RuleAlign: Making Large Language Models Better Physicians with Diagnostic Rule Alignment

0
💬
Sign in to get full access
Overview
- Large language models (LLMs) like GPT-4, MedPaLM-2, and Med-Gemini can perform competitively with human experts on various medical benchmarks.
- However, they still face challenges in effectively gathering patient information and reasoning to make professional-level diagnoses like physicians.
- To address this, the researchers introduce the RuleAlign framework, which aims to align LLMs with specific diagnostic rules.
- They develop a medical dialogue dataset and design an alignment learning approach through preference learning.
- The experimental results demonstrate the effectiveness of the proposed approach.
Plain English Explanation
The paper discusses how large language models (LLMs) like GPT-4, MedPaLM-2, and Med-Gemini have made impressive strides in medical performance, matching or even surpassing human experts on various benchmarks. However, these models still struggle with some key aspects of the diagnostic process, such as efficiently gathering relevant information from patients and using that information to arrive at a final diagnosis, just as a human physician would.
To address these challenges, the researchers introduced a new framework called RuleAlign. The core idea behind RuleAlign is to "align" the LLMs with specific diagnostic rules and protocols that doctors use in their practice. To do this, the researchers developed a dataset of medical dialogues that simulate the back-and-forth between patients and physicians, with the conversations structured around these diagnostic rules.
Using this dataset, the researchers then designed a machine learning approach called "preference learning" to train the LLMs to follow the same decision-making logic as human doctors when it comes to diagnosing patients. The results of their experiments showed that this approach was effective in improving the LLMs' diagnostic capabilities.
The researchers hope that their work will inspire further exploration into the potential of LLMs to serve as "AI physicians" that can assist or even replace human doctors in certain medical tasks. By aligning these powerful language models with the established best practices of the medical field, the aim is to unlock their full potential in healthcare applications.
Technical Explanation
The researchers recognized that while large language models (LLMs) like GPT-4, MedPaLM-2, and Med-Gemini have demonstrated competitive performance with human experts across various medical benchmarks, they still face significant challenges in making professional-level diagnoses akin to physicians. Specifically, the models struggle with efficiently gathering relevant patient information and reasoning through the full diagnostic process to arrive at a final diagnosis.
To address these limitations, the researchers introduced the RuleAlign framework. The core idea behind RuleAlign is to align the LLMs with specific diagnostic rules and protocols used by physicians in their practice. To facilitate this, the researchers developed a medical dialogue dataset that simulates the back-and-forth communication between patients and doctors, with the conversations structured around these diagnostic rules.
The researchers then designed an alignment learning approach through preference learning to train the LLMs to follow the same decision-making logic as human doctors when it comes to diagnosing patients. Experimental results demonstrated the effectiveness of the proposed RuleAlign framework in improving the diagnostic capabilities of the language models.
Critical Analysis
The researchers acknowledge that while their RuleAlign framework shows promise in aligning LLMs with medical diagnostic rules, there are still limitations and areas for further research. For example, the dataset used in the study may not fully capture the complexity and nuance of real-world medical dialogues, and the preference learning approach may not be the only or even the best way to achieve the desired alignment.
Additionally, the paper does not address the potential ethical and fairness implications of deploying LLMs in high-stakes medical decision-making, such as the risk of introducing biases or making mistakes that could have serious consequences for patients.
Further research could explore alternative approaches to aligning LLMs with medical best practices, as well as more comprehensive evaluations of the models' performance and safety in real-world clinical settings. It's important to carefully consider the limitations and potential risks before deploying these technologies in critical healthcare applications.
Conclusion
The researchers' introduction of the RuleAlign framework represents an important step towards leveraging the power of large language models for medical diagnosis and decision-making. By aligning these models with established diagnostic rules and protocols, the aim is to unlock their potential as "AI physicians" that can assist or even replace human doctors in certain tasks.
While the experimental results are promising, there are still significant challenges and areas for further research to ensure the safe and ethical deployment of these technologies in healthcare. Nonetheless, the researchers' work serves as an inspiration for continued exploration into the use of advanced language models in the medical field, with the ultimate goal of improving patient outcomes and enhancing the overall quality of healthcare.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
RuleAlign: Making Large Language Models Better Physicians with Diagnostic Rule Alignment
Xiaohan Wang, Xiaoyan Yang, Yuqi Zhu, Yue Shen, Jian Wang, Peng Wei, Lei Liang, Jinjie Gu, Huajun Chen, Ningyu Zhang
Large Language Models (LLMs) like GPT-4, MedPaLM-2, and Med-Gemini achieve performance competitively with human experts across various medical benchmarks. However, they still face challenges in making professional diagnoses akin to physicians, particularly in efficiently gathering patient information and reasoning the final diagnosis. To this end, we introduce the RuleAlign framework, designed to align LLMs with specific diagnostic rules. We develop a medical dialogue dataset comprising rule-based communications between patients and physicians and design an alignment learning approach through preference learning. Experimental results demonstrate the effectiveness of the proposed approach. We hope that our work can serve as an inspiration for exploring the potential of LLMs as AI physicians.
Read more8/23/2024
💬
0
Digital Diagnostics: The Potential Of Large Language Models In Recognizing Symptoms Of Common Illnesses
Gaurav Kumar Gupta, Aditi Singh, Sijo Valayakkad Manikandan, Abul Ehtesham
The recent swift development of LLMs like GPT-4, Gemini, and GPT-3.5 offers a transformative opportunity in medicine and healthcare, especially in digital diagnostics. This study evaluates each model diagnostic abilities by interpreting a user symptoms and determining diagnoses that fit well with common illnesses, and it demonstrates how each of these models could significantly increase diagnostic accuracy and efficiency. Through a series of diagnostic prompts based on symptoms from medical databases, GPT-4 demonstrates higher diagnostic accuracy from its deep and complete history of training on medical data. Meanwhile, Gemini performs with high precision as a critical tool in disease triage, demonstrating its potential to be a reliable model when physicians are trying to make high-risk diagnoses. GPT-3.5, though slightly less advanced, is a good tool for medical diagnostics. This study highlights the need to study LLMs for healthcare and clinical practices with more care and attention, ensuring that any system utilizing LLMs promotes patient privacy and complies with health information privacy laws such as HIPAA compliance, as well as the social consequences that affect the varied individuals in complex healthcare contexts. This study marks the start of a larger future effort to study the various ways in which assigning ethical concerns to LLMs task of learning from human biases could unearth new ways to apply AI in complex medical settings.
Read more5/14/2024

0
A Survey on Large Language Models from General Purpose to Medical Applications: Datasets, Methodologies, and Evaluations
Jinqiang Wang, Huansheng Ning, Yi Peng, Qikai Wei, Daniel Tesfai, Wenwei Mao, Tao Zhu, Runhe Huang
Large Language Models (LLMs) have demonstrated surprising performance across various natural language processing tasks. Recently, medical LLMs enhanced with domain-specific knowledge have exhibited excellent capabilities in medical consultation and diagnosis. These models can smoothly simulate doctor-patient dialogues and provide professional medical advice. Most medical LLMs are developed through continued training of open-source general LLMs, which require significantly fewer computational resources than training LLMs from scratch. Additionally, this approach offers better protection of patient privacy compared to API-based solutions. This survey systematically explores how to train medical LLMs based on general LLMs. It covers: (a) how to acquire training corpus and construct customized medical training sets, (b) how to choose a appropriate training paradigm, (c) how to choose a suitable evaluation benchmark, and (d) existing challenges and promising future research directions are discussed. This survey can provide guidance for the development of LLMs focused on various medical applications, such as medical education, diagnostic planning, and clinical assistants.
Read more6/18/2024
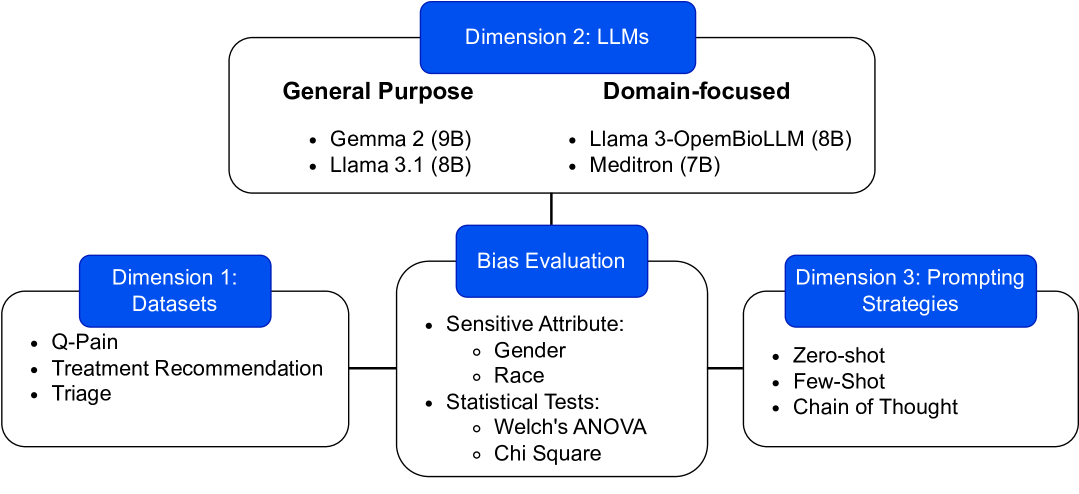
0
Aligning (Medical) LLMs for (Counterfactual) Fairness
Raphael Poulain, Hamed Fayyaz, Rahmatollah Beheshti
Large Language Models (LLMs) have emerged as promising solutions for a variety of medical and clinical decision support applications. However, LLMs are often subject to different types of biases, which can lead to unfair treatment of individuals, worsening health disparities, and reducing trust in AI-augmented medical tools. Aiming to address this important issue, in this study, we present a new model alignment approach for aligning LLMs using a preference optimization method within a knowledge distillation framework. Prior to presenting our proposed method, we first use an evaluation framework to conduct a comprehensive (largest to our knowledge) empirical evaluation to reveal the type and nature of existing biases in LLMs used for medical applications. We then offer a bias mitigation technique to reduce the unfair patterns in LLM outputs across different subgroups identified by the protected attributes. We show that our mitigation method is effective in significantly reducing observed biased patterns. Our code is publicly available at url{https://github.com/healthylaife/FairAlignmentLLM}.
Read more8/23/2024