DiReCT: Diagnostic Reasoning for Clinical Notes via Large Language Models

0
Sign in to get full access
Overview
- The paper proposes DiReCT, a framework for using large language models to assist with diagnostic reasoning in clinical settings.
- DiReCT aims to help clinicians by generating differential diagnoses and explanations for clinical notes.
- The framework uses language models fine-tuned on medical data to understand clinical text and make diagnostic inferences.
Plain English Explanation
The researchers have developed a system called DiReCT that uses large language models to help doctors with the process of making medical diagnoses. When a doctor writes up notes about a patient's symptoms and medical history, DiReCT can analyze that text and suggest a list of possible conditions that could be causing the patient's issues. It also provides an explanation for why it thinks those conditions might be the cause.
This could be very helpful for busy clinicians, as making an accurate diagnosis can be challenging, especially for complex or rare medical problems. By having an AI system quickly analyze the clinical notes and provide some initial diagnostic ideas, doctors can save time and potentially catch things they might have missed. The language models used in DiReCT have been specially trained on large amounts of medical data, so they have a deep understanding of health conditions and how they relate to symptoms.
Technical Explanation
The DiReCT framework works by first taking in a clinical note written by a healthcare provider. It then uses a large language model that has been fine-tuned on medical data to encode the text and extract relevant medical concepts.
Next, DiReCT generates a list of potential differential diagnoses by prompting the language model to "Provide a differential diagnosis for the following clinical presentation." The model then produces a ranked list of condition names that could explain the patient's symptoms and medical history.
To provide explanations for each suggested diagnosis, the framework employs a dual inference approach that generates both a textual rationale and a set of supporting evidence from the input clinical note. This allows clinicians to understand the reasoning behind each diagnostic hypothesis.
The researchers evaluated DiReCT on real-world clinical notes and found that it was able to surface relevant differential diagnoses and generate informative explanations to support the clinical reasoning process.
Critical Analysis
The paper provides a compelling demonstration of how large language models can be leveraged to assist clinical decision-making. By fine-tuning the models on medical data and designing a framework to generate differential diagnoses and explanations, the researchers have shown the potential for AI to augment the diagnostic expertise of human clinicians.
However, the authors also acknowledge some key limitations of the current work. For example, the system is dependent on the quality and completeness of the input clinical notes, and may struggle with notes that lack important details. There are also concerns about potential biases in the training data used to fine-tune the language models.
Additionally, the paper does not address the critical issue of model interpretability - while the explanations provided by DiReCT are intended to be interpretable, the inner workings of the language model itself remain a 'black box' that could be difficult for clinicians to fully understand and trust.
Further research is needed to address these limitations and ensure the safe and effective deployment of such AI-powered diagnostic tools in real-world clinical settings.
Conclusion
The DiReCT framework represents an important step forward in leveraging large language models to assist clinical reasoning and decision-making. By generating differential diagnoses and providing explanatory rationales, the system has the potential to help overburdened clinicians work more efficiently and effectively.
However, the research also highlights the need for continued development and validation to address concerns around data quality, model biases, and interpretability. As the field of medical AI continues to advance, it will be crucial to ensure that these technologies are robustly designed and thoroughly tested before deployment in high-stakes healthcare settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DiReCT: Diagnostic Reasoning for Clinical Notes via Large Language Models
Bowen Wang, Jiuyang Chang, Yiming Qian, Guoxin Chen, Junhao Chen, Zhouqiang Jiang, Jiahao Zhang, Yuta Nakashima, Hajime Nagahara
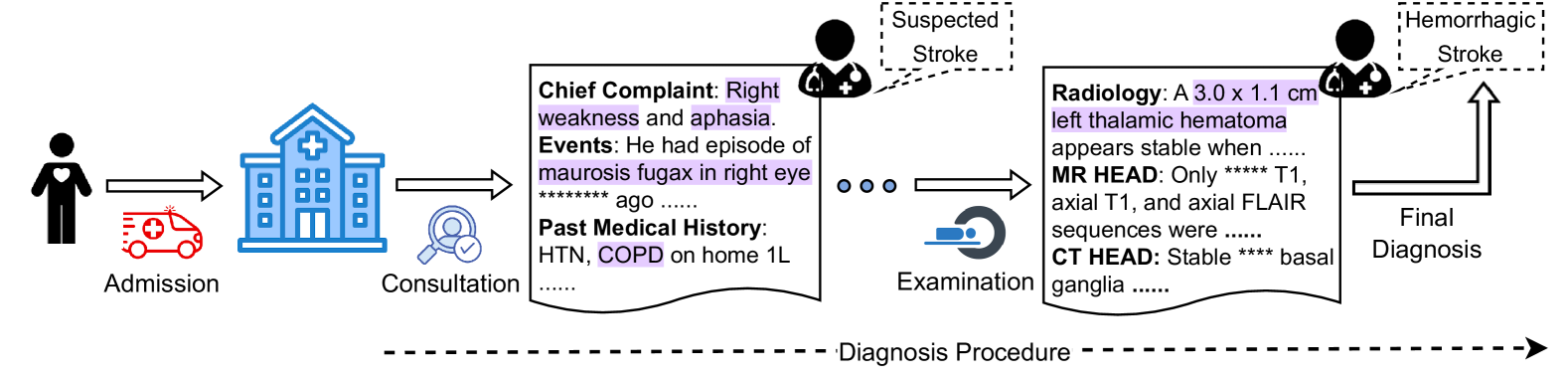
Large language models (LLMs) have recently showcased remarkable capabilities, spanning a wide range of tasks and applications, including those in the medical domain. Models like GPT-4 excel in medical question answering but may face challenges in the lack of interpretability when handling complex tasks in real clinical settings. We thus introduce the diagnostic reasoning dataset for clinical notes (DiReCT), aiming at evaluating the reasoning ability and interpretability of LLMs compared to human doctors. It contains 511 clinical notes, each meticulously annotated by physicians, detailing the diagnostic reasoning process from observations in a clinical note to the final diagnosis. Additionally, a diagnostic knowledge graph is provided to offer essential knowledge for reasoning, which may not be covered in the training data of existing LLMs. Evaluations of leading LLMs on DiReCT bring out a significant gap between their reasoning ability and that of human doctors, highlighting the critical need for models that can reason effectively in real-world clinical scenarios.
Read more8/7/2024

0
Large Language Models are Clinical Reasoners: Reasoning-Aware Diagnosis Framework with Prompt-Generated Rationales
Taeyoon Kwon, Kai Tzu-iunn Ong, Dongjin Kang, Seungjun Moon, Jeong Ryong Lee, Dosik Hwang, Yongsik Sim, Beomseok Sohn, Dongha Lee, Jinyoung Yeo
Machine reasoning has made great progress in recent years owing to large language models (LLMs). In the clinical domain, however, most NLP-driven projects mainly focus on clinical classification or reading comprehension, and under-explore clinical reasoning for disease diagnosis due to the expensive rationale annotation with clinicians. In this work, we present a reasoning-aware diagnosis framework that rationalizes the diagnostic process via prompt-based learning in a time- and labor-efficient manner, and learns to reason over the prompt-generated rationales. Specifically, we address the clinical reasoning for disease diagnosis, where the LLM generates diagnostic rationales providing its insight on presented patient data and the reasoning path towards the diagnosis, namely Clinical Chain-of-Thought (Clinical CoT). We empirically demonstrate LLMs/LMs' ability of clinical reasoning via extensive experiments and analyses on both rationale generation and disease diagnosis in various settings. We further propose a novel set of criteria for evaluating machine-generated rationales' potential for real-world clinical settings, facilitating and benefiting future research in this area.
Read more5/13/2024

0
Diagnostic Reasoning in Natural Language: Computational Model and Application
Nils Dycke, Matej Zev{c}evi'c, Ilia Kuznetsov, Beatrix Suess, Kristian Kersting, Iryna Gurevych
Diagnostic reasoning is a key component of expert work in many domains. It is a hard, time-consuming activity that requires expertise, and AI research has investigated the ways automated systems can support this process. Yet, due to the complexity of natural language, the applications of AI for diagnostic reasoning to language-related tasks are lacking. To close this gap, we investigate diagnostic abductive reasoning (DAR) in the context of language-grounded tasks (NL-DAR). We propose a novel modeling framework for NL-DAR based on Pearl's structural causal models and instantiate it in a comprehensive study of scientific paper assessment in the biomedical domain. We use the resulting dataset to investigate the human decision-making process in NL-DAR and determine the potential of LLMs to support structured decision-making over text. Our framework, open resources and tools lay the groundwork for the empirical study of collaborative diagnostic reasoning in the age of LLMs, in the scholarly domain and beyond.
Read more9/10/2024
💬
0
Guiding Clinical Reasoning with Large Language Models via Knowledge Seeds
Jiageng WU, Xian Wu, Jie Yang
Clinical reasoning refers to the cognitive process that physicians employ in evaluating and managing patients. This process typically involves suggesting necessary examinations, diagnosing patients' diseases, and deciding on appropriate therapies, etc. Accurate clinical reasoning requires extensive medical knowledge and rich clinical experience, setting a high bar for physicians. This is particularly challenging in developing countries due to the overwhelming number of patients and limited physician resources, contributing significantly to global health inequity and necessitating automated clinical reasoning approaches. Recently, the emergence of large language models (LLMs) such as ChatGPT and GPT-4 have demonstrated their potential in clinical reasoning. However, these LLMs are prone to hallucination problems, and the reasoning process of LLMs may not align with the clinical decision path of physicians. In this study, we introduce a novel framework, In-Context Padding (ICP), designed to enhance LLMs with medical knowledge. Specifically, we infer critical clinical reasoning elements (referred to as knowledge seeds) and use these as anchors to guide the generation process of LLMs. Experiments on two clinical question datasets demonstrate that ICP significantly improves the clinical reasoning ability of LLMs.
Read more6/11/2024