RTMO: Towards High-Performance One-Stage Real-Time Multi-Person Pose Estimation

0

Sign in to get full access
Overview
- The paper proposes a new one-stage real-time multi-person pose estimation model called RTMO (Real-Time Multi-Object) that achieves high performance.
- It addresses the challenges of accurately detecting and localizing multiple people in real-time using a single-stage architecture.
- The model outperforms state-of-the-art methods on several benchmark datasets while maintaining real-time inference speed.
Plain English Explanation
The paper introduces a new artificial intelligence (AI) system called RTMO (Real-Time Multi-Object) that can quickly and accurately detect and locate multiple people in an image or video. This is an important task in computer vision, with applications in areas like surveillance, robotics, and sports analytics.
Existing methods for this task often struggle to balance accuracy and speed, especially when dealing with multiple people in a single frame. RTMO's one-stage architecture allows it to perform detection and pose estimation in a single pass, making it very efficient and able to run in real-time.
The researchers tested RTMO on standard benchmark datasets and found that it outperforms other state-of-the-art object detection and human pose estimation models, while still maintaining fast inference speeds. This suggests RTMO could be a valuable tool for applications that require accurate and responsive multi-person tracking, like surveillance systems or sports analytics.
Technical Explanation
The core of RTMO is a one-stage pose estimation architecture that combines object detection and pose estimation into a single model. This allows it to efficiently locate and estimate the poses of multiple people in an image or video frame.
The model uses a backbone convolutional neural network to extract visual features from the input, which are then fed into parallel detection and pose estimation heads. The detection head predicts bounding boxes and object classifications, while the pose estimation head regresses the 2D coordinates of key body joints for each detected person.
To handle occlusions and overlapping people, RTMO introduces several novel techniques, including surface-based 4D motion modeling and a decoupled regression approach for pose estimation. These allow the model to more accurately localize and estimate the poses of individuals, even in cluttered scenes.
The researchers evaluate RTMO on challenging multi-person pose estimation benchmarks like COCO and PoseTrack, demonstrating state-of-the-art performance while maintaining real-time inference speeds. This suggests the model could be a valuable tool for applications that require accurate and responsive multi-person tracking, such as video-based human pose regression.
Critical Analysis
The paper provides a thorough evaluation of RTMO's performance, including comparisons to other leading methods on standard benchmarks. The results are impressive, showing that RTMO can achieve high accuracy while running in real-time, a significant feat for a one-stage multi-person pose estimation model.
That said, the paper does not delve deeply into the limitations or potential issues with the approach. For example, it would be helpful to understand how RTMO handles extreme occlusions or very small/large people in the scene, as these can be challenging cases for pose estimation.
Additionally, the paper does not discuss potential biases or fairness concerns that may arise from the training data or model architecture. As pose estimation systems are deployed in real-world applications, it will be crucial to ensure they work equally well for people of diverse backgrounds and body types.
Overall, the research represents an important advance in the field of real-time multi-person pose estimation. However, further investigation into the model's robustness and potential limitations would help provide a more comprehensive understanding of its capabilities and suitability for different real-world use cases.
Conclusion
The RTMO model proposed in this paper demonstrates impressive performance in real-time multi-person pose estimation, outperforming state-of-the-art methods on benchmark datasets. Its efficient one-stage architecture allows for fast and accurate detection and localization of multiple individuals in a single pass, making it a promising tool for applications that require responsive and reliable human tracking, such as surveillance, robotics, and sports analytics.
While the paper provides a strong technical evaluation of RTMO, further research is needed to fully understand its limitations and potential biases. Nonetheless, this work represents an important advancement in the field of computer vision and has the potential to enable new capabilities in a variety of real-world domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RTMO: Towards High-Performance One-Stage Real-Time Multi-Person Pose Estimation
Peng Lu, Tao Jiang, Yining Li, Xiangtai Li, Kai Chen, Wenming Yang
Real-time multi-person pose estimation presents significant challenges in balancing speed and precision. While two-stage top-down methods slow down as the number of people in the image increases, existing one-stage methods often fail to simultaneously deliver high accuracy and real-time performance. This paper introduces RTMO, a one-stage pose estimation framework that seamlessly integrates coordinate classification by representing keypoints using dual 1-D heatmaps within the YOLO architecture, achieving accuracy comparable to top-down methods while maintaining high speed. We propose a dynamic coordinate classifier and a tailored loss function for heatmap learning, specifically designed to address the incompatibilities between coordinate classification and dense prediction models. RTMO outperforms state-of-the-art one-stage pose estimators, achieving 1.1% higher AP on COCO while operating about 9 times faster with the same backbone. Our largest model, RTMO-l, attains 74.8% AP on COCO val2017 and 141 FPS on a single V100 GPU, demonstrating its efficiency and accuracy. The code and models are available at https://github.com/open-mmlab/mmpose/tree/main/projects/rtmo.
Read more4/9/2024

0
RTMW: Real-Time Multi-Person 2D and 3D Whole-body Pose Estimation
Tao Jiang, Xinchen Xie, Yining Li
Whole-body pose estimation is a challenging task that requires simultaneous prediction of keypoints for the body, hands, face, and feet. Whole-body pose estimation aims to predict fine-grained pose information for the human body, including the face, torso, hands, and feet, which plays an important role in the study of human-centric perception and generation and in various applications. In this work, we present RTMW (Real-Time Multi-person Whole-body pose estimation models), a series of high-performance models for 2D/3D whole-body pose estimation. We incorporate RTMPose model architecture with FPN and HEM (Hierarchical Encoding Module) to better capture pose information from different body parts with various scales. The model is trained with a rich collection of open-source human keypoint datasets with manually aligned annotations and further enhanced via a two-stage distillation strategy. RTMW demonstrates strong performance on multiple whole-body pose estimation benchmarks while maintaining high inference efficiency and deployment friendliness. We release three sizes: m/l/x, with RTMW-l achieving a 70.2 mAP on the COCO-Wholebody benchmark, making it the first open-source model to exceed 70 mAP on this benchmark. Meanwhile, we explored the performance of RTMW in the task of 3D whole-body pose estimation, conducting image-based monocular 3D whole-body pose estimation in a coordinate classification manner. We hope this work can benefit both academic research and industrial applications. The code and models have been made publicly available at: https://github.com/open-mmlab/mmpose/tree/main/projects/rtmpose
Read more7/12/2024
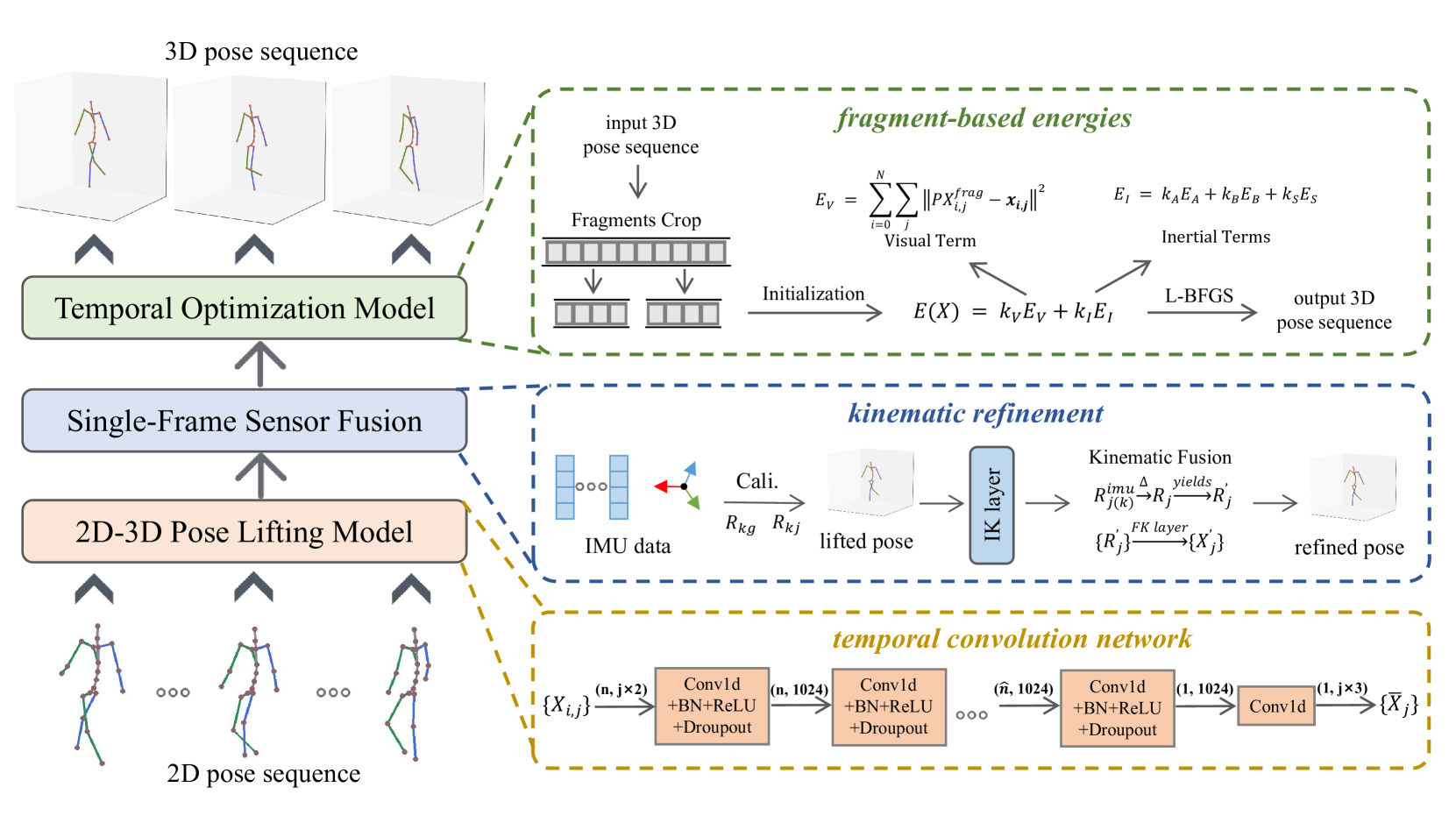
0
Hybrid 3D Human Pose Estimation with Monocular Video and Sparse IMUs
Yiming Bao, Xu Zhao, Dahong Qian
Temporal 3D human pose estimation from monocular videos is a challenging task in human-centered computer vision due to the depth ambiguity of 2D-to-3D lifting. To improve accuracy and address occlusion issues, inertial sensor has been introduced to provide complementary source of information. However, it remains challenging to integrate heterogeneous sensor data for producing physically rational 3D human poses. In this paper, we propose a novel framework, Real-time Optimization and Fusion (RTOF), to address this issue. We first incorporate sparse inertial orientations into a parametric human skeleton to refine 3D poses in kinematics. The poses are then optimized by energy functions built on both visual and inertial observations to reduce the temporal jitters. Our framework outputs smooth and biomechanically plausible human motion. Comprehensive experiments with ablation studies demonstrate its rationality and efficiency. On Total Capture dataset, the pose estimation error is significantly decreased compared to the baseline method.
Read more4/30/2024
0
FastPoseCNN: Real-Time Monocular Category-Level Pose and Size Estimation Framework
Eduardo Davalos, Mehran Aminian
The primary focus of this paper is the development of a framework for pose and size estimation of unseen objects given a single RGB image - all in real-time. In 2019, the first category-level pose and size estimation framework was proposed alongside two novel datasets called CAMERA and REAL. However, current methodologies are restricted from practical use because of its long inference time (2-4 fps). Their approach's inference had significant delays because they used the computationally expensive MaskedRCNN framework and Umeyama algorithm. To optimize our method and yield real-time results, our framework uses the efficient ResNet-FPN framework alongside decoupling the translation, rotation, and size regression problem by using distinct decoders. Moreover, our methodology performs pose and size estimation in a global context - i.e., estimating the involved parameters of all captured objects in the image all at once. We perform extensive testing to fully compare the performance in terms of precision and speed to demonstrate the capability of our method.
Read more6/18/2024