Robustness of Speech Separation Models for Similar-pitch Speakers

0

Sign in to get full access
Overview
- Examines the robustness of speech separation models when dealing with similar-pitch speakers
- Explores the challenges of separating voices with comparable fundamental frequencies
- Proposes methods to improve model performance in these challenging scenarios
Plain English Explanation
Speech separation models aim to isolate individual voices from a mixed audio signal. This is a crucial task for many applications, such as voice assistants and hearing aids. However, when the speakers have similar pitch, the models can struggle to separate the voices accurately.
This paper explores ways to improve the robustness of speech separation models in scenarios where the speakers have similar fundamental frequencies. The researchers propose novel techniques and evaluate their effectiveness through experiments. By addressing this challenge, the research aims to enhance the performance of speech separation systems in real-world situations where similar-pitch speakers are common.
Technical Explanation
The paper investigates the robustness of state-of-the-art speech separation models when dealing with speakers who have similar pitch characteristics. The researchers conduct experiments using both simulated and real-world data to assess the models' ability to separate voices in these challenging scenarios.
To improve performance, the paper proposes several novel techniques, including:
- Multi-scale Spectral Representation: A method that captures spectral details at different resolutions to better distinguish between similar-pitch speakers.
- Adversarial Training: A technique that trains the model to be more robust to variations in speaker pitch and timbre.
- Auxiliary Speaker Pitch Prediction: An additional network component that predicts the pitch of each speaker, providing the main separation model with valuable information.
The researchers evaluate these approaches on a range of benchmark datasets and report significant improvements in separation performance, especially for scenarios with similar-pitch speakers.
Critical Analysis
The paper acknowledges the limitations of the proposed techniques, noting that they may not be as effective in scenarios with more than two speakers or when the speakers' characteristics are highly variable. Additionally, the authors suggest that further research is needed to explore the generalization of these methods to more diverse and challenging audio environments.
While the paper presents promising results, it would be valuable to see the techniques evaluated on a wider range of data, including more real-world recordings, to better understand their practical implications. Additionally, a more in-depth analysis of the model's internal representations and decision-making processes could provide deeper insights into the factors influencing its performance.
Conclusion
This paper tackles the important challenge of improving the robustness of speech separation models when dealing with similar-pitch speakers. The proposed techniques, including multi-scale spectral representation, adversarial training, and auxiliary speaker pitch prediction, demonstrate significant improvements in separation performance. By addressing this critical issue, the research contributes to the advancement of speech separation technology, which has important applications in voice assistants, hearing aids, and other audio-based systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Robustness of Speech Separation Models for Similar-pitch Speakers
Bunlong Lay, Sebastian Zaczek, Kristina Tesch, Timo Gerkmann
Single-channel speech separation is a crucial task for enhancing speech recognition systems in multi-speaker environments. This paper investigates the robustness of state-of-the-art Neural Network models in scenarios where the pitch differences between speakers are minimal. Building on earlier findings by Ditter and Gerkmann, which identified a significant performance drop for the 2018 Chimera++ under similar-pitch conditions, our study extends the analysis to more recent and sophisticated Neural Network models. Our experiments reveal that modern models have substantially reduced the performance gap for matched training and testing conditions. However, a substantial performance gap persists under mismatched conditions, with models performing well for large pitch differences but showing worse performance if the speakers' pitches are similar. These findings motivate further research into the generalizability of speech separation models to similar-pitch speakers and unseen data.
Read more7/23/2024

0
Improving Generalization of Speech Separation in Real-World Scenarios: Strategies in Simulation, Optimization, and Evaluation
Ke Chen, Jiaqi Su, Taylor Berg-Kirkpatrick, Shlomo Dubnov, Zeyu Jin
Achieving robust speech separation for overlapping speakers in various acoustic environments with noise and reverberation remains an open challenge. Although existing datasets are available to train separators for specific scenarios, they do not effectively generalize across diverse real-world scenarios. In this paper, we present a novel data simulation pipeline that produces diverse training data from a range of acoustic environments and content, and propose new training paradigms to improve quality of a general speech separation model. Specifically, we first introduce AC-SIM, a data simulation pipeline that incorporates broad variations in both content and acoustics. Then we integrate multiple training objectives into the permutation invariant training (PIT) to enhance separation quality and generalization of the trained model. Finally, we conduct comprehensive objective and human listening experiments across separation architectures and benchmarks to validate our methods, demonstrating substantial improvement of generalization on both non-homologous and real-world test sets.
Read more8/30/2024
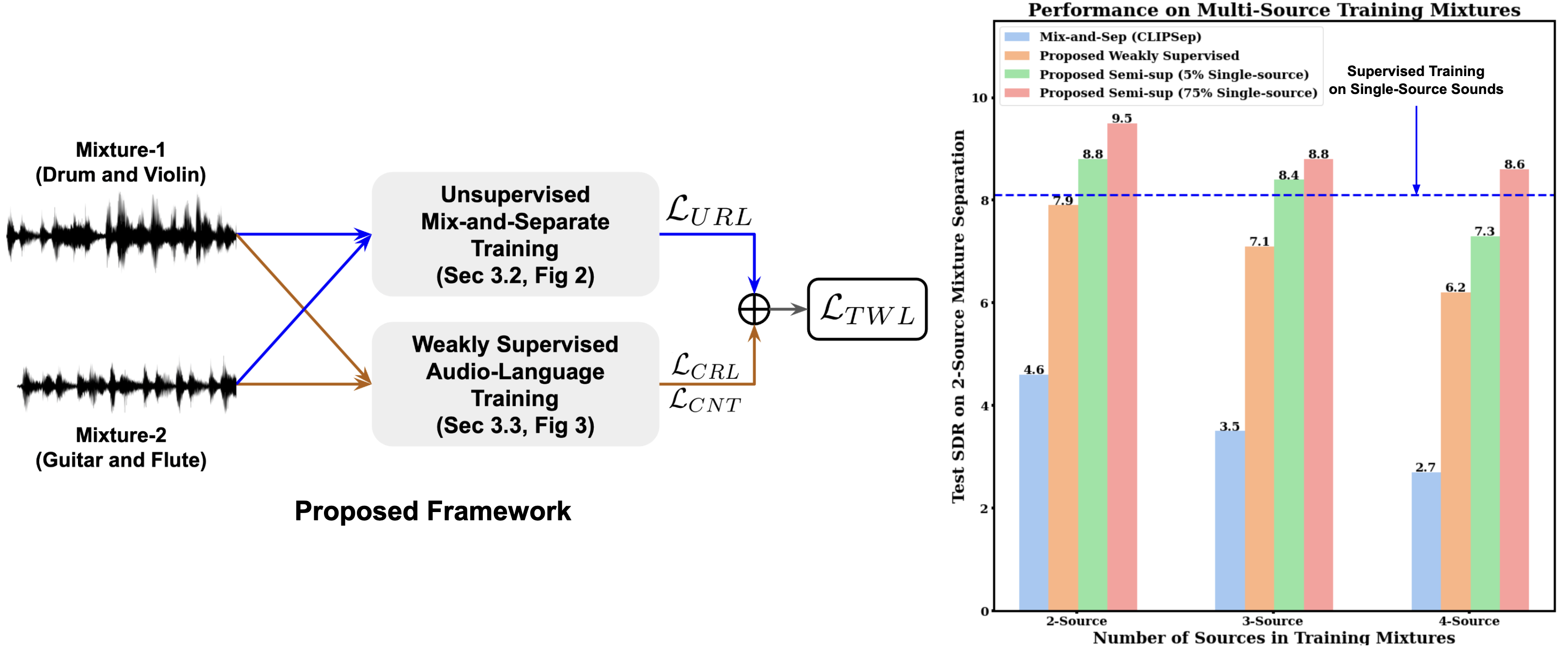
0
Weakly-supervised Audio Separation via Bi-modal Semantic Similarity
Tanvir Mahmud, Saeed Amizadeh, Kazuhito Koishida, Diana Marculescu
Conditional sound separation in multi-source audio mixtures without having access to single source sound data during training is a long standing challenge. Existing mix-and-separate based methods suffer from significant performance drop with multi-source training mixtures due to the lack of supervision signal for single source separation cases during training. However, in the case of language-conditional audio separation, we do have access to corresponding text descriptions for each audio mixture in our training data, which can be seen as (rough) representations of the audio samples in the language modality. To this end, in this paper, we propose a generic bi-modal separation framework which can enhance the existing unsupervised frameworks to separate single-source signals in a target modality (i.e., audio) using the easily separable corresponding signals in the conditioning modality (i.e., language), without having access to single-source samples in the target modality during training. We empirically show that this is well within reach if we have access to a pretrained joint embedding model between the two modalities (i.e., CLAP). Furthermore, we propose to incorporate our framework into two fundamental scenarios to enhance separation performance. First, we show that our proposed methodology significantly improves the performance of purely unsupervised baselines by reducing the distribution shift between training and test samples. In particular, we show that our framework can achieve 71% boost in terms of Signal-to-Distortion Ratio (SDR) over the baseline, reaching 97.5% of the supervised learning performance. Second, we show that we can further improve the performance of the supervised learning itself by 17% if we augment it by our proposed weakly-supervised framework, that enables a powerful semi-supervised framework for audio separation.
Read more4/3/2024

0
Transcription-Free Fine-Tuning of Speech Separation Models for Noisy and Reverberant Multi-Speaker Automatic Speech Recognition
William Ravenscroft, George Close, Stefan Goetze, Thomas Hain, Mohammad Soleymanpour, Anurag Chowdhury, Mark C. Fuhs
One solution to automatic speech recognition (ASR) of overlapping speakers is to separate speech and then perform ASR on the separated signals. Commonly, the separator produces artefacts which often degrade ASR performance. Addressing this issue typically requires reference transcriptions to jointly train the separation and ASR networks. This is often not viable for training on real-world in-domain audio where reference transcript information is not always available. This paper proposes a transcription-free method for joint training using only audio signals. The proposed method uses embedding differences of pre-trained ASR encoders as a loss with a proposed modification to permutation invariant training (PIT) called guided PIT (GPIT). The method achieves a 6.4% improvement in word error rate (WER) measures over a signal-level loss and also shows enhancement improvements in perceptual measures such as short-time objective intelligibility (STOI).
Read more6/14/2024