Robust Privacy Amidst Innovation with Large Language Models Through a Critical Assessment of the Risks

0
💬
Sign in to get full access
Overview
- This study explores integrating electronic health records (EHRs) and natural language processing (NLP) with large language models (LLMs) to improve healthcare data management and patient care.
- It focuses on using advanced models to create secure, HIPAA-compliant synthetic patient notes for biomedical research.
- The study used de-identified and re-identified MIMIC III datasets with GPT-3.5, GPT-4, and Mistral 7B to generate synthetic notes.
Plain English Explanation
The paper discusses using large language models to generate synthetic medical notes that can be used for biomedical research, while protecting patient privacy. The researchers used electronic health records and natural language processing techniques to create these synthetic notes.
They tested different methods for generating the notes, including using templates and keyword extraction to ensure the notes are contextually relevant. They also compared one-shot generation, where the model generates the entire note at once, to the keyword-based approach.
The researchers assessed the privacy of the generated notes by checking for the presence of protected health information (PHI). They also evaluated the utility of the notes by using them to perform an ICD-9 coding task, which is a common way to categorize medical diagnoses.
The results showed that the keyword-based method had a low risk of exposing PHI while still maintaining good performance on the coding task. The one-shot generation approach had the highest risk of exposing PHI, especially for things like geographic location and dates.
The study highlights the delicate balance between data utility and privacy protection when using these AI models to generate synthetic medical data. It suggests that methods that enhance both utility and privacy, such as using dummy PHIs, may be the way forward for sharing clinical data more effectively.
Technical Explanation
The study used several LLMs, including GPT-3.5, GPT-4, and Mistral 7B, to generate synthetic patient notes from the de-identified and re-identified MIMIC III dataset. Two main approaches were explored:
- Keyword-based Generation: This method used templates and keyword extraction to ensure the generated notes were contextually relevant.
- One-shot Generation: This approach generated the entire note in a single pass, without using any templates or keywords.
The researchers assessed the privacy of the generated notes by checking for the occurrence of PHI, such as names, dates, and locations. They also evaluated the utility of the notes by using them to perform an ICD-9 coding task, which measures how well the notes can be used for downstream medical applications.
Text quality was evaluated using ROUGE and cosine similarity metrics to measure the semantic similarity between the generated notes and the original source notes.
The analysis showed that the keyword-based method had a low risk of PHI exposure while still maintaining good performance on the ICD-9 coding task. In contrast, the one-shot generation approach had the highest PHI exposure, particularly for geographic location and date categories.
Interestingly, the researchers found that the re-identified data consistently outperformed the de-identified data, suggesting that methods that enhance both utility and privacy, such as using dummy PHIs, may be a promising approach for sharing clinical data more effectively.
Critical Analysis
The study provides a valuable contribution to the field of using large language models for healthcare applications, particularly in the area of protecting patient privacy while maintaining data utility.
One potential limitation of the study is the use of the MIMIC III dataset, which may not be representative of all healthcare settings or patient populations. Additionally, the study focused on generating synthetic notes, but did not explore the use of these notes in actual clinical or research settings.
Further research could investigate the practical implications of using these synthetic notes, such as how they are received by healthcare providers or researchers, and whether they truly provide the same level of utility as real patient data. There may also be opportunities to explore other approaches to enhancing both privacy and utility, such as the use of differential privacy or other advanced privacy-preserving techniques.
Overall, this study represents an important step forward in the use of large language models for clinical data management and highlights the need for continued research in this area to ensure that patient privacy is protected while still enabling valuable medical research and advancements.
Conclusion
This study demonstrates the potential of integrating EHRs, NLP, and large language models to generate synthetic patient notes that can be used for biomedical research, while protecting patient privacy. The results suggest that keyword-based generation methods may be more effective at balancing data utility and privacy protection compared to one-shot generation approaches.
The study also highlights the importance of considering the trade-offs between data utility and privacy, and the potential for methods that enhance both, such as using dummy PHIs, to transform clinical data-sharing practices. As large language models continue to advance, this research provides valuable insights into how these powerful tools can be leveraged to improve healthcare data management and patient care, while respecting the privacy and security of sensitive medical information.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Robust Privacy Amidst Innovation with Large Language Models Through a Critical Assessment of the Risks
Yao-Shun Chuang, Atiquer Rahman Sarkar, Yu-Chun Hsu, Noman Mohammed, Xiaoqian Jiang
This study examines integrating EHRs and NLP with large language models (LLMs) to improve healthcare data management and patient care. It focuses on using advanced models to create secure, HIPAA-compliant synthetic patient notes for biomedical research. The study used de-identified and re-identified MIMIC III datasets with GPT-3.5, GPT-4, and Mistral 7B to generate synthetic notes. Text generation employed templates and keyword extraction for contextually relevant notes, with one-shot generation for comparison. Privacy assessment checked PHI occurrence, while text utility was tested using an ICD-9 coding task. Text quality was evaluated with ROUGE and cosine similarity metrics to measure semantic similarity with source notes. Analysis of PHI occurrence and text utility via the ICD-9 coding task showed that the keyword-based method had low risk and good performance. One-shot generation showed the highest PHI exposure and PHI co-occurrence, especially in geographic location and date categories. The Normalized One-shot method achieved the highest classification accuracy. Privacy analysis revealed a critical balance between data utility and privacy protection, influencing future data use and sharing. Re-identified data consistently outperformed de-identified data. This study demonstrates the effectiveness of keyword-based methods in generating privacy-protecting synthetic clinical notes that retain data usability, potentially transforming clinical data-sharing practices. The superior performance of re-identified over de-identified data suggests a shift towards methods that enhance utility and privacy by using dummy PHIs to perplex privacy attacks.
Read more9/17/2024
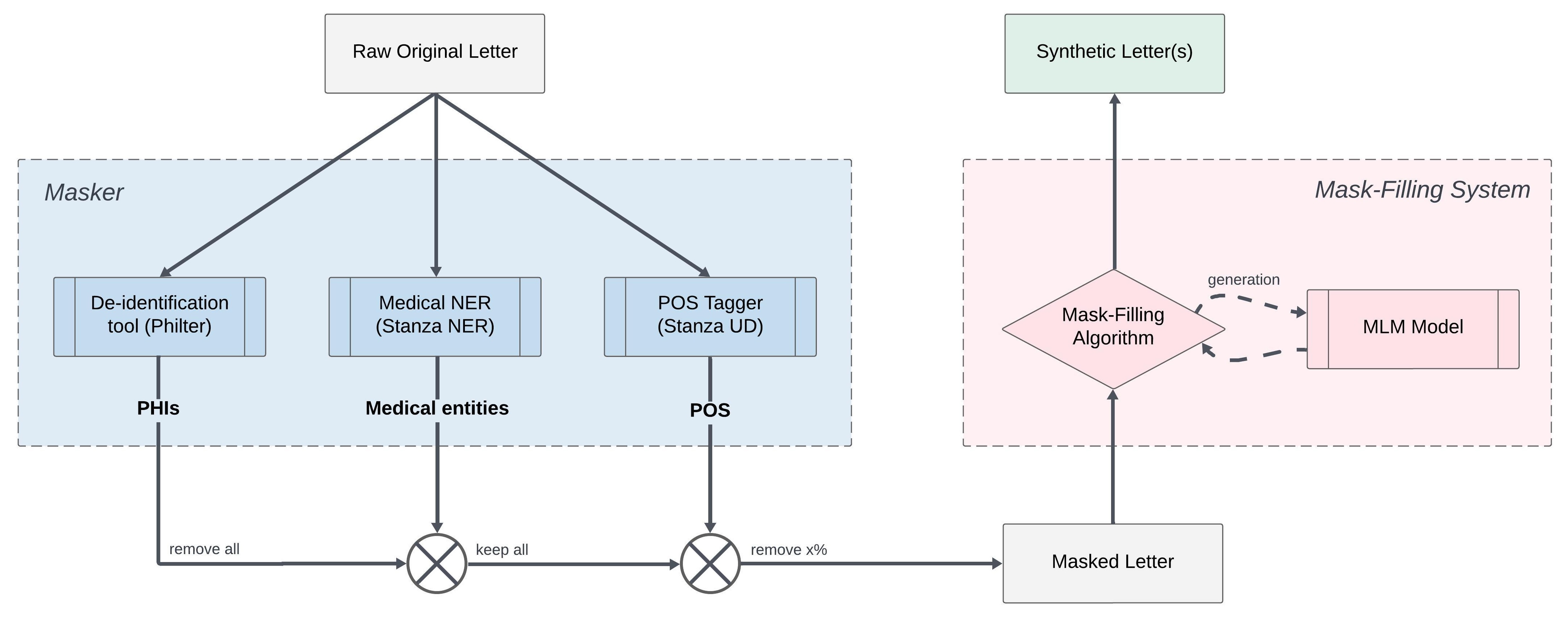
0
New!Generating Synthetic Free-text Medical Records with Low Re-identification Risk using Masked Language Modeling
Samuel Belkadi, Libo Ren, Nicolo Micheletti, Lifeng Han, Goran Nenadic
In this paper, we present a system that generates synthetic free-text medical records, such as discharge summaries, admission notes and doctor correspondences, using Masked Language Modeling (MLM). Our system is designed to preserve the critical information of the records while introducing significant diversity and minimizing re-identification risk. The system incorporates a de-identification component that uses Philter to mask Protected Health Information (PHI), followed by a Medical Entity Recognition (NER) model to retain key medical information. We explore various masking ratios and mask-filling techniques to balance the trade-off between diversity and fidelity in the synthetic outputs without affecting overall readability. Our results demonstrate that the system can produce high-quality synthetic data with significant diversity while achieving a HIPAA-compliant PHI recall rate of 0.96 and a low re-identification risk of 0.035. Furthermore, downstream evaluations using a NER task reveal that the synthetic data can be effectively used to train models with performance comparable to those trained on real data. The flexibility of the system allows it to be adapted for specific use cases, making it a valuable tool for privacy-preserving data generation in medical research and healthcare applications.
Read more9/17/2024

0
Controllable Synthetic Clinical Note Generation with Privacy Guarantees
Tal Baumel (Ari), Andre Manoel (Ari), Daniel Jones (Ari), Shize Su (Ari), Huseyin Inan (Ari), Aaron (Ari), Bornstein, Robert Sim
In the field of machine learning, domain-specific annotated data is an invaluable resource for training effective models. However, in the medical domain, this data often includes Personal Health Information (PHI), raising significant privacy concerns. The stringent regulations surrounding PHI limit the availability and sharing of medical datasets, which poses a substantial challenge for researchers and practitioners aiming to develop advanced machine learning models. In this paper, we introduce a novel method to clone datasets containing PHI. Our approach ensures that the cloned datasets retain the essential characteristics and utility of the original data without compromising patient privacy. By leveraging differential-privacy techniques and a novel fine-tuning task, our method produces datasets that are free from identifiable information while preserving the statistical properties necessary for model training. We conduct utility testing to evaluate the performance of machine learning models trained on the cloned datasets. The results demonstrate that our cloned datasets not only uphold privacy standards but also enhance model performance compared to those trained on traditional anonymized datasets. This work offers a viable solution for the ethical and effective utilization of sensitive medical data in machine learning, facilitating progress in medical research and the development of robust predictive models.
Read more9/14/2024

0
Unlocking the Potential of Large Language Models for Clinical Text Anonymization: A Comparative Study
David Pissarra, Isabel Curioso, Jo~ao Alveira, Duarte Pereira, Bruno Ribeiro, Tom'as Souper, Vasco Gomes, Andr'e V. Carreiro, Vitor Rolla
Automated clinical text anonymization has the potential to unlock the widespread sharing of textual health data for secondary usage while assuring patient privacy and safety. Despite the proposal of many complex and theoretically successful anonymization solutions in literature, these techniques remain flawed. As such, clinical institutions are still reluctant to apply them for open access to their data. Recent advances in developing Large Language Models (LLMs) pose a promising opportunity to further the field, given their capability to perform various tasks. This paper proposes six new evaluation metrics tailored to the challenges of generative anonymization with LLMs. Moreover, we present a comparative study of LLM-based methods, testing them against two baseline techniques. Our results establish LLM-based models as a reliable alternative to common approaches, paving the way toward trustworthy anonymization of clinical text.
Read more6/4/2024