proposes R2N (Robust-to-Noise), the first PbRL algorithm that leverages principles of dynamic sparse training to learn robust reward models that can focus on task-relevant features. We study the effectiveness of R2N in the Extremely Noisy Environment setting, an RL problem setting where up to 95% of the state features are irrelevant distractions. In experiments with a simulated teacher, we demonstrate that R2N can adapt the sparse connectivity of its neural networks to focus on task-relevant features, enabling R2N to significantly outperform several state-of-the-art PbRL algorithms in multiple locomotion and control environments.
Read more6/11/2024

0
Learning Robust Reward Machines from Noisy Labels
Roko Parac, Lorenzo Nodari, Leo Ardon, Daniel Furelos-Blanco, Federico Cerutti, Alessandra Russo
This paper presents PROB-IRM, an approach that learns robust reward machines (RMs) for reinforcement learning (RL) agents from noisy execution traces. The key aspect of RM-driven RL is the exploitation of a finite-state machine that decomposes the agent's task into different subtasks. PROB-IRM uses a state-of-the-art inductive logic programming framework robust to noisy examples to learn RMs from noisy traces using the Bayesian posterior degree of beliefs, thus ensuring robustness against inconsistencies. Pivotal for the results is the interleaving between RM learning and policy learning: a new RM is learned whenever the RL agent generates a trace that is believed not to be accepted by the current RM. To speed up the training of the RL agent, PROB-IRM employs a probabilistic formulation of reward shaping that uses the posterior Bayesian beliefs derived from the traces. Our experimental analysis shows that PROB-IRM can learn (potentially imperfect) RMs from noisy traces and exploit them to train an RL agent to solve its tasks successfully. Despite the complexity of learning the RM from noisy traces, agents trained with PROB-IRM perform comparably to agents provided with handcrafted RMs.
Read more8/28/2024
🏅
0
PrefCLM: Enhancing Preference-based Reinforcement Learning with Crowdsourced Large Language Models
Ruiqi Wang, Dezhong Zhao, Ziqin Yuan, Ike Obi, Byung-Cheol Min
Preference-based reinforcement learning (PbRL) is emerging as a promising approach to teaching robots through human comparative feedback, sidestepping the need for complex reward engineering. However, the substantial volume of feedback required in existing PbRL methods often lead to reliance on synthetic feedback generated by scripted teachers. This approach necessitates intricate reward engineering again and struggles to adapt to the nuanced preferences particular to human-robot interaction (HRI) scenarios, where users may have unique expectations toward the same task. To address these challenges, we introduce PrefCLM, a novel framework that utilizes crowdsourced large language models (LLMs) as simulated teachers in PbRL. We utilize Dempster-Shafer Theory to fuse individual preferences from multiple LLM agents at the score level, efficiently leveraging their diversity and collective intelligence. We also introduce a human-in-the-loop pipeline that facilitates collective refinements based on user interactive feedback. Experimental results across various general RL tasks show that PrefCLM achieves competitive performance compared to traditional scripted teachers and excels in facilitating more more natural and efficient behaviors. A real-world user study (N=10) further demonstrates its capability to tailor robot behaviors to individual user preferences, significantly enhancing user satisfaction in HRI scenarios.
Read more7/12/2024